Here we make a TensorFlow Lite model from a pre-trained model.
This is the second article in a series of articles about using TensorFlow Lite on Android. In the previous section the development environment was set up for working with TensorFlow models and Android development. We continue here with adapting a network for TensorFlow Lite.
When using TensorFlow Lite on a mobile device, you will probably want to use a network that has already been trained. A pretrained network gets you past the process of gathering and preparing a large amount of data needed for training a visual recognizer and more quickly to the point of being productive. Pre-trained networks may have been built using a number of different technologies.
To support interoperability among the formats in which neural network models could be saved, there is an intermediate format. This format is known as the Open Neural Network Exchange format (ONNX). ONNX is supported by a range of companies including Microsoft, Facebook, AMD, IBM, ARM, NVIDIA, Qualcomm, and many others.
Thanks to ONNX, developers can use their preferred software and frameworks for producing their neural network models and share them with people that may be using other AI technologies. This means that TensorFlow Lite is not limited to using only models that were implemented with TensorFlow. Networks that use operations that are common to machine learning frameworks can be shared among the ML technologies using ONNX. Note that networks that use experimental or less common operations may have limited portability to other frameworks.
For this article, I will use a model that was taken from the ONNX Model Zoo. Within this repository you will find models for visual recognition, voice recognition, gesture analysis, and more. I will download one of the YOLO (You Only Look Once) models, a visual classification model. I’m using a YOLO4 implementation. Within the repository you will find it in /vision/object_detection_segmentation/yolo4/models.
If you would like to use models from this repository, you will need to use GIT LFS (Large File System). With GIT LFS, you can clone a repository and then download only the files of interest, without all the large files downloading. Before cloning this repository, activate GIT LFS with the following command:
git lfs install
GIT displays a confirmation of LFS being enabled. Next, clone the ONNX Model Zoo repository:
git clone https:
The cloned repository will have placeholder files for the larger .onnx files. To download the actual data for the file, use a git lfs pull command and pass the path relative to the repository of the file or folder to download:
git lfs pull --include="vision/object_detection_segmentation/yolov4/model" --exclude=""
Or, if you have enough space, network bandwidth, and time and would prefer to download all files in the model, you could pass the wildcard character for the name of the files to download:
git lfs pull --include="*" --exclude=""
In selecting a network, you will also want to check on the information of the preconditions and postconditions for data that the network processes. For some of the networks, you can find this information alongside the model in a readme file. For some other networks, you may need to look at their original source to find this information. Networks for visual recognition may need the image resized to a specific range or need the pixel values encoded a certain way (for example, integer values, float values, ranged from 0.0-1.0, or 0.0-255.0, or some other range). The data output from a network will come in the form of arrays of numbers. Consult the model’s documentation to find out what the numbers represent and how they are arranged. For the network that I’ve selected, in its readme.md file there’s a statement that the image must be 416x416 pixels as floating point values.
The Netron utility, while not a replacement for model documentation, is useful for extracting information from a model. Netron shows the arrangement of the neurons in the network along with some other information. Right now, the pieces of information we’re interested in are the inputs and outputs of a network. Opening one of the YOLO network models with Netron and then selecting the input node produces a screen like this:
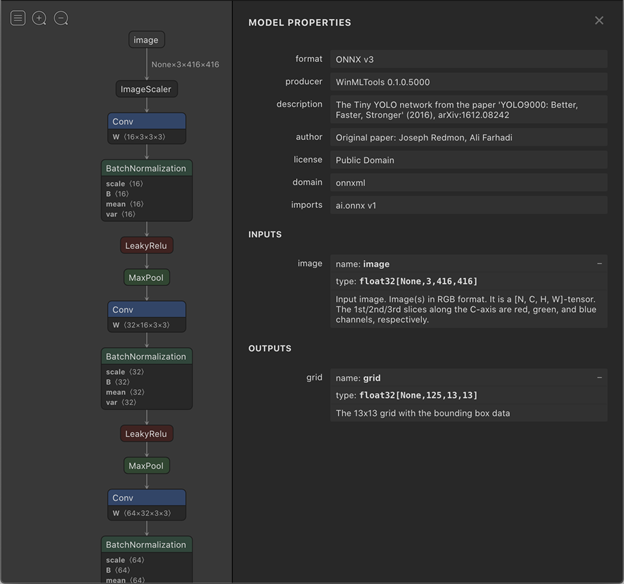
From this screen I can see that the input to this model is for an RGB image that has been resized to 416x416 pixels. The pixels are encoded as floating values. This image is a NCHW image. There are a number of possible ways to organize image data.
- N - number of batches of images passed in. This will usually be 1 for one batch or None meaning that the number of batches is dynamic and may vary.
- C - image channel. In this case the channels are for red, green, and blue
- H - Height of the image. Traversing along this dimension will take us from one row in the image to another.
- W - Width of the image. Traversing along this dimension moves us among the pixels that are next to each other.
This screen from Netron also shows that the output of this neural network model is a tensor containing 125x13x13 float values for each batch that was passed to it ([Nonex125x13x13]). This tool doesn’t specify what these values mean individually, but we need to know it for configuring the input and output values.
To convert one of these ONNX models to a TensorFlow freeze graph, from the terminal use onnx-tf with arguments that match the following pattern:
onnx-tf convert -i source_model.onnx -o output_model.pb
After a few moments, you will have the converted TensorFlow freeze graph. What we actually want is a TensorFlow Lite file. To convert the file from TensorFlow to TensorFlow Lite, I use a Python script. A command line tool exists, but I’ve found using a Python script to be more flexible.
import tensorflow as tf
saved_model_dir='/dev/projects/models'
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tf_lite_model = converter.convert()
open('output.tflite', 'wb').write(tf_lite_model)
The output can be named whatever you like as long as it has the .tflite extension. Make sure you set the extension correctly, as it will be important later on.
Next Steps
Now that we’ve converted the ONNX model to Tensorflow Lite, we’re ready to use it in an Android application. That’s what we’ll be covering in the next article.

