Introduction
There are plenty of parser generators out there for .NET, but no language agnostic parser with syntax directed actions (code in the grammar), syntactic predicates, and custom parse routines. Parsley is different. Parsley allows you to write your code in the grammar in a C# subset that is then converted to the target parser's generated language, so if someone wants to use your parser source code in VB they can, even though your code was C#. There are also very few recursive descent parser generators out there, most preferring the table generated approach. The advantage of recursive descent is it's far more intuitive than the table driven approach and the parse routines are completely overridable - plus the code is actually readable. This generator works somewhat like Coco/R in than it is internally LL(1) but allows you to use code to parse more complex constructs than LL(1) allows for. I haven't really used Coco/R but I think it's table driven, unlike Parsley and Parsley has more code features as a result, such as virtual non-terminals for completely overriding a parse. I can't be certain Coco/R doesn't do these things, but I'm fairly sure. If I'm right, Parsley can potentially parse more grammars in more ways than Coco/R.
Update: Improved output code generation, added features. See below.
Update 2: Bugfix in grammars, rewrite of part of article, feature adds
Update 3: Added GPLEXv1 support!
Update 4: Added experimental backtracking support
Update 5: Added syntactic predicates, and virtual and abstract non-terminals, and /fast option
Update 6: Added @options directive and the ParsleyDevstudio Visual Studio Integration Package for Parsley, Rolex and Gplex
Copyright / License Notice:
While most of the code here is mine, GPLEXv1 is not my project, and I have yet to fork it per se (I haven't modified the source yet) but I probably will as it hasn't been maintained. It's also very difficult to build the first time because you need the gplex and gppg binaries to build it the first time around, and those binaries can be dicey to find. I also plan to use it for Slang because it supports Unicode, while Rolex does not. I've included it, in ready to build form simply to make life easier on me and you.
Gardens Point LEX Copyright © 2006-2011 Queensland University of Technology (QUT). All rights reserved.
The full license is included in GPLEXcopyright.rtf in the Gplex folder.
Background
Parser generators build parsers which break down text into a meaningful hierarchy of symbols which can be easily processed programmatically. Compilers user parsers to parse your code. JSON libraries use parsers to parse JSON, and Excel uses a parser to decode the formulas in your cells.
Parsers come in a variety of algorithms, from simple LL(1), to the almost incomprehensible GLR parsing algorithm. Parsely is LL(1), which means it processes grammars from top to bottom creating a left derivation tree and one symbol of lookahead. The syntax, rather than the input directs the parse. This is the second most intuitive way to parse next to LL(k/*), which allows for arbitrary lookahead.
Using this Mess
Building this Mess
This code is provided as part of my larger Build Tools project. I've stripped the binaries out of the distribution, and yet they are used to build the distribution. To bootstrap it, you'll have to build a couple of times in Release. You'll get locking errors the first time. That's okay. The second time, you may still have a warning in your Error Panel, but it's stale. The build succeeded with no warnings.
Installing this Mess
All of the tools included with this distro are useful in their own right. You may want to copy deslang, csbrick, rolex and parsley to your PATH somewhere. This makes it easier to use them in pre-build steps because you won't have to fully qualify the EXE path. You can run the ParsleyDevstudio.vsix installer to install the Visual Studio integration, though it is inferior to the standard way of using this as a pre-build step.
Running this Mess
Parsley typically operates as a command line tool. It takes an input file, an optional output file and various parameters dictating the generated code options. Here is the usage screen:
Parsley generates a recursive descent parser and optional lexer spec
parsley.exe <inputfile> [/output <outputfile>] [/rolex <rolexfile>]
[/gplex <gplexfile>] [/gplexclass <gplexcodeclass>]
[/namespace <codenamespace>] [/class <codeclass>]
[/langage <codelanguage>] [/fast]
[/noshared] [/verbose] [/ifstale]
<inputfile> The XBNF input file to use.
<outputfile> The output file to use - default stdout.
<rolexfile> Output a Rolex lexer specification to the specified file
<gplexfile> Generate Gplex lexer specification to the specified file file. Will also generate supporting C# files (C# only)
<gplexcodeclass> Generate Gplex lexer specification with the specified class name. - default takes the name from <gplexfile>
<codenamespace> Generate code under the specified namespace - default none
<codeclass> Generate code with the specified class name - default derived from <outputfile> or the grammar.
<codelanguage> Generate code in the specified language - default derived from <outputfile> or C#.
<fast> Generate code quickly, without resolution using C# only - not valid with the <codelanguage> option.
<noshared> Do not include shared library prerequisites
<verbose> Output all messages from the generation process
<ifstale> Do not generate unless <outputfile> or <rolexfile> is older than <inputfile>.
Any other switch displays this screen and exits.
(sorry about the word wrapping!)
inputfile is the XBNF specification (explored below) that the parser will be generated fromoutputfile is optional and specifies the output code file to generate. If it's not specified, the code will be dumped to the stdout.rolexfile is optional and specifies the rolex lexer specification file to generate. If it's not specified, then no rolex specification will be generated.gplexfile is optional and specifies the gplex lexer specification file to generate. If it's not specified, it's not generated. Note that if it is, several files will be generated. This is necessary to support gplex.gplexcodeclass is optional and specifies the base class names to use for the generated classes. "Expression" would create ExpressionTokenizer, ExpressionTokenizerEnumerator and ExpressionScanner.codenamespace is the namespace under which to generate the code. If it's not specified, the code won't be generated under a namespace.codeclass is the name of the parser class to use. If you don't specify one, it will be the same as the outputfile, unless that's not specified, in which case it will take the name from the start element in the XBNF grammar.codelanguage is the language of the code to generate. If you don't specify one, it will be based on outputfile's file extension. If outputfile is not specified, it will default to C#.fast indicates that the code generation should skip the resolution step and simply emit in C#. This is not valid when specifying a codelanguage.noshared skips generating the shared code. This is important to specify for generating a second parser in the same project. The first parser should be generated without this switch, and subsequent parsers should be generated with this switch. If noshared is specified here, it should also be specified to rolex when rolex is used to generate the lexer/tokenizer code. You don't want duplicates of shared code in your source, because it will cause compile errors. This option also applies to Gplex generation.verbose emits all grammar transformation and validation messages, including messages about refactored rules. This can create huge dumps in the case of large grammars with lots of refactoring, but it allows you to see what changes it made. You can also see the changes in the doc comments of the generated code, regardless.ifstale skips generating the output unless the input has been modified. This is useful for pre-build steps as it prevents the overhead of rebuilding the parser every time.
You'll probably want to use this tool in tandem with one of the tokenizers included in the solution. Rolex, is the easiest to use, but Gplex supports Unicode and is basically more capable. These tools are lexer/tokenizer generators. Almost all parsers (excepting PEG parsers particularly) require lexers/tokenizers and Parsley is no exception. For further reading about Rolex, I wrote an article about creating Rolex here though you should use this codebase since it's much newer and uses Deslanged Slang technology to dramatically ease maintenance of the generated code while maintaining performance. For further reading about Gplex I'd just look at lex and flex resources as there's little to no documentation on Gplex itself but it's similar to those tools. Fortunately, I've included in Parsley the generation of a mostly identifical interface to that of Rolex lexers so coding against them is basically the same. The constructors are a little different is all. Eventually I'll unify them but it's not trivial because of the way Gplex works. If you use Gplex, it's often desirable to use the fast option with Parsley since the tokenizer is C# anyway.
Coding this Mess
Coming back to Parsley, let's examine the XBNF grammar format, which I use for all my parsers:
The XBNF format is designed to be easy to learn if you know a little about composing grammars.
The productions take the form of:
identifier [ < attributes > ] = expressions ;
There are more advanced variations of the above production syntax we'll approach later.
So for example, here's a simple standards compliant JSON grammar:
// based on spec @ json.org
Json<start>= Object | Array;
Object= "{" [ Field { "," Field } ] "}";
Field= string ":" Value;
Array= "[" [ Value { "," Value } ] "]";
Value<collapsed>=
string |
number |
Object |
Array |
Boolean |
null ;
Boolean= true|false;
number= '\-?(0|[1-9][0-9]*)(\.[0-9]+)?([Ee][\+\-]?[0-9]+)?';
string= '"([^\n"\\]|\\([btrnf"\\/]|(u[0-9A-Fa-f]{4})))*"';
true= "true";
false= "false";
null= "null";
lbracket<collapsed>= "[";
rbracket<collapsed>= "]";
lbrace<collapsed>= "{";
rbrace<collapsed>= "}";
colon<collapsed>= ":";
comma<collapsed>= ",";
whitespace<hidden>= '[\n\r\t ]+';
The first thing to note is the Json production is marked with a start attribute. Since the value was not specified it is implicitly, start=true.
That tells the parser that Json is the start production. If it is not specified, the first non-terminal in the grammar will be used. Furthermore, this can cause a warning during generation since it's not a great idea to leave it implicit. Only the first occurrence of start will be honored.
Object | Array tells us the Json production is derived as an object or array. The Object production contains a repeat {} construct inside and optional [] construct, itself containing a reference to Field. Array is similar, except it uses "[" and "]" and it refers to Value instead of Field.
Expressions
( ) parentheses allow you to create subexpressions like Foo (Bar|Baz)[ ] optional expressions allow the subexpression to occur zero or once{ } this repeat construct repeats a subexpression zero or more times{ }+ this repeat construct repeats a subexpression one or more times| this alternation construct derives any one of the subexpressions- Concatenation is implicit, separated by whitespace
Terminals
The terminals are all defined at the bottom but they can be anywhere in the document. XBNF considers any production that does not reference another production to be a terminal. You can force an element to be terminal with the terminal attribute (see below).
Regular expressions are between ' single quotes and literal expressions are between " double quotes. You may declare a terminal by using XBNF constructs or by using regular expressions. The regular expressions follow a POSIX + std extensions paradigm but don't currently support all of POSIX. They support most of it. If a POSIX expression doesn't work, consider it a bug. Unicode will be supported in a future version. I've already started support for constructs like \p and \P but the regex engine needs further optimization before Rolex can create that lexer in a reasonable amount of time. The problem is Unicode's huge range of things like letters and numbers is choking my current implementation which is about 80% optimized for ranges. The other 20% is killing performance in this case, but optimizing it is non-trivial.
Attributes
The collapsed element tells Parsley that this node should not appear in the parse tree. Instead, its children will be propagated to its parent. This is helpful if the grammar needs a nonterminal or a terminal in order to resolve a construct, but it's not useful to the consumer of the parse tree. During LL(1) factoring, generated rules must be made, and their associated non-terminals are typically collapsed. Above, we've used it to significantly trim the parse tree of nodes we won't need including collapsing unnecessary terminals like : in the JSON grammar. This is because they don't help us define anything - they just help the parser recognize the input, so we can throw them out to make the parse tree smaller.
The hidden element tells Parsley that this terminal should be skipped. This is useful for things like comments and whitespace.
The blockEnd attribute is intended for terminals who have a multi character ending condition like C block comments, XML CDATA sections, and SGML/XML/HTML comments. If present, the lexer will continue until the literal specified as the blockEnd is matched.
The terminal attribute declares a production to be explicitly terminal. Such a production is considered terminal even if it references other productions. If it does, those other productions which will be included in their terminal form as though they were part of the original expression. This allows you to create composite terminals out of several terminal definitions.
The ignoreCase attribute specifies that case shouldn't matter for matching. This only applies to terminals and only works with Rolex.
The type attribute specifies a .NET type or intrinsic C# type of the associated code block (see below). Values returned from such "typed" non-terminals are automatically converted to the target type, obviating the need to cast return values, or convert them using int.Parse() or the like. It will be handled for you.
The dependency attribute marks a non-terminal production as needed by the parser code you write.
The firsts and follows attributes are space delimited lists of terminal and non terminal symbols that hint to the parser what comes first and what can follow a particular non-terminal production. These are typically used in tandem with virtual productions (see the section toward the end)
The priority attribute marks a terminal production with a particular priority. A negative number is lower in priority than a positive number. Must be integer. By default items are priority 0.
Evaluation Code Blocks
Evaluation code blocks are specified in the grammar using a lambda/anonymous method-like syntax. => { ... } at the end of a non-terminal production. They take the form of:
identifier [ < attributes > ] = expressions => { ... }
Like:
Foo = Bar Baz => {
This signifies a block of code to associate with that non-terminal. This code is for parse actions, triggered by the EvaluateXXXX() methods. In this code, you take a ParseNode object, indicated by node and evaluate it, returning the result. If you do not return a result, a default value will be returned. See the example below.
On grammar notation conventions: I use title case for the non-terminals in the grammar. This isn't necessary, but is better in the end because functions like ParseXXXX() and EvaluateXXXX() take the XXXX portion directly from the non-terminal name. Ergo, the non-terminal foo would end up generating Parsefoo() and Evaluatefoo(). This is obviously undesirable but it's not a show stopper. I thought about mangling the name to "correct" this, but in the end I decided not to make unexpected changes to the code. This way, it was straightforward to know what the eventual names of these methods will be. The symbol constants are generated directly from the symbol names as well, so if you wanted to be consistent with Microsoft's naming guidelines, you'd name your terminals with Pascal case/.NET case as well. However, this is far from important, especially since unlike with non-terminals, their names aren't appended to anything.
Let's take a look at the grammar for an expression parser:
Term<start>= Factor { ("+"|"-") Factor };
Factor= Unary { ("*"|"/") Unary };
Unary= ("+"|"-") Unary | Leaf;
Leaf= integer | identifier | "(" Term ")";
integer='[0-9]+';
identifier='[A-Z_a-z][0-9A-Z_a-z]*';
whitespace<hidden>='\s+';
Now here's how the _ParseXXXX() methods that get generated work:
private static ParseNode _ParseLeaf(ParserContext context) {
int line = context.Line;
int column = context.Column;
long position = context.Position;
if ((ExpressionParser.integer == context.SymbolId)) {
ParseNode[] children = new ParseNode[1];
children[0] = new ParseNode(ExpressionParser.integer, "integer", context.Value, line, column, position);
context.Advance();
return new ParseNode(ExpressionParser.Leaf, "Leaf", children, line, column, position);
}
if ((ExpressionParser.identifier == context.SymbolId)) {
ParseNode[] children = new ParseNode[1];
children[0] = new ParseNode(ExpressionParser.identifier, "identifier", context.Value, line, column, position);
context.Advance();
return new ParseNode(ExpressionParser.Leaf, "Leaf", children, line, column, position);
}
if ((ExpressionParser.Implicit3 == context.SymbolId)) {
ParseNode[] children = new ParseNode[3];
children[0] = new ParseNode(ExpressionParser.Implicit3, "Implicit3", context.Value, line, column, position);
context.Advance();
children[1] = ExpressionParser._ParseTerm(context);
children[2] = new ParseNode(ExpressionParser.Implicit4, "Implicit4", context.Value, line, column, position);
if ((ExpressionParser.Implicit4 == context.SymbolId)) {
context.Advance();
return new ParseNode(ExpressionParser.Leaf, "Leaf", children, line, column, position);
}
context.Error("Expecting Implicit4");
}
context.Error("Expecting integer, identifier, or Implicit3");
return null;
}
You can see it resolving based on context's current symbol, and then parsing the child nodes, one by one. Terminals are parsed inline, while non-terminals are forwarded to their appropriate _ParseXXXX() methods. Non-terminals with collapsed children generate a little differently, using List<ParseNode> instead of ParseNode[] to hold the children. This is because at the point when we're propagating children from the collapsed nodes, we can't know how many nodes there will be, unlike when the nodes are not collapsed. This is okay, as it only generates this alternative when necessary, and it only requires one additional copy. You'll note the appearance of Implicit3 and Implicit4. Those are the names of the tokens we have not defined yet. If you want better error messages, give them a name in the grammar.
This is fine for parsing but will do nothing for evaluation. That is to say, the above will add a Parse() method to the parser class, but there's not enough information in the grammar to create an Evaluate() method. Basically, we can get a parse tree back with the above, but we can't evaluate it. Lets fix that by adding some code to the grammar:
Term<start>= Factor { ("+"|"-") Factor } => {
int result = (int)EvaluateFactor(node.Children[0]);
int i = 2;
while (i<node.Children.Length)
{
if(node.Children[i-1].SymbolId==add)
result += (int)EvaluateFactor(node.Children[i]);
else
result -= (int)EvaluateFactor(node.Children[i]);
i+=2;
}
return result;
}
Factor= Unary { ("*"|"/") Unary } => {
int result = (int)EvaluateUnary(node.Children[0]);
int i = 2;
while (i<node.Children.Length)
{
if(node.Children[i].SymbolId==Unary)
{
if(node.Children[i-1].SymbolId==mul)
result *= (int)EvaluateUnary(node.Children[i]);
else
result /= (int)EvaluateUnary(node.Children[i]);
} else
{
if(node.Children[i-1].SymbolId==mul)
result *= (int)EvaluateFactor(node.Children[i]);
else
result /= (int)EvaluateFactor(node.Children[i]);
}
i+=2;
}
return result;
}
Unary= ("+"|"-") Unary | Leaf => {
if(node.Children.Length==1)
return EvaluateLeaf(node.Children[0]);
if(node.Children[0].SymbolId==add)
return EvaluateUnary(node.Children[1]);
else
return -(int)EvaluateUnary(node.Children[1]);
}
Leaf= integer | identifier | "(" Term ")" => {
if(node.Children.Length==1)
{
if(node.Children[1].SymbolId==integer)
return int.Parse(node.Children[0].Value);
else
throw new NotImplementedException("Variables are not implemented.");
} else
return EvaluateTerm(node.Children[1]);
}
add="+";
mul="*";
integer='[0-9]+';
identifier='[A-Z_a-z][0-9A-Z_a-z]*';
whitespace<hidden>='\s+';
Note the code blocks indicated by => { ... } which tell our parser what to do with the parse tree we made.
This indicates an integer expression parser. Because there is code in the grammar, it creates a public ExpressionParser.Evaluate() method that can be used to call it, and thus evaluate a simple integer expression like 4+2*8.
Here is the code it generates for EvaluateLeaf(). You can see the code looks a lot like the associated code in the grammar above, with minor changes.
public static object EvaluateLeaf(ParseNode node, object state) {
if ((ExpressionParser.Leaf == node.SymbolId)) {
if ((node.Children.Length == 1)) {
if ((node.Children[1].SymbolId == ParsleyDemo.ExpressionParser.integer)) {
return int.Parse(node.Children[0].Value);
}
else {
throw new NotImplementedException("Variables are not implemented.");
}
}
else {
return ParsleyDemo.ExpressionParser.EvaluateTerm(node.Children[1]);
}
}
throw new SyntaxException("Expecting Leaf", node.Line, node.Column, node.Position);
}
Here's that same code in VB.NET.
Public Overloads Shared Function EvaluateLeaf(ByVal node As ParseNode, ByVal state As Object) As Object
If (ExpressionParser.Leaf = node.SymbolId) Then
If (node.Children.Length = 1) Then
If (node.Children(1).SymbolId = ParsleyDemo.ExpressionParser.[integer]) Then
Return Integer.Parse(node.Children(0).Value)
Else
Throw New NotImplementedException("Variables are not implemented.")
End If
Else
Return ParsleyDemo.ExpressionParser.EvaluateTerm(node.Children(1))
End If
End If
Throw New SyntaxException("Expecting Leaf", node.Line, node.Column, node.Position)
End Function
As you can see, the code block in the grammar was translated to the target language. This is Slang. Slang is still experimental, but it works well enough for doing simple evaluation inside code blocks. There's one problem here. EvaluateUnary() (and Evaluate() and all of the EvaluateXXXX() methods return object! This is an integer expression parser so returning int is far more appropriate. Fortunately, we can tell the parser what type to return using the type attribute. Here we add the type attributes to the elements we've changed the grammar, which I've put in bold:
Term<start,type="int">= Factor { ("+"|"-") Factor } => {
int result = EvaluateFactor(node.Children[0]);
int i = 2;
while (i<node.Children.Length)
{
if(node.Children[i-1].SymbolId==add)
result += EvaluateFactor(node.Children[i]);
else
result -= EvaluateFactor(node.Children[i]);
i+=2;
}
return result;
}
Factor<type="int">= Unary { ("*"|"/") Unary } => {
int result = EvaluateUnary(node.Children[0]);
int i = 2;
while (i<node.Children.Length)
{
if(node.Children[i].SymbolId==Unary)
{
if(node.Children[i-1].SymbolId==mul)
result *= EvaluateUnary(node.Children[i]);
else
result /= EvaluateUnary(node.Children[i]);
} else
{
if(node.Children[i-1].SymbolId==mul)
result *= EvaluateFactor(node.Children[i]);
else
result /= EvaluateFactor(node.Children[i]);
}
i+=2;
}
return result;
}
Unary<type="int">= ("+"|"-") Unary | Leaf => {
if(node.Children.Length==1)
return EvaluateLeaf(node.Children[0]);
if(node.Children[0].SymbolId==add)
return EvaluateUnary(node.Children[1]);
else
return -EvaluateUnary(node.Children[1]);
}
Leaf<type="int">= integer | identifier | "(" Term ")" => {
if(node.Children.Length==1)
{
if(node.Children[1].SymbolId==integer)
return node.Children[0].Value;
else
throw new NotImplementedException("Variables are not implemented.");
} else
return EvaluateTerm(node.Children[1]);
}
add="+";
mul="*";
integer='[0-9]+';
identifier='[A-Z_a-z][0-9A-Z_a-z]*';
whitespace<hidden>='\s+';
Note that not only do we now have the attribute type="int" marked up on each non-terminal production, we also have changed the code (particularly in Leaf) slightly, from:
if(node.Children.Length==1)
{
if(node.Children[1].SymbolId==integer)
return int.Parse(node.Children[0].Value);
else
throw new NotImplementedException("Variables are not implemented.");
} else
return EvaluateTerm(node.Children[1]);
To:
if(node.Children.Length==1)
{
if(node.Children[1].SymbolId==integer)
return node.Children[0].Value;
else
throw new NotImplementedException("Variables are not implemented.");
} else
return EvaluateTerm(node.Children[1]);
This change wasn't necessary, but it simplifies things slightly. This uses Microsoft's TypeConverter framework in tandem with Convert.ChangeType() to automatically translate your return values to the target type.
Regardless of all that code, using the generated code is pretty simple:
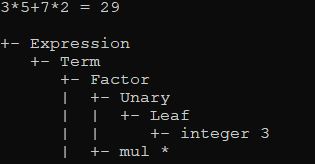
var text = "3*5+7*2";
var exprTokenizer = new ExpressionTokenizer(text);
var pt = ExpressionParser.Parse(exprTokenizer);
Console.WriteLine("{0} = {1}",text,ExpressionParser.Evaluate(pt));
Console.WriteLine();
The reason creating the parser is a separate step than creating the tokenizer is because it's actually possible to use a tokenizer other than a Rolex tokenizer with this parser, but you'll have to provide your own Token struct and a class implementing IEnumerable<Token>. For performance reasons, there is no IToken interface. However, your token must have the following fields: (int) SymbolId, (string) Symbol, (string) Value, (int) Line, (int) Column, and (long) Position and the constructor taking all of these things. See the reference source under Rolex\Shared\Token.cs. Modifying the original file will change the behavior of Rolex.
Finally, now we have Evaluate(), but there's one niggling issue to address, and that is variables, which were previously not implemented. We can implement variables using the state argument in Evaluate() which allows us to pass a user defined value in to our evaluation code. We'll have to change the code in the grammar in order to support it, so lets modify the grammar again.
Term<start,type="int">= Factor { ("+"|"-") Factor } => {
int result = EvaluateFactor(node.Children[0],state);
int i = 2;
while (i<node.Children.Length)
{
if(node.Children[i-1].SymbolId==add)
result += EvaluateFactor(node.Children[i],state);
else
result -= EvaluateFactor(node.Children[i],state);
i+=2;
}
return result;
}
Factor<type="int">= Unary { ("*"|"/") Unary } => {
int result = EvaluateUnary(node.Children[0],state);
int i = 2;
while (i<node.Children.Length)
{
if(node.Children[i].SymbolId==Unary)
{
if(node.Children[i-1].SymbolId==mul)
result *= EvaluateUnary(node.Children[i],state);
else
result /= EvaluateUnary(node.Children[i],state);
} else
{
if(node.Children[i-1].SymbolId==mul)
result *= EvaluateFactor(node.Children[i],state);
else
result /= EvaluateFactor(node.Children[i],state);
}
i+=2;
}
return result;
}
Unary<type="int">= ("+"|"-") Unary | Leaf => {
if(node.Children.Length==1)
return EvaluateLeaf(node.Children[0],state);
if(node.Children[0].SymbolId==add)
return EvaluateUnary(node.Children[1],state);
else
return -EvaluateUnary(node.Children[1],state);
}
Leaf<type="int">= integer | identifier | "(" Term ")" => {
if(node.Children.Length==1)
{
if(node.Children[0].SymbolId==integer)
return node.Children[0].Value;
else
{
if(state!=null)
{
int val;
var d = (IDictionary<string,int>)state;
if(d.TryGetValue(node.Children[0].Value,out val))
return val;
}
throw new SyntaxException(string.Format("Reference to undefined variable {0}",node.Children[0].Value),node.Line,node.Column,node.Position);
}
} else
return EvaluateTerm(node.Children[1],state);
}
add="+";
mul="*";
integer='[0-9]+';
identifier='[A-Z_a-z][0-9A-Z_a-z]*';
whitespace<hidden>='\s+';
Note we're now using the state variable to hold an IDictionary<string,int> instance which we use to hold our variables. We also pass state along to each of our evaluation methods. This is important, as the parser itself is stateless.
When we encounter an identifier, we resolve it using a simple dictionary lookup.
We have to change the code we use to call it now, to pass in our variables:
var text = "3*5+a*2";
var vars = new Dictionary<string, int>();
vars["a"] = 1;
var exprTokenizer = new ExpressionTokenizer(text);
var pt = ExpressionParser.ParseExpression(exprTokenizer);
Console.WriteLine("{0} = {1}",text,ExpressionParser.Evaluate(pt,vars));
And Bob's your uncle. There you go.
However, it's a bit complicated. So I've added some shorthand to simplify. For starters there are virtual variables named <Production>1 to <Production>N where <Production> is the name of a production in your grammar.
For the above grammar we have Unary1, Unary2, UnaryN, and Expression1, Expression2, ExpressionN, and Factor1 and Factor2 and so on. We also have SymbolId1, SymbolId2, etc.
The numbers are 1 based positions into the child nodes. SymbolId1 is an alias for node.Children[0].SymbolId. The terminals just point to node.Children[x].Value and the non-terminal productions call the associated evaluate method for the non-terminal at the specified position like, so Factor3 from the above grammar would resolve to ExpressionParser.EvaluateFactor(node.Children[2], state)!
You can also index in to these like Unary[i]. In addition there is a Child macro (Child1..ChildN, Child[i]) that gives you the ability to evaluate the node type at run time and it will call the appropriate EvaluateXXXX() method for you. This is useful in cases where we have collapsed nodes in the underlying grammar because sometimes that means we can't know which nodes we'll see in our evaluate function ahead of time. We'll visit this below:
Also, this may not seem very intuitive above until you look at the final grammar format:
Term<start,type="int">= Factor { ("+"|"-") Factor } => {
int result = Factor1;
int i = 2;
while (i<Length)
{
if(SymbolId[i-1]==add)
result += Factor[i];
else
result -= Factor[i];
i+=2;
}
return result;
}
Factor<type="int">= Unary { ("*"|"/") Unary } => {
int result = Unary1;
int i = 2;
while (i<Length)
{
if(SymbolId[i-1]==mul)
result *= (int)Child[i];
else
result /= (int)Child[i];
i+=2;
}
return result;
}
Unary<type="int">= ("+"|"-") Unary | Leaf => {
if(Length==1)
return Leaf1;
if(SymbolId[0]==add)
return Unary2;
else
return -Unary2;
}
Leaf<type="int">= integer | identifier | "(" Term ")" => {
if(Length==1)
{
if(SymbolId[0]==integer)
return integer1;
else
{
if(state!=null)
{
int val;
var d = (IDictionary<string,int>)state;
if(d.TryGetValue(identifier1,out val))
return val;
}
throw new SyntaxException(string.Format("Reference to undefined variable {0}",identifier1),node.Line,node.Column,node.Position);
}
} else
return Term2;
}
add="+";
mul="*";
integer='[0-9]+';
identifier='[A-Z_a-z][0-9A-Z_a-z]*';
whitespace<hidden>='\s+';
Take a look at that! That's pretty easy to follow once you get the hang of it. The macros clear things right up and keep it simple
Code Regions In The Grammar
Anywhere between productions you can specify regions of code to be added to the parser class using { }. Any fields or methods must be static or const, and not named after any symbol in the grammar.
These regions are added as members of the class. We'll visit them in a moment when we make a helper method in the next section.
Syntactic Constraints
Syntactic constrants, or syntactic predicates help disambiguate your grammar by indicating a boolean function which tells the parser whether your production matches. Here's an example below, also using code regions from just above, of using the where clause, which takes the form of:
identifer [ "<" attributes ">" ] = expressions (";" | [ "=>" "{" code "}" ] ) ":" "where" "{" code "}"
The following disambiguates between a C# keyword and an identifer: (note that the terminal definitions we're using are Unicode so they require a Gplex lexer)
Identifier<collapsed> = verbatimIdentifier | identifier : where { return !Keywords.Contains(context.Value); }
verbatimIdentifier='@(_|[[:IsLetter:]])(_|[[:IsLetterOrDigit:]])*';
identifier='(_|[[:IsLetter:]])(_|[[:IsLetterOrDigit:]])*';
{
static HashSet<string> Keywords=_BuildKeywords();
static HashSet<string> _BuildKeywords()
{
var result = new HashSet<string>();
string[] sa = "abstract|as|ascending|async|await|base|bool|break|byte|case|catch|char|checked|class|const|continue|decimal|default|delegate|descending|do|double|dynamic|else|enum|equals|explicit|extern|event|false|finally|fixed|float|for|foreach|get|global|goto|if|implicit|int|interface|internal|is|lock|long|namespace|new|null|object|operator|out|override|params|partial|private|protected|public|readonly|ref|return|sbyte|sealed|set|short|sizeof|stackalloc|static|string|struct|switch|this|throw|true|try|typeof|uint|ulong|unchecked|unsafe|ushort|using|var|virtual|void|volatile|while|yield".Split(new char[] {'|'});
for(var i = 0;i<sa.Length;++i)
result.Add(sa[i]);
return result;
}
}
We can make the _BuildKeywords() function using a fixed string lookup which would be more efficient, but a lot more code.
Here we've specified verbatimIdentifier before identifier, which gives it priority in the lexer/tokenizer. Our non-terminal Identifier (not to be confused with the terminal identifier) specifies either a verbatimIdentifier or an identifier and uses a where clause to determine if it is a keyword, in which case, the parser will not consider the item under the cursor as an Identifier while parsing. There's a trick for experienced users wherein you can override a first-first or first-follows conflict simply by specifying a where clause and always returning true. However, only use this when you know what you're doing as it can render parts of the grammar unreachable, and won't warn you. We didn't have to collapse Identifier but we did it because it's not needed in the final parse tree, and just makes an unnecessary extra node. Also note the use of the pre-fix increment in the loop. Remember that Slang will not support post-fix increment because the underlying CodeDOM cannot do so in a language agnostic manner.
Abstract and Virtual Non-Terminals
These are used together which is why we'll cover them together. This is a powerful feature to resolve parses that the generated code can't handle, like the difference between a cast expression and a parenthesized subexpression in C#. We'll start with the virtual non-terminals, which take the form of:
identifier "<" attributes ">" "{" code "}"
First, lets cover the firsts attribute. This simply tells the parser which symbols can come first in your virtual non-terminal. These must match your parser function or the parser won't find your non-terminal correctly! I also mark the non-terminal with the no-op virtual attribute simply for readability, but this is optional:
Cast<virtual,firsts="lparen"> {
return _ParseCast(context);
}
Note that I forwarded to a function. This is so I can keep all my code at the bottom of the grammar in a code region (which we covered above). Note that I also put an underscore before my function. This is to ensure the name doesn't conflict with any of the generated parse functions, including ParseCast() itself, which will be generated as a result of this virtual non-terminal declaration. Let's take a look at _ParseCast():
static ParseNode _ParseCast(ParserContext context) {
int line = context.Line;
int column = context.Column;
long position = context.Position;
if("("!=context.Value)
context.Error("Expecting ( as start of expression or cast");
ParseNode lp = new ParseNode(SlangParser.lparen, "lparen", context.Value, context.Line, context.Column, context.Position);
context.Advance();
ParseNode type = ParseTypeCastPart(context);
ParseNode expr = ParseExpression(context);
return new ParseNode(SlangParser.Cast, "Cast", new ParseNode[] {type,expr}, line, column, position);
}
In the code block we use the other parse routines and create parse nodes based on a parse, using the parser's API directly: You can see this is rather involved. With great power comes great responsibility. Here you are responsible for handling line numbers, manually parsing terminals, advancing the cursor, calling other ParseXXXX() functions and reporting parse nodes accurately. Note how we Advance() to move past the terminals, but we don't need to do so to move past the non-terminals, because the other ParseXXXX() functions do that for us. Remember to pass context around. Note how we were careful to store the initial line, column and position information when we entered the function because we report them at the end. Note we use the current line, column, and position when reporting an error parsing a terminal. Be careful here or your position information will be wrong. Basically this allows you to entirely implement a ParseXXXX() method yourself rather than using the generated code.
See how we parsed TypeCastPart? I haven't shown you the definition yet, but here it is:
TypeCastPart<include,collapsed>= Type ")";
Note the addition of the include attribute. This is a dummy attribute to make sure TypeCastPart shows up in the grammar, because it's not referenced by anything in the grammar except code. Attributes force a non-terminal to be present in the grammar. We didn't need include here but I specified it for readability. Had we not specified collapsed we would have had to specify include (or something else), otherwise ParseTypeCastPart() would never show up in the grammar. Since we don't actually report it in the parse tree, but just use it for parsing we collapse it. That part however, is optional. See how it ends with ")"? That's because a cast looks like (string)foo and so in order for the parser to know the ")" can follow a Type we had to eat the closing parenthesis here. The other option would have been to parse Type manually which is simply too much work.
And finally we come to abstract non-terminals. Say you wanted to report a non-terminal above which wasn't actually in the grammar. Abstract non-terminals simply allow you to put an "empty/no-op" non-terminal in the grammar, which can then be reported by your parse function because it has a symbol constant associated with it. They take the form of:
identifier "<" attributes ">" ;
See how nothing is specified for this production other than attributes. It's simply terminated with a semicolon. All it does is generate a symbol in the grammar, so this...
Foo<abstract>;
generates a constant symbol you can use, but no ParseFoo() method. You'd return this from one of your virtual non-terminals. It wouldn't be used anywhere else. Note again, you have to specify an attribute for any non-terminal not-referenced in the grammar, and that includes abstract non-terminals which can't be referenced in the grammar.
See the ParsleyDemo and ParsleyDemoVB projects for more.
The @options Directive
The @options directive allows you to override much of the command line of Parsley with your own settings in the grammar. In the case where a grammar imports other grammars, only the top level grammar's @options settings will be honored. The format is as follows:
@options option1=optionValue1, option2=optionValue2, option2=optionValue3;
The @options directive may appear once, and like @import must appear before any productions. An option value can be a quoted string, an number, a boolean, or null. The current available options are as follows, and correspond to their command line counterparts: outputfile, codenamespace, codeclass, codelanguage, rolexfile, gplexfile, gplexcodeclass, fast and verbose. Like with attributes, boolean values that are true don't need their value specified explicitly, just their name, so verbose and verbose=true are equivelent. Again, these override the command line options. You will typically use them with the Visual Studio integration, explored below.
Using this Mess as a Pre-Build Step
Simply navigate to your project options, under Build Events (C#) and add it to the pre-build event command line. Finding the pre-build event location in your project options is more involved in VB than it is in C#, but dig around. It's there.
Either way, you need to know what to feed it, so here you go. You need to make two things - a parser and a tokenizer/lexer. Each will have it's own command line to execute. For your parser, you'll use parsley.exe, and for your tokenizer/lexer you'll either use rolex.exe or gplex.exe. You'll want parsley.exe to come first, and make sure to give it the right arguments to generate a lexer file for you (assuming the grammar doesn't indicate one). Following that, you'll want to run rolex.exe or gplex.exe depending which lexer you're using. If you're making your own lexer from scratch, you can skip that second command line but most people won't ever do that.
Anyway, here are the basics (see ParsleyDemo and ParsleyDemoVB)
"parsley.exe" "$(ProjectDir)Expression.xbnf" /output "$(ProjectDir)ExpressionParser.cs" /rolex "$(ProjectDir)Expression.rl" /namespace ParsleyDemo /ifstale
"rolex.exe" "$(ProjectDir)Expression.rl" /output "$(ProjectDir)ExpressionTokenizer.cs" /namespace ParsleyDemo /ifstale
First, put quotes around paths, including macros, and including your initial executable path. We simply specified "parsley.exe" and "rolex.exe" here but you may need to put in their full paths unless they're in your PATH. The demo projects simply use the binaries from the related projects in the solution, but that's not available to you in other situations. One option is to include the executables in your project's folder somewhere and reference those using relative paths. That way if you copy the project to another machine it will still build. I hope that's clear.
Note we've used macros to refer to the project directory. The list of macros is available in the edit window of the pre-build events if you click around/click through.
The above was an example of using Parsley with Rolex. Using it with Gplex is similar:
"parsley.exe" "$(ProjectDir)Slang.xbnf" /output "$(ProjectDir)SlangParser.cs" /gplex "$(ProjectDir)Slang.lex" /namespace CD /fast /ifstale
"gplex.exe" /out:"$(ProjectDir)SlangScanner.cs" "$(ProjectDir)Slang.lex"
Note how the syntax of Gplex's command line arguments are different and options preceed the input file. Be careful with this. I didn't write Gplex, so its usage is quite a bit different than the ones in the programs I've written.
Visual Studio Integration
By request I've added devstudio integration for Parsley, Rolex and Gplex which can be installed via the ParsleyDevstudio VSIX package. In this package are 3 custom tools that each generate a log and the output of the particular program as files underneath the main file.
Navigate to the XBNF (Parsley, *.xbnf) input file, the Rolex lexer input file (*.rl), or the Gplex lexer input file (*.lex) and set the appropriate custom tool and then wait as these tools take some significant time to do their work. I recommend you use this only for small grammars or with the (C# only) fast option and using gplex lexers to cut your wait time down. Unfortunately, due to the infrastructure provided by Visual Studio, I can't make these custom tools work without freezing devstudio while they're working.
To set it up, install the VSIX package and then navigate to an XBNF document, click on it in solution explorer to get the document properties (usually on the lower right of the VS workspace), find Custom Tool and then set it Parsley - as soon as you do, Parsley will begin the generation process, so VS will be unresponsive for a few seconds. The other custom tools are Gplex and Rolex.
Limits of Visual Studio Integration
The pre-build step method of integrating Parsley into your builds is still the recommended way to build your projects. However, if you choose to use the VS custom tool integration instead, please be mindful of these limitations:
- Parsley is kind of slow to generate, and sometimes VS will regenerate for no reason causing unnecessary churn
- The lexers will only support one lexer per namespace. This is due mainly to limitations in Gplex and Rolex, and with Rolex, using the pre-build method instead can sidestep this. Attempts to generate multiple lexers in one namespace will create compile errors.
- The custom tools cannot detect changes to dependent files, like imports. You must rerun the tool manually if these are changed.
- When removing the custom tool from a file, the generated files will not all be removed, only the log will. You must remove the other files manually.
- I haven't tested this integration as extensively as I'd like. Testing it is somewhat difficult, so it's a work in progress.
- You cannot use the custom tools during VS automated builds (running VS with no UI) - the tools only work in the design time environment.
- I'm pretty sure renaming a top level file will break something.
- You simply do not have as much control as you do at the command line overall.
Some of these limitations are due to a monumental hack I had to employ to get Visual Studio to recognize multiple output files from a single custom tool. It's not designed for it at all, and to do so requires some ugly magic. Some, like the periods of unresponsiveness are simply due to the nature of Parsley and/or custom tools.
Note that you'll almost certainly want to use the @options directive in your XBNF document at least to specifiy lexer file(s) to generate. If Parsley is used to generate lexer documents, the lexer documents will automatically be associated with their appropriate custom tools, so the lexer generators will be run on them as appropriate as well. Because of this, while there are 3 VS custom tools, you'll mainly only use "Parsley" yourself and the others will be set automatically as needed.
Further Reading
For follow ups using advanced parsley features: Parse Anything Part 1 and Part 2.
For more information about firsts and follows, and fundamentals of parsing LL(1), see How To Make a Parser, Lesson 1
For more information on recursive descent parsing in general, see Recursive Descent Parser at Geeks for Geeks.
History
- 19th December, 2019: Initial submission
- 20th December, 2019: Update
- 21st December, 2019: Update 2
- 22st December, 2019: Update 3
- 23rd December, 2019: Update 4
- 26th December, 2019: Update 5
- 9th January, 2019: Update 6

