Here, we create a container to run predictions on a trained model. We run a ML inference using a Docker container.
Introduction
Container technologies, such as Docker, significantly simplify dependency management and portability of your software. In this series of articles, we explore Docker usage in Machine Learning (ML) scenarios.
This series assumes that you are familiar with ML, containerization in general, and Docker in particular. You are welcome to download the project code.
In the previous article, we created a basic container for experimentation and training. In this one, we’ll create a container to run predictions on a trained model.
Why a Separate Container for Inference?
In theory, we could use our previous experimentation container for production inference. The recommended approach though is to keep the image as simple and small as possible. This means getting rid of any components not required for the inference, such as redundant packages, Jupyter Notebook, or build tools (if we had any included).
Dependencies
While our experimentation image in the previous article contained multiple ML libraries, we have trained our model using TensorFlow. Therefore, we can trim our requirements.txt as follows:
numpy==1.19.5
opencv-python==4.5.1.48
tensorflow-cpu==2.4.0
NumPy is added here to only pin it to a specific version (a different version could be installed as TensorFlow dependency). Unfortunately, too often an update to a Python library introduces breaking changes or bugs. Adding explicit requirements with fixed versions – even for indirect dependencies – helps avoid headaches when recreating an environment.
Dockerfile
Most of our Dockerfile is the same as it was in the previous article:
FROM python:3.8.8-slim-buster
ARG DEBIAN_FRONTEND=noninteractive
RUN apt-get update \
&& apt-get -y install --no-install-recommends ffmpeg libsm6 libxext6 \
&& apt-get autoremove -y && apt-get clean -y && rm -rf /var/lib/apt/lists/*
ARG USERNAME=mluser
ARG USERID=1000
RUN useradd --system --create-home --shell /bin/bash --uid $USERID $USERNAME
COPY requirements.txt /tmp/requirements.txt
RUN pip3 install --no-cache-dir -r /tmp/requirements.txt \
&& rm /tmp/requirements.txt
USER $USERNAME
WORKDIR /home/$USERNAME/app
Because we still use opencv-python, we need to keep the apt-get statements to install system components.
The last two lines are the only ones that are different from the previous version:
COPY app /home/$USERNAME/app
ENTRYPOINT ["python", "predict.py"]
First, we copy our application code to the image. The copied app folder contains both the inference code and the model we have trained in the previous article. Such a COPY statement is usually one of the last statements in the Dockerfile, which ensures that only a few top layers need to be recreated when the application code changes.
Next, we define ENTRYPOINT for our application. It is sort of a prefix for any command that will be executed when the container starts. Any CMD statement added using Dockerfile or the docker run command will be added as arguments to the ENTRYPOINT statement.
Building and Running Container
After downloading our application code and data, you can build the image as mld03_cpu_predict (don’t forget the dot (.) at the end):
$ docker build --build-arg USERID=$(id -u) -t mld03_cpu_predict .
On Windows, you can skip the --build-arg USERID part:
$ docker build -t mld03_cpu_predict .
After the image is built, we run the inference:
docker run -v $(pwd)/data:/home/mluser/data --rm --user $(id -u):$(id -g) mld03_cpu_predict
--images_path /home/mluser/data/test_mnist_images/*.jpg
On Windows:
docker run -v $(pwd)/data:/home/mluser/data --rm mld03_cpu_predict
--images_path /home/mluser/data/test_mnist_images/*.jpg
Please note that --images_path above is an argument for our application included in the container. It is appended to the command defined by the ENTRYPOINT statement in the Dockerfile. We map only the folder with the data this time, relying on the app code (and trained model) embedded in the image.
The expected outcome is as follows:
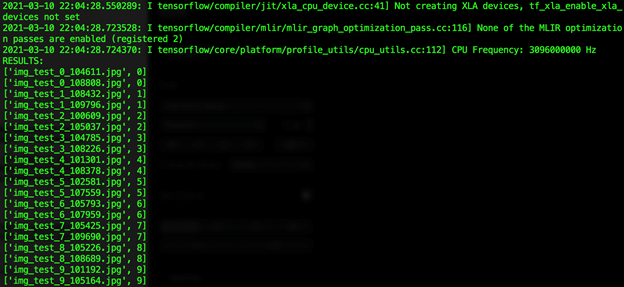
Using the expected value included in each file name (the digit following "test_"), we can confirm that all predictions for our limited dataset are correct.
Summary
In this article, we run an ML inference using a Docker container. In the next article, we’ll adapt this image for Raspberry Pi with an ARM processor.

