Here we look at how to highlight objects on the screen. We also note that not every object detected is something we want to alert the user to.
This is the third entry in a series of articles on real-time hazard detection using TensorFlow Lite on Android. In the previous entry, we added a trained model to an Android project and created a user interface for passing images into it.
The information passed from a TensorFlow Lite model is an array of numbers. These numbers are not very meaningful by themselves. For our purposes, we do not need all of the information that is passed out of the model. The model outputs three multidimensional arrays. The last of these arrays contain the information that we want. The last array has five dimensions. The size of each dimension is [1][13][13][3][85]. The elements in the array are floats.
This implementation of YOLO divides an image into 13 columns and 13 rows. Each cell within a row or columns is 32 by 32 pixels. Within each one of these cells, YOLO will identify up to three objects. With this knowledge, you can easily infer the meaning of the two dimensions of size 13 (column, and row) and the dimension of size 3 (for each of the three identified objects).
The last dimension, of size 85, requires a more detailed explanation. The first four elements in this array define a bounding box (X, Y, Width, Height). The fifth element contains a value between zero and one that indicates confidence in this box containing a match. The next 80 elements contain the probabilities for the match being for one of the 80 elements that this YOLO model recognizes. The position with the highest value is the one that will be assigned to the object.
Identifying Objects
This model also came with a labels file. To identify the object that a position identifies, we can look at the line number that matches the object index. The first element in these 80 elements is for the object identified in the first line of the labels file. The second element in these 80 elements is for the second line of the text file, and so on. If you use a YOLO model that was built using a different training set, it may have a different size on this dimension. Using this information, we can now draw bounding boxes around the objects found within an image.
There are a few methods for rendering outlines to the screen. The method I’ve chosen is to make a View-based class and override its onDraw method. In the onDraw method, the view receives a Canvas for rendering. The Canvas passed to this method has the advantage of being backed by the hardware capabilities. Obtaining a Canvas through other methods, such as by creating a Bitmap, results in a Canvas that uses only software rendering.
Most of this view will render transparently. By positioning it over the view that is displaying the image being processed, additional information can be displayed with the image.
class InfoOverlayView(context: Context?, attr: AttributeSet?) :
View(context, attr) {
public enum class HighlightType(val highlightType: Int) {
Warning(0x01),
Attention(0x02)
}
var warningPaint: Paint
var attentionPaint: Paint
var highlightList: MutableList<Rect>
var attentionList: MutableList<Rect>
public override fun onDraw(canvas: Canvas) {
super.onDraw(canvas)
for(r in attentionList) {
canvas.drawRect(r, attentionPaint)
}
for (r in highlightList) {
canvas.drawRect(r, warningPaint)
}
}
public fun clear() {
highlightList.clear()
attentionList.clear()
invalidate()
}
public fun addHighlight(area:Rect, type:HighlightType) {
when(type) {
HighlightType.Warning -> highlightList.add(area)
HighlightType.Attention->attentionList.add(area)
}
invalidate()
}
init {
warningPaint = Paint()
warningPaint.color = -0x7f010000
warningPaint.style = Paint.Style.STROKE
warningPaint.strokeWidth = 16f
attentionPaint = Paint()
attentionPaint.color=0x7fFFFF00
attentionPaint.style = Paint.Style.STROKE
attentionPaint.strokeWidth = 16f
highlightList = ArrayList()
attentionList = ArrayList()
}
}
When we want to highlight an area, we can define the area with a Rect and pass it to the addHighlight method. This method lets us mark a region for either a warning (rendered in red) or something to which we are bringing attention (rendered in green). Anytime a rectangle is added to the View, the View marks itself as needing to be rerendered by calling invalidate.
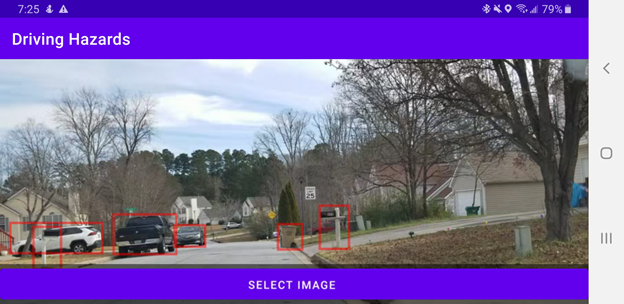
We can now show the recognition results on the screen to the user. But we may not want to warn the user of every single object that the detector recognizes. For example, the detector can recognize other vehicles. Vehicles are expected to be on a road and should not trigger any warning. There are also objects that don’t represent hazards because they aren’t in the vehicle’s path.
The interface will not rely only on visuals to give feedback to the user. It would be good if the user could receive audio warnings so that they do not need to take their eyes off of the road. In the next entry of this series, we will look at how we can avoid unnecessarily warning the user, and how we can quickly alert them.

