In this article series, we'll learn how to easily train a face mask detector and (optionally) deploy it on a Raspberry Pi board + Coral USB accelerator. Here, we'll talk about the different approaches you can take to create a face mask detector.
Introduction
In this series of articles, I’ll walk you through a crucial task that most machine learning (ML) specialists will have to deal with at some point in their careers: computer vision. Even if it sounds like rocket science, it’s not! Also, even though we’ll be focusing on a face mask detector, the same process can be applied to any other similar task.
You’ll need to have some Python, Linux CLI and ML knowledge. I’ll be stacking layers of concepts while I guide you through the project itself. It might become heavy at some point, but as developers, we can figure out anything!
Even with COVID-19 vaccines on the horizon, the pandemic is still a serious issue. We need to deal with it, especially when some individuals do not comply with the minimal requirements to avoid contagion, such as keeping social distance or wearing face masks. Artificial Intelligence (AI) could be a huge help to ensure people are at least wearing face masks. Can AI accomplish this task for us? Moreover, is it possible to deploy an AI face mask detector on a Raspberry Pi or similar inexpensive, portable computer?

The answer is yes.
You need two things to make the solution work: plenty of data and lots of computing power. Luckily for us, thanks to important advances in artificial neural networks and deep learning, as well as huge improvements in computing capabilities, we can train the required kind of deep learning models. Additionally, the training data we'll need is readily available.
Don’t worry if your computer has mediocre hardware capabilities. I’ll stay focused on coding this project in such a way that you can implement it with an average computer. We’ll work on cloud-hosted Jupyter Notebooks, and will use a local computer for light tasks only. With that said, let’s dive in!
AI Face Mask Detection Techniques
There are several ways to get a fully functional, state-of-the-art object detector today, from very complex developments made for extremely particular requirements, to more general but still good model implementations. You could design an entire architecture from scratch, made up of several complex layers, or simply use a pre-trained model that will achieve very similar results at the end of the project as well.
In the majority of real-life implementations, you’ll have limited time to build up your AI solution. I‘ll bring up a couple of different solutions at a time, give you a brief intro to both, and explain how they work even though I keep only one of them. I’ll provide you with enough information about the other one in case you want to explore it further.
I’ll begin with a common solution many developers use because of its inference speed, versatility, and good documentation: Keras + MobileNet V2 + OpenCV.
Combining Keras, MobileNet V2, and OpenCV to Implement a Model
Here is a brief summary of this mix. As you may know, Keras is a user-friendly and powerful deep learning framework with TensorFlow as its backend engine (usually referred to as a TensorFlow abstractions API). It’s easy to use and deploy, lightweight, and it can be implemented for almost any task in the machine learning industry. If you like to keep things simple, add Keras to your skillset. In our case, it will help us build a strong foundation of the object detector itself.
MobileNet will do the heavy lifting. It’s a model developed by Google. Its first version appeared back in 2017, and contributed a lot to the evolution of computer vision.
The MobileNet architecture is rather complex. I would need an entire article to explain what it has under the hood. V2 is still used in several applications, and works better than MobileNet V1 and the classic ConvNets. This is because it uses computationally cheaper convolutions that later versions of MobileNet, but still contains important architecture improvements over older networks.
When implementing the MobileNet V2 architecture, the preprocessing step is similar to the classic image classification pipeline:
- Gather images each of which contains only one object (in this case, only one face per image). This is because this architecture won’t understand the coordinates used, for example, by YOLO.
- Make all images the same size.
- Augment the dataset with the Keras
ImageDataGenerator (or any similar method). - Convert all images into NumPy arrays and express labels in binary notation (at least in this case, a binary classification).
Let’s use a regular ConvNet architecture to build this network, and replace the convolutional layers stack with the MobileNet stack:
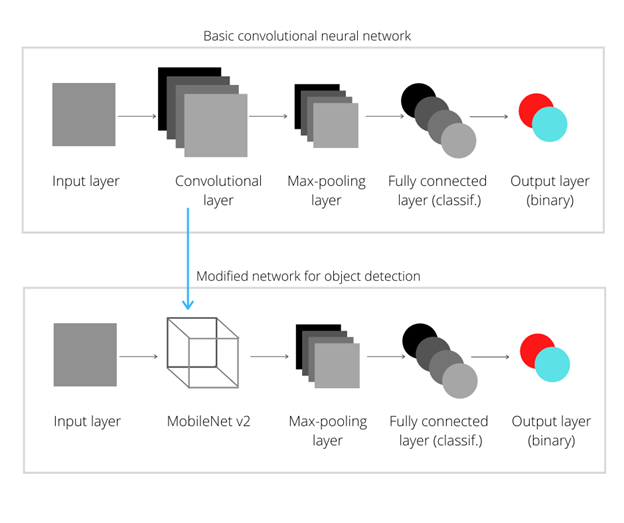
A basic convolutional neural network (CNN) has four major components: the convolutional layer, the max-pooling layer, densely connected layer and finally an output layer. The densely connected one performs the actual classification task and activates the perceptron in the output layer that corresponds to the predicted value.
Conv2D (convolution task) and MaxPooling2D (max-pooling task) layers work together fantastically for simple image classification tasks. However, when real-time detection is required, the convolution operation is extremely expensive and makes this process annoyingly slow, even more so on edge devices. The solution? Replace the Conv2D layer with a faster stack: the MobileNet V2 model. It is very efficient in comparison with a CNN, uses fewer parameters, but has the disadvantage of being less accurate. For our project, the results achieved with MobileNew V2 should be sufficiently accurate. This, however, is a tradeoff; you’ll still have to deal with hyper-parameter tuning, activation functions, optimizer, loss function, and the script to handle the real-time detections on a webcam.
OpenCV would be a huge help when dealing with images, video, and camera. Why am I not taking this approach? In this particular scenario, we would need two models running at the same time on the same image/video: a model detecting faces (there are several options for this out there) and a model deciding whether or not that face is wearing a face mask (in this case, MobileNet). On a regular computer, the inference speed wouldn’t be a problem. However, if we tried to run it on an edge device, we would get extremely low performance. My recommendation is to take the above path if you don’t need to run your model on small devices.
With that said, let’s check out the smartest solution.
YOLOv5
It’s time to talk about one of the most powerful and easy-to-use object detection models available nowadays. I’ll walk you through a how-to guide on how to generate training data for it, train it, test it, and deploy it. You can find the whole notebook here. I’ll explain later on how it’s organized.
As you may know, the YOLOv5 models have been available for several months now, and have gained a lot of popularity because of their previous versions. These ones are faster, more efficient but also their documentation is fantastic, they are very straightforward to train and deploy, and the way you label data for their training is very simple.
If you use its most recent and lightest model (YOLOv5s), you will have high detection speed at low computing cost. If I still haven’t sold you on this idea, here is one more reason: you won’t need two models like you would when using MobileNet. With YOLOv5, you only use a single model. You won’t believe how simple it is to get a fully trained and totally deployable object detection model!
Next Step
In the next article of this series, I’ll show you how to collect, preprocess, and augment the data required for our model training. Stay tuned!
History
- 25th January, 2021: Initial version

