In this article series, we're going to show how deep fakes work, and show how to implement them from scratch. We'll then take a look at DeepFaceLab, which is the all-in-one Tensorflow-powered tool often used for creating convincing deep fakes.
Introduction to Deep Fakes
Deep fakes - the use of deep learning to swap one person's face into another in video - are one of the most interesting and frightening ways that AI is being used today.
While deep fakes can be used for legitimate purposes, they can also be used in disinformation. With the ability to easily swap someone's face into any video, can we really trust what our eyes are telling us? A real-looking video of a politician or actor doing or saying something shocking might not be real at all.
In this article series, we're going to show how deep fakes work, and show how to implement them from scratch. We'll then take a look at DeepFaceLab, which is the all-in-one Tensorflow-powered tool often used for creating convincing deep fakes.
Learn how to create DIY deep fakes models, how to train them on containers in the Cloud, and how to use DeepFaceLab as an alternative to your own model.
Deep fakes are one of the most stunning applications of modern AI. The ability to complete — and believably — replace one person's face with another in a video is a visceral demonstration of what AI can do.
Thus far, most discussion of deep fakes has been negative. Imagine a realistic video of a politician or actor doing or saying something that isn’t real at all — the ideal scenario for viral and potentially dangerous fake news. This is the reason deep fakes have gained mainstream awareness.
Fortunately, not all deep fake applications are bad. Deep fakes can be used as an alternative to CGI for movie productions to de-age actors in flashback scenes, or to add now-deceased actors to new movies. Think of how Moff Tarkin played a prominent role in Rogue One even though the actor who played him in the original Star Wars movie died in 1994, or how Luke Skywalker looked younger in the Mandalorian despite the actor’s real age. Deep fake techniques can even correct the actor’s mouth movement when a movie is translated to a different language.
These tasks have traditionally been very expensive. It would normally require a CGI team and several months to achieve it. Now, with help of artificial intelligence and some Cloud AIOps expertise, you can achieve great results at a lower cost.
This series of mini-articles will show you the foundations of building deep fake models and implementing them so you can get good looking videos without spending a few million dollars on a team of CGI experts.
To get the most out of the series, you'll need basic knowledge of Python, deep learning, and computer vision. It's okay if you're not an expert. Throughout the series, I'll try to explain the concepts we're covering and provide links where you can find additional information. I’ll be stacking layers of concepts as we move forward so you can become familiar with the terms we discuss.
Understanding the Concepts Behind Deep Fakes
Though creating a deep fake may sound like an easy swapping of faces, it’s not that simple. There are several crucial and complex steps that are not so obvious. In addition, there are many flavors of deep fakes: de-aging a person, making someone say something new, and inserting someone’s face onto the head of somebody else are a few examples.
We’ll break down all these ideas and understand what they have in common, but let’s first properly define what a deep fake is. As you may have inferred, "deep fake" is a combination of the terms "deep learning" and "fake", it uses artificial intelligence to produce falsified videos and is not limited to swapping faces. It can be used to, for example, transform horses into zebras in a video.
This article series will provide you with several code examples. The notebooks and files used in these article series in my GitHub repo and all the fully interactive Kaggle and Colab notebooks:
And you can find the trained models are here:
Deep Fakes General Overview
In general, you need at least two videos to create a deep fake: One of them would be the source video and the other one would be the destination video (there are cases where you may want to use only one video that contains more than one individual and swap their faces, but that’s outside of the scope of this article). Using face swapping as an example, the first video would contain the individual you want to take some facial gestures from, and the second video would contain the actual face appearance you want to use.
We need to extract all the images that compose each video frame, a process known as frame extraction. The purpose of this process is to extract faces from those images (face extraction) to train the deep fake models (Yes, two models. I’ll explain the reason later). Once we have all faces already extracted, we’ll use that faceset (dataset of faces) for models’ training. We’ll then use them together with our frames and facesets to perform the face swapping, which is inserting the generated faces into the original frames. Finally, we’ll need to merge the frames to make the video and obtain a deep fake.
The next chart describes this process using autoencoders as deep fake generators (I’ll go deeper on this later on the article), and it’s the approach we’ll be following. Don’t worry if you don’t know what all the elements are yet. I’ll explain the details you’ll need to understand their functions and how to code them, as well as indicate which step we're at:
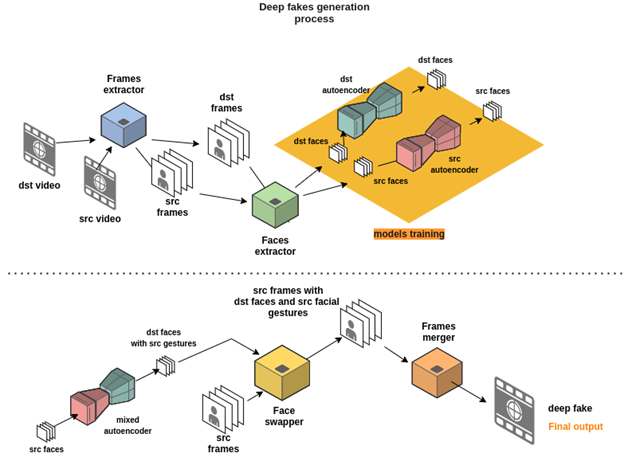
In the first chart (the one at the top), you’ll notice that the frame extractor is supplied with raw videos. These contain the faces we’re going to swap. Next, it delivers the frames of these videos to the faces extractor, which will process every frame as a regular image and extract the faces it encounters within them. This is where we obtain our actual face sets that we'll feed into our models for training. To keep things simple, we will train one of these models on the destination faceset and the other one on the source faceset.
Once training has ended, we mix the input block of the "source" model with the output block of the "destination" model and feed them with "source" faces to finally obtain "destination" faces with "source" facial gestures.
In the second chart in the diagram above, the face swapper uses the outputs of the mixed model to insert those newly generated faces over the original faces in their corresponding video frames. Finally, the frame merger reassembles those frames to get our deep fake video. Keep in mind that you can set things up slightly differently depending on what you want to achieve. For instance, you could swap only a portion of the face, the whole face, or the entire head.
In the next article, I’ll explain the different options we can choose from to create deep fakes. See you there!

