Graphs are one of the most common questions that might show up in a technical interview, especially in these days where many real-world applications can be represented by nodes and edges such as the social networks!
There are hundreds of graph questions that can show up in a programming interview, luckily there are only a handful of algorithms we need to really understand that will help us solve most of them.
In this article, we will talk about how we would solve the leetcode problem Clone Graph which requires us to use a Breadth First Search traversal of a graph to clone it.
Problem Statement
Given a reference of a node in a connected undirected graph. Return a deep copy of the graph.
Each Graph Node contains a val and a list GraphNode of its neighbors.
class Node {
public int val;
public List<Node> neighbors;
}
The input for this problem is a single Node that is connected to the other nodes and our goal is to make an exact copy of it.
Understanding the Problem
There are a couple of terminologies that were mentioned that needed to be understood to solve the problem.
In an undirected graph, let’s say Node 1 points to Node 2, it also implies that Node 2 will also point to Node 1.
 Undirected Graph
Undirected Graph
The other kind of graph is a directed graph where if Node 1 points to Node 2, it does not necessarily mean that Node 2 points back to Node 1.
 Directed Graph
Directed Graph
For our output we want to make a deep copy of the graph. A deep copy means that we are making a new instance of a Node that has all the same value and neighbors who are also a deep copy. This prevents us from being able to just return the given node.
High Level Algorithm
To make a deep copy of the graph, we first have to visit all the nodes in the graph to make a copy of them. Common algorithms to explore nodes in a graph are Breadth First Search (BFS) and Depth First Search (DFS)
There are trade-offs that can be used for both algorithms, but they are implemented almost the same way. For simplicity’s sake, we’re going to solve this problem with BFS.
On the high level, a BFS algorithm will allow us to explore all the neighbor nodes first, all of our neighbor’s neighbors, etc until we explore every single node.
 Graph traversal order using a BFS algorithm
Graph traversal order using a BFS algorithm
A BFS algorithm requires 2 things:
- A Queue to put our nodes into. A queue follows the first in, first out policy, which we will later see allow us to make a BFS algorithm by processing our neighboring nodes first. This is in contrast to using a Stack, which follows a first in, last out policy which is used for DFS.
- A visited Set to keep track of the nodes that we visited so that we won’t explore them again, which is especially important as graphs can form a cycle and our algorithm can run forever.
There are typically 3 steps involved in a BFS (or DFS) algorithm.
- Put the given starting node in queue and visited set
- Iterating through the queue is emptied
- Pop a node from the queue, iterate through its children and add them to the visited set and queue if we haven’t seen them before.
The key that makes this work is the queue data structure. Whenever we add all the children of our tree into the queue, we are adding them to the end of the list, guaranteeing that we will explore all the children of the first node that we encounter first.
Here’s an example.
Given a small graph of 4 nodes:.
 Starting BFS example
Starting BFS example
In the graph, these nodes are all unidirectional. We will start by putting Node 1 into our Queue and visited Set:
 Adding our starting node into the queue and visited set
Adding our starting node into the queue and visited set
We will then start processing our queue
- Remove Node 1 from the queue and process its neighbor: Node 2 and Node 4.
- Since we haven’t seen either of these nodes before, we will add them into our queue and our set.
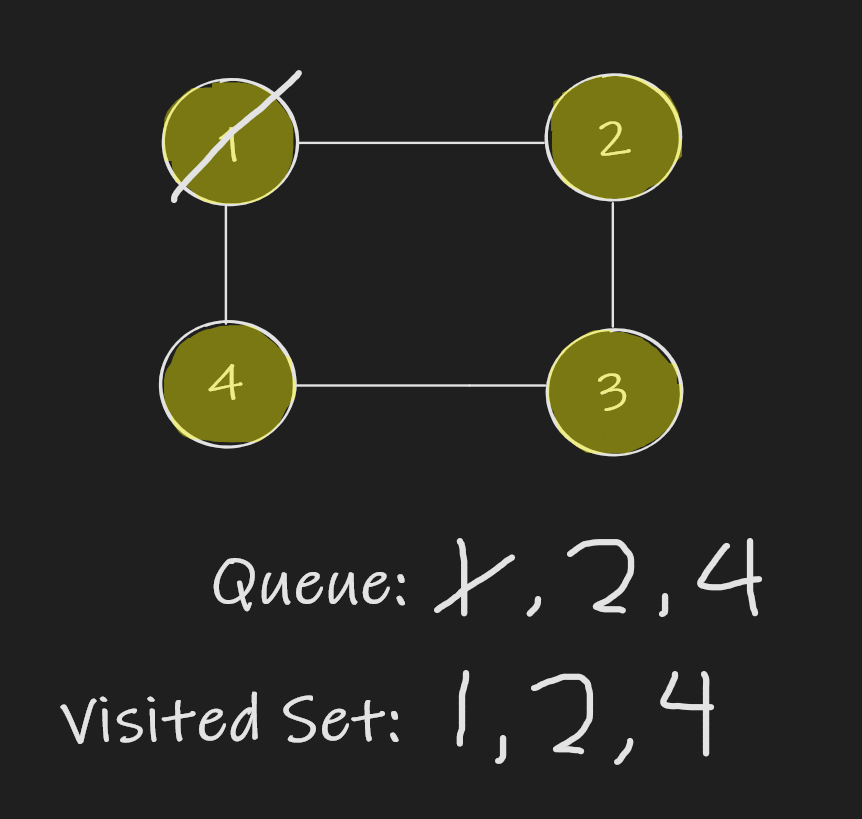 Exploring Node 1 in the BFS algorithm
Exploring Node 1 in the BFS algorithm
Continuing on, we start processing the next node in our queue.
- We remove Node 2 from the queue and process its neighbors: Node 1 and Node 3.
- Since Node 1 is in our visited set, we don’t want to revisit it again however we will add Node 3 into our visited set and queue.
 Exploring Node 2 in the BFS algorithm
Exploring Node 2 in the BFS algorithm
Continuing on, we will:
- Process Node 4 and its neighbors Node 1 and Node 3.
- Both neighbors are in the visited set, so we won’t put them in the queue.
 Exploring Node 3 in the BFS algorithm
Exploring Node 3 in the BFS algorithm
Note: I also want to point out the ordering that we are traversing the graph, we started at 1, then went to its neighbor 2, and then after that we went to its other neighbor 4. This is how a queue allows us to run a BFS algorithm. If we want to do DFS we would use a stack.
Finally to complete this example:
- Remove Node 3 from queue and then look at its neighbors: Node 2 and Node 4.
- Both are in the visited set so we won’t do anything.
 Exploring Node 4 in the BFS algorithm
Exploring Node 4 in the BFS algorithm
At this point, our queue is now empty and we have completed the BFS algorithm.
Adapting the algorithm to the problem
In this problem we will follow the same algorithm, however we will need to make an extra modification.
When we traverse through our graph, we need to make a clone of each of the nodes that we encounter so we can recreate our graph.
We need to keep track of all the nodes we created so we don’t recreate them. To accomplish this we can put them in a map where we use the value of the Node as the key and the deep copy as the value.
We can complete our algorithm with those 3 datastructures: our map of cloned modes to reference, our queue, and our visited set. However An optimization that we can use is to use this map as our visited set!
Whenever we make a clone of the node, it’ll be the first time we see it. In each of those instances when we are processing a neighbor node, we would add the node to both the map and the set. Why not just remove the set?
Runtime and Space Complexity
Runtime
The runtime of this algorithm is O(V + E), V represents all the nodes that we are visiting and E represents all the edges that exist between each node.
Note: An edge is a link between two nodes
Space Complexity
The worst case space complexity of this algorithm is O(N). While our queue might not store all the nodes in the graph, our visited set will store everything to prevent us from processing the same node twice.
Implementation
class Solution {
public Node cloneGraph(Node node) {
if (node == null) {
return null;
}
Queue<Node> queue = new LinkedList();
Map<Integer, Node> cloneMap = new HashMap();
queue.add(node);
cloneMap.put(node.val, new Node(node.val));
while (!queue.isEmpty()) {
Node cur = queue.remove();
Node clone = cloneMap.getOrDefault(cur.val, new Node(cur.val));
cloneMap.put(cur.val, clone);
for (Node child : cur.neighbors) {
Node childClone = cloneMap.getOrDefault(child.val, new Node(child.val));
clone.neighbors.add(childClone);
if (!cloneMap.containsKey(child.val)) {
queue.add(child);
}
cloneMap.put(child.val, childClone);
}
}
return cloneMap.get(node.val);
}
}
Conclusion
The key lesson to be taken away from solving the Clone Graph problem is to know how to apply a BFS algorithm.
Graph algorithms are very important to know, because of how common they are in interviews. They might seem scary forcing you to figure out connections between multiple data points.
Sometimes the problems themselves might not even mention a graph relationship. However, once you have identified that the interview problem is a graph, you’ll realize there are only a few key algorithms that you’ll need to know to be able to solve most coding problems!
The post Learn Breadth First Search Graph Traversal with Clone Graph appeared first on Leet Dev.

