Here we’ll go deeper into anomaly detection on time-series data and see how to build models that can perform this task.
Introduction
This series of articles will guide you through the steps necessary to develop a fully functional time series forecaster and anomaly detector application with AI. Our forecaster/detector will deal with the cryptocurrency data, specifically with Bitcoin. However, after following along with this series, you’ll be able to apply the concepts and approaches you’ve learned to any data type of similar nature.
To fully benefit from this series, you should have some Python, Machine Learning, and Keras skills. The entire project is available in my "GitHub repository. You can also check out the fully interactive notebooks here and here.
In the previous article, you learned how to prepare time series data to be fed to machine learning (ML) and deep learning (DL) models. In this article, I’ll explain how to detect anomalies in this kind of data.
Understanding Anomalies
You might be wondering what is an anomaly? How could you detect it? Is it actually possible to detect anomalies in scenarios that haven’t played out yet? Anomaly is a popular term that refers to something irregular. In statistics, anomalies are often referred to as outliers – infrequent or unexpected events in a data collection. If the distribution of the dataset is approximately normal then anomalies would be all those data points that are 2 standard deviations from the mean.
To illustrate the concept of anomaly: a car engine’s temperature must be below 90 Centigrade, otherwise it will overheat and break down. The engine’s refrigeration system keeps the temperature in the safe range; if it fails, you could notice really high temperature values. Mathematically, you’d have values under 90 for a long period of time, then the values suddenly peak to150 until your engine collapses. Visually, this is what I mean:
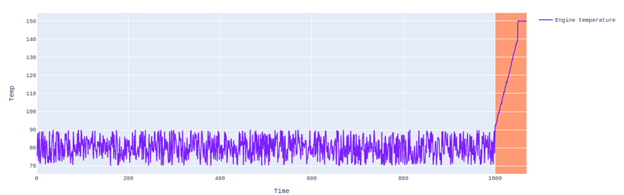
You’d see data points between 70 and 90 Centigrade, but suddenly different values at the end of the chart break the pattern (the ones highlighted). These latter observations are outliers and, therefore, anomalies. The above graph shows a pattern that describes an anomaly.
Anomaly Detection from the AI Perspective
Now you know what an anomaly is - how do you detect it? As you may infer anomaly detection is the process of identifying the unexpected items or events in a data collection – those that occur very rarely. Anomaly detection comes in two flavors. One is the univariate anomaly detection which is the process of identifying those unexpected data points for a distribution of values in a single space (single variable). The other one is the multivariate anomaly detection, where an outlier is a combination of unusual scores of at least two variables.
I’ll focus these series on univariate anomaly detection. However, please note that the same approach can work as a baseline for more complex models, designed to detect anomalies in multivariate contexts.
Detecting Anomalies with K-Means Clustering
If you’ve checked the recommended datasets already, you’d have noticed that they aren’t labeled at all, meaning that it’s not yet clear what’s an anomaly and what’s not. This is the typical scenario you’ll have to deal with in real-world cases. When you face an anomaly detection challenge, you’ll have to gather the data coming directly from the source and apply certain techniques to discover anomalies. This is exactly what we’re going to do with some help from unsupervised learning. Unsupervised learning is a type of ML where the model is trained on unlabeled data in order to discover patterns. In theory, it doesn’t require human intervention to group the data and, therefore, identify anomalies — if that’s the requirement.
Keep in mind that K- Means Clustering is extremely simple – one of the simplest ones nowadays – but you’ll see how useful it can be. K-Means Clustering is an algorithm that groups similar data points and finds out underlying patterns that are not obvious to a naked eye. K – the number of centroids –defines how many groups or clusters must be identified in a given dataset. A cluster as a collection of data points with similarities. A centroid is, mathematically, the center of a cluster.
The algorithm starts the data processing by randomly selecting K centroids, which are the starting points for every cluster, and then iteratively makes calculations to optimize the centroid positions. Once the clusters have been identified, the algorithm allocates every single data point to the closest cluster, and adds the corresponding label to every observation.
Let’s visualize this with a basic example. TSuppose that you have X random values that plot like this:

You can easily identify two clusters:
And that’s what the K-Means Clustering algorithm does, in a nutshell. Now let’s see how this algorithm works on our dataset. Issue the next commands:
outliers_k_means = pano.copy()[51000:]
outliers_k_means.fillna(method ='bfill', inplace = True)
kmeans = KMeans(n_clusters=2, random_state=0).fit(outliers_k_means['Weighted_Price'].values.reshape(-1, 1))
outlier_k_means = kmeans.predict(outliers_k_means['Weighted_Price'].values.reshape(-1, 1))
outliers_k_means['outlier'] = outlier_k_means
outliers_k_means.head()
You’ll get the first five rows of the resulting dataframe:
In the above table, every row with 0 in the "outlier" column indicates a normal, and every one with 1 in that column - an anomaly. Let’s plot the entire dataset to see how the model identifies these values:
a = outliers_k_means.loc[outliers_k_means['outlier'] == 1]
fig = go.Figure()
fig.add_trace(go.Scatter(x=outliers_k_means['Weighted_Price'].index, y=outliers_k_means['Weighted_Price'].values,mode='lines',name='BTC Price'))
fig.add_trace(go.Scatter(x=a.index, y=a['Weighted_Price'].values,mode='markers',name='Anomaly',marker_symbol='x',marker_size=2))
fig.update_layout(showlegend=True,title="BTC price anomalies - KMeans",xaxis_title="Time",yaxis_title="Prices",font=dict(family="Courier New, monospace"))
fig.show()
The above chart fits rather well with the actual Bitcoin price reality because the last few weeks the price has been an anomaly. The algorithm clusters values above ~$13,000 as one class, and the values below this threshold – as another one.
Implementing Neural Networks and Autoencoders to Detect Anomalies on Bitcoin historical Price
Now let’s use an unsupervised learning technique with some help from Neural Networks (NN). This way is known to be much more flexible and accurate for anomaly detection.
Nowadays, NNs are the new norm because of their amazing power and great results. We’ll use them in an unusual way: we’ll utilize an LSTM (long short-term memory) NN and autoencoders to build an unsupervised learning model. The main goal of this approach is to improve the results obtained with the last model, and I plan to do so by modeling the distribution of our current dataset so as to learn more about its structure.
Generally speaking, anomaly detection problems can be addressed as classification or regression, depending on whether the dataset is labeled. What we’re going to do next is to model our dataset as a regression problem, where we’re going to quantify the reconstruction error of our network. This essentially means that we’re going to build a model that can reconstruct the normal behavior of the sequences in our dataset so a data point that has a high reconstruction error can be defined as an anomaly. The main idea to keep in mind is that frequent events are quite easy to reconstruct but the infrequent ones are not that simple. Therefore, the reconstruction error for the latter will be higher.
The Recurrent NNs – including LSTM – are specially designed to work with sequential data. They are great at remembering past data and, due to that important feature, accomplish better predictions. If you want to fully understand how they work, I recommend that you have a look at "Deep Learning with Python" by François Chollet.
Unfortunately, the LSTM network is not enough to achieve our goal, so we’ll need to add an autoencoder to our architecture. Let’s take a look at the basic autoencoder architecture:
An autoencoder is an artificial NN used to produce efficient data encodings in an unsupervised way. By doing this, the autoencoder can learn the most important features of the data collection. In our case, we’ll use its reconstruction capabilities to determine what’s an anomaly and what’s not. If it struggles with reconstructing certain observations, we can infer that these are anomalies.
By the way, I’m going to use the reconstruction loss as a means to measure how wrong a data point’s reconstruction is. What you’ll see next is the creation of an LSTM autoencoder with some help from Keras:
tsteps = X_train.shape[1]
nfeatures = X_train.shape[2]
detector = Sequential()
detector.add(layers.LSTM(128, input_shape=(tsteps, nfeatures),dropout=0.2))
detector.add(layers.Dropout(rate=0.5))
detector.add(layers.RepeatVector(tsteps))
detector.add(layers.LSTM(128, return_sequences=True,dropout=0.2))
detector.add(layers.Dropout(rate=0.5))
detector.add(layers.TimeDistributed(layers.Dense(nfeatures)))
detector.compile(loss='mae', optimizer='adam')
Now, let’s fit the model on the training set:
checkpoint = ModelCheckpoint("/kaggle/working/detector.hdf5", monitor='val_loss', verbose=1,save_best_only=True, mode='auto', period=1)
history1 = detector.fit(X_train,y_train,epochs=50,batch_size=128,verbose=1,validation_split=0.1,callbacks=[checkpoint],shuffle=False)
Nothing fancy so far except the ModelCheckpoint implementation. It saves the best model obtained during training. At the end of the process, this is what I’ve obtained (keep in mind that your results may vary slightly from these since every AI training cycle contains an element of randomness):
Epoch 50/50
157/157 [==============================] - ETA: 0s - loss: 0.0268
Epoch 00050: val_loss did not improve from 0.11903
157/157 [==============================] - 1s 7ms/step - loss: 0.0268 - val_loss: 0.1922
To load the best model obtained and evaluate it, issue these commands:
detector = load_model("detector.hdf5")
detector.evaluate(X_test, y_test)
As a result, I’ve obtained:
174/174 [==============================] - 0s 3ms/step - loss: 0.0579
This is not bad at all. Now it’s time to set a static threshold, which is the simplest way to define whether or not a data point is an anomaly. In our case, any error higher than this threshold will be considered an outlier. We’re going to get the MAE loss for the training and test sets and visually determine what would be the appropriate threshold:
X_train_pred = detector.predict(X_train)
loss_mae = np.mean(np.abs(X_train_pred - X_train), axis=1)
sns.distplot(loss_mae, bins=100, kde=True)
X_test_pred = detector.predict(X_test)
loss_mae = np.mean(np.abs(X_test_pred - X_test), axis=1)
sns.distplot(loss_mae, bins=100, kde=True)
As you can see in the above charts, observations higher than 0.150 become unusual but in some other scenarios this task is not as simple. For that reason, it's often best to use statistics to identify this value with more precision. Let's set that number as the threshold and determine what value is above it, so that we can plot the anomalies:
threshold = 0.15
test_df = pd.DataFrame(test[tsteps:])
test_df['loss'] = loss_mae
test_df['threshold'] = threshold
test_df['anomaly'] = test_df.loss > test_df.threshold
test_df['Weighted_Price'] = test[tsteps:].Weighted_Price
anomalies = test_df[test_df.anomaly == True]
yvals1 = scaler.inverse_transform(test[tsteps:][['Weighted_Price']])
yvals1 = yvals1.reshape(-1)
yvals2 = scaler.inverse_transform(anomalies[['Weighted_Price']])
yvals2 = yvals2.reshape(-1)
fig = go.Figure()
fig.add_trace(go.Scatter(x=test[tsteps:].index, y=yvals1,mode='lines',name='BTC Price'))
fig.add_trace(go.Scatter(x=anomalies.index, y=yvals2,mode='markers',name='Anomaly'))
fig.update_layout(showlegend=True,title="BTC price anomalies",xaxis_title="Time",yaxis_title="Prices",font=dict(family="Courier New, monospace"))
fig.show()
This plot shows the anomalies in the test set:
The anomalies look promising. Let’s take a look at the entire dataset and plot the existing anomalies on it:
scaled_pano = test.append(train, ignore_index=False)
X_shifted, y_shifted = shift_samples(scaled_pano[['Weighted_Price']], scaled_pano.columns[0])
X_shifted_pred = detector.predict(X_shifted)
loss_mae = np.mean(np.abs(X_shifted_pred - X_shifted), axis=1)
non_scaled_pano = pano.copy()[51000:]
non_scaled_pano.fillna(method ='bfill', inplace = True)
non_scaled_pano = non_scaled_pano[:-24]
non_scaled_pano['loss_mae'] = loss_mae
non_scaled_pano['threshold'] = threshold
non_scaled_pano['anomaly'] = non_scaled_pano.loss_mae > non_scaled_pano.threshold
pano_outliers = non_scaled_pano[non_scaled_pano['anomaly'] == True]
fig = go.Figure()
fig.add_trace(go.Scatter(x=non_scaled_pano.index, y=non_scaled_pano['Weighted_Price'].values,mode='lines',name='BTC Price'))
fig.add_trace(go.Scatter(x=pano_outliers.index, y=pano_outliers['Weighted_Price'].values,mode='markers',name='Anomaly'))
fig.update_layout(showlegend=True,title="BTC price anomalies - Autoencoder",xaxis_title="Time",yaxis_title="Prices",font=dict(family="Courier New, monospace"))
fig.show()
And as you can see, the results match our expectations because the highlighted prices are very rare in the chart and also Bitcoin's entire price history (to see the Bitcoin historical price please check here). We'll keep this model as our anomaly detector for the rest of this series.
Next Step
In the next article, we are going to discuss forecasting on Bitcoin time series. Stay tuned!

