When I initially migrated my blog from Medium to Hugo, I used the “easy button” to implement search by using a dynamic script from Google. This worked as a stop gap but bothered me for several reasons. The search script requires dynamic content generation and forced me to compromise security a bit by allowing JavaScript’s eval in my Content Security Policy (CSP - if you’re not familiar with the term, I’ll explain it in a future blog post). It also depends on Google’s snapshot of the website that could be several days old and leave out current results. Finally, it doesn’t work at all in offline mode for the Progressive Web App.
This nagged me so much I set out to find another solution. It turns out it is a common concern for Hugo websites and has been addressed several different ways.
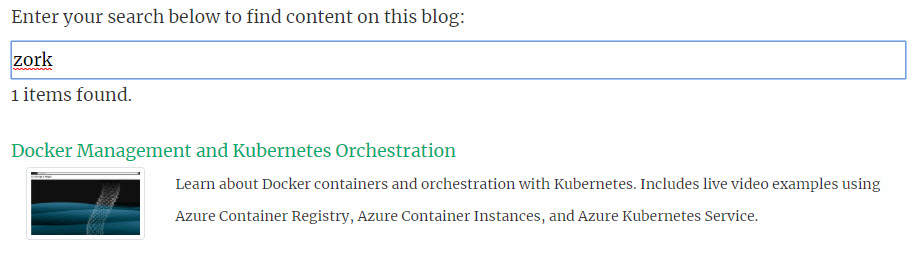
Zork search
This article describes my solution.
Create a Search Database
The first step to dynamically search a static site is to come up with a way to parse search data. This isn’t difficult to do in Hugo. In my config.toml I added the home line to allow an additional format (JSON) for the home page:
[outputs]
home = ["HTML", "RSS", "JSON"]
page = ["HTML", "RSS"]
Under layouts/_default I added an index.json template. This template generates a JSON file with all the site content. It uses a dynamic variable (via the Scratch keyword) to build the objects that represent pages, then outputs the results in JSON.
{{- $.Scratch.Add "index" slice -}}
{{- range .Site.RegularPages -}}
{{- $.Scratch.Add "index" (dict "title" .Title "subtitle" .Params.subtitle "description" .Params.description "tags" .Params.tags "image" .Params.image "content" .Plain "permalink" .Permalink) -}}
{{- end -}}
{{- $.Scratch.Get "index" | jsonify -}}
This generates an array with entries that look like this:
{
"content": "A ton of blah blah here...\n",
"description": "Learn about Jeremy Likness and his 'Developer for Life' blog.",
"image": "/images/jeremymicrosoft.jpg",
"permalink": "http://blog.jeremylikness.com/static/about/",
"subtitle": "Empowering developers to be their best.",
"tags": ["About"],
"title": "About Jeremy Likness and Developer for Life"
}
Although it is “large-ish” (a few megabytes), the size is not unreasonable to download over a slow network or to store and process in memory. If you’re interested, you can view the search JSON here.
A New Short Code
I implemented my original search with short codes for the integration with Google, so I decided to stick with that approach and create another short code for static search and swap out the old codes. The template looks like this inside of shortcodes/staticsearch.html:
{{ partial "_shared/banner.html" . }}
<p id="loading">Loading search data...</p>
<label for="searchBox">Enter your search below to find content on this blog:</label>
<input disabled placeholder="Enter search text" type="text" name="searchBox" id="searchBox" class="w-100"/>
<div id="results"></div>
<script src="{{"/js/search.js" | urlize | relURL }}"></script>
Under static/js I created a search.js script. This script does most of the work.
It is probably a better practice to use a separate page layout for search instead of a short code, as it is only used in one place. This is me being lazy.
Preparing the Index
The first thing I do is load the index. I normalize the content by stripping non alpha-numeric characters and converting everything to lowercase for consistency. The normalizer does most of the work:
var normalizer = document.createElement("textarea");
var normalize = function (input) {
normalizer.innerHTML = input;
var inputDecoded = normalizer.value;
return " " + inputDecoded.trim().toLowerCase()
.replace(/[^0-9a-z ]/gi, " ").replace(/\s+/g, " ") + " ";
}
Wait, what? Why am I creating a textarea element? Since you asked, here’s the answer: the index.json database contains HTML entity codes. Things like « for a leading quote and for a space. The easiest way to decode these is to stuff them into the innerHTML of a textarea then read its value. Try for yourself: it works like a charm. After that, any non-alphanumeric characters are replaced with spaces to create a “word cloud” that can be parsed. (By the way, one nifty side effect of this approach is that you can search on code snippets too … try putting “showDescription” in the search box).
$("#searchBox").hide();
var searchHost = {};
$.getJSON("/index.json", function (results) {
searchHost.index = [];
var dup = {};
results.forEach(function (result) {
if (result.tags && !dup[result.permalink]) {
var res = {};
res.showTitle = result.title;
res.showDescription = result.description;
res.title = normalize(result.title);
res.subtitle = normalize(result.subtitle);
res.description = normalize(result.description);
res.content = normalize(result.content);
var newTags_1 = [];
result.tags.forEach(function (tag) {
return newTags_1.push(normalize(tag));
});
res.tags = newTags_1;
res.permalink = result.permalink;
res.image = result.image;
searchHost.index.push(res);
dup[result.permalink] = true;
}
});
$("#loading").hide();
$("#searchBox").show()
.removeAttr("disabled")
.focus();
initSearch();
});
The dup object holds links to avoid accidentally processing duplicates. I also check for the existence of tags to make sure it is a page I want to be part of the search index. All of my valid blog posts and site pages have associated tags.
I preserve the original title and description for display purposes. Everything is front and back padded with spaces so that I can pad search terms with spaces and thereby find whole words and phrases instead of fragments.
Responding to Search Text
After the index is loaded and normalized, I wire up the search input to respond to key press events.
var initSearch = function () {
$("#searchBox").keyup(function () {
runSearch();
});
};
The runSearch method normalizes the search input and then creates a weighted set of terms.
var runSearch = function () {
if (searching) {
return;
}
var term = normalize($("#searchBox").val()).trim();
if (term.length < minChars) {
$("#results").html('<p>No items found.</p>');
return;
}
searching = true;
$("#results").html('<p>Processing search...</p>');
var terms = term.split(" ");
var termsTree = [];
for (var i = 0; i < terms.length; i += 1) {
for (var j = i; j < terms.length; j += 1) {
var weight = Math.pow(2, j - i);
var str = "";
for (var k = i; k <= j; k += 1) {
str += (terms[k] + " ");
}
var newTerm = str.trim();
if (newTerm.length >= minChars && stopwords.indexOf(newTerm) < 0) {
termsTree.push({
weight: weight,
term: " " + str.trim() + " "
});
}
}
}
search(termsTree);
searching = false;
};
Instead of “debouncing” input, I set a flag to make sure I don’t re-enter the search when a previous search is running. In testing the search runs faster than I can type, but that may not hold true on slower devices. If I get feedback it is off on certain platforms, I’ll revisit.
The algorithm is straightforward. If you type I am Borg a set of weighted phrases is generated like this:
1: i
1: am
1: borg
2: i am
2: am borg
4: i am borg
I toss out short words and anything on my “stop word” list (terms like the that occur too often to be meaningful in search). I don’t mind stop words as part of phrases. The final array ends up looking like this:
1: borg
2: i am
2: am borg
4: i am borg
Each term is padded with spaces so that too matches too but not tool. The generated terms are then used to search the index.
The Search Algorithm
The algorithm to search assigns relative weights based on where the term is found.
var search = function (terms) {
var results = [];
searchHost.index.forEach(function (item) {
if (item.tags) {
var weight_1 = 0;
terms.forEach(function (term) {
if (item.title.startsWith(term.term)) {
weight_1 += term.weight * 32;
}
});
weight_1 += checkTerms(terms, 1, item.content);
weight_1 += checkTerms(terms, 2, item.description);
weight_1 += checkTerms(terms, 2, item.subtitle);
item.tags.forEach(function (tag) {
weight_1 += checkTerms(terms, 4, tag);
});
weight_1 += checkTerms(terms, 16, item.title);
if (weight_1) {
results.push({
weight: weight_1,
item: item
});
}
}
});
}
At a high level, each “hit” is approximately:
1: content
2: description or subtitle
4: tag
16: title
32: title starts with
Each hit weight is multiplied by the phrase weight. The algorithm is skewed heavily towards hits in the title, because if a phrase is matched, the scores for the fragments (ex: “I am Borg” = “I am” and “am Borg” as well) are also added. A more sophisticated algorithm could store terms as a tree and stop matching at the apex, but this method seemed to give me expected results in my tests so I saw no need to further complicate or tweak it.
Here is the logic that counts numbers of hits in a target:
var checkTerms = function (terms, weight, target) {
var weightResult = 0;
terms.forEach(function (term) {
if (~target.indexOf(term.term)) {
var idx = target.indexOf(term.term);
while (~idx) {
weightResult += term.weight * weight;
idx = target.indexOf(term.term, idx + 1);
}
}
});
return weightResult;
};
Using ~ is a simple hack. indexOf returns -1 for “not found” or a zero-based index if it is found. The complement of -1 is 0 or falsy, anything 0 or higher becomes a negative number or truthy.
By stripping symbols, I lose the ability to search for C# but for other cases it works fine (i.e. node.js becomes the phrase node js). If there are test cases that return invalid results, I’ll revisit the algorithm, but it appears to be working for now. If you encounter an issue, feel free to provide feedback using the comment form at the end of this article.
Returning Results
The hard part (searching) is done. Now I simply sort the array by descending weight and render the parts. I store images in the front matter metadata for each page, so it’s easy to extract the URL to show thumbnails in the results.
var render = function (results) {
results.sort(function (a, b) { return b.weight - a.weight; });
for (var i = 0; i < results.length && i < limit; i += 1) {
var result = results[i].item;
var resultPane = "<div class=\"container\">" +
("<div class=\"row\"><a href=\"" + result.permalink + "\" ") +
("alt=\"" + result.showTitle + "\">" + result.showTitle + "</a>" +
"</div>") +
"<div class=\"row\"><div class=\"float-left col-2\">" +
("<img src=\"" + result.image + "\" alt=\"" + result.showTitle + "\" class=\"rounded img-thumbnail\">") +
"</div>" +
("<div class=\"col-10\"><small>" + result.showDescription + "</small></div>") +
"</div></div>";
$("#results").append(resultPane);
}
};
Summary
The search is entirely contained in a few files, specifically the /static/search URL, the /index.json database, and the /js/search.js logic. These files can all be cached, so the search is entirely usable in offline mode (I’ll blog about the steps to create a Progressive Web App soon). You can view the latest source here.
The database is updated every time the website is re-published, so it is always current (with a slight delay based on the website’s own cache).
Do you have feedback or improvements to the algorithm and/or code? Did you solve the problem in a different way? Share your thoughts in the comments below!
Regards,