In this post, we discuss the data subset to be used, as well as formulate the problem.
Introduction
Fashion is big business. Whether sold online or in a physical store, clothing is one of the largest drivers of retail sales.
The availability of datasets like DeepFashion open up new possibilities. Imagine having an AI-powered classifier that stores could use to identify what people entering the store are wearing.
This information could be used passively, to gather aggregate intelligence on what kinds of clothing shoppers typically wear. Or, it could be used actively. For example, a fashion detector could alert sales staff whenever a customer enters the store wearing a dress or a suit. Since this person is already wearing upscale, high-value clothing, they’re more likely to spend more money in the store today.
The first step in making all this possible is an effective and accurate classifier model. In this series of articles, we’ll showcase an AI-powered deep learning system that can revolutionize the fashion design industry by helping us better understand customers’ needs.
In this project, we’ll use:
- Jupyter Notebook as the IDE
- Libraries
- A custom subset of the
DeepFashion dataset — relatively small to reduce the computational and memory overhead
We are assuming that you are familiar with the concepts of deep learning, as well as with Jupyter Notebooks and TensorFlow. If you’re new to Jupyter Notebooks, start with this tutorial. You are welcome to download the project code.
Data Subset
The DeepFashion dataset is a large-scale clothes database, which has several appealing features: Clothing Category and Attribute Prediction, In-shop Clothes Retrieval Benchmark, Consumer-to-Shop Clothes Retrieval Benchmark, and Fashion Landmark Detection Benchmark, collected by the Multimedia Lab at the Chinese University of Hong Kong. However, for our project, we’ll use only the Category and Attributes Prediction dataset because we’re going to work on detecting and classifying clothing in existing images, and even generating new similar images. To follow along, download the dataset.
Category and Attributes Prediction is a huge dataset that contains images of clothes segregated into highly specific categories by different attributes. For example, blouses with sleeves are considered different from sleeveless ones.
For this project, we made our own data subset, reducing the volume of images and category specificity, for simplicity and lower computation costs. We reduced our classification from DeepFashion’s original 46 categories to 15 categories. Then, we selected 500-700 images from each of our simplified categories, as seen in the figure below:
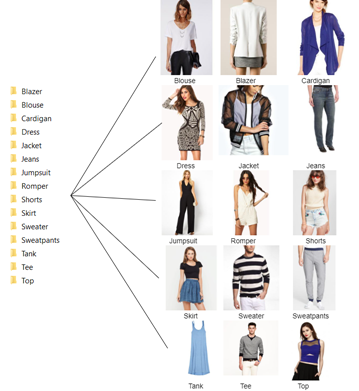
The customized dataset can be downloaded here.
The Problem Statement
An AI-powered deep learning system in the fashion industry can detect, recognize, and then recommend or generate new designs. Classification of clothes can be done by a deep network trained on images of the different garment types. Deep networks can also be trained to predict the attributes of clothes, and detect individual clothing items. Real images will depict people wearing multiple types of clothing. For example, someone might be wearing jeans, a shirt, and a jacket. It is better to have a robust system that can detect all these items at once. The neural network can be trained to detect one or more types and send each detected part to the network to be classified into one of the clothing categories.
Furthermore, deep networks can become fashion design recommenders or generators: you can train them to generate new images of clothes using a Generative Adversarial Network (GAN). A GAN uses a training dataset, such as a large database of photos, to learn how to generate new, realistic data.
In the following articles of this series, we’ll see how some of the above tasks can be implemented and applied to real-life images.

Next Steps
In the next article, we’ll show you how to use transfer learning to fine-tune the VGG19 model to classify fashion clothing categories. Stay tuned!
History
- 15th March, 2021: Initial version

