Here we run training and inference using Docker containers with the GPU support.
Introduction
Container technologies, such as Docker, significantly simplify dependency management and portability of your software. In this series of articles, we explore Docker usage in Machine Learning (ML) scenarios.
This series assumes that you are familiar with ML, containerization in general, and Docker in particular. You are welcome to download the project code.
In the previous article, we created basic containers for experiments, training, and inference. To do so, we used Intel/AMD and ARM CPUs. In this one, we’ll leverage the power of Nvidia GPU to reduce both training and inference time.
Preparing Docker Host to Use Nvidia GPU
To use GPU from Docker, we need a host with Nvidia GPU and Linux (since December 2020, the GPU support also works on Windows via Windows Subsystem for Linux (WSL2)). In the cloud, all you need to do is select a proper VM size and OS image. For example, NC6 and Data Science Virtual Machine with Ubuntu 18.04 on Azure.
Depending on the Linux distribution and GPU model, configuration on a local machine can be more demanding:
- Ensure you have Nvidia GPU drivers installed on your host.
- Install nvidia-container-runtime appropriate for your distribution.
- Restart the Docker daemon.
Now you should be able to run a container with the --gpus attribute; for example, using only the first GPU:
$ docker run --gpus "device=0" nvidia/cuda:11.2.1-runtime nvidia-smi
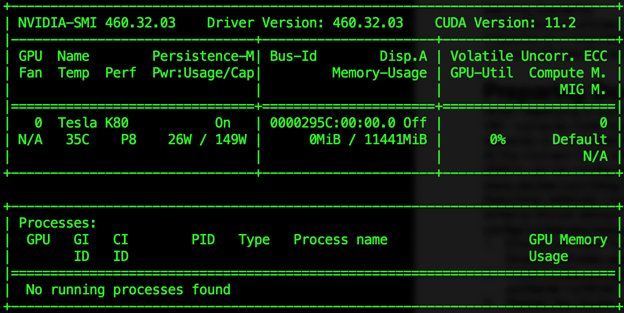
It is important to use the same CUDA version in the host and the container (11.2 in our case). If the versions don’t match, the container will fail to start with an error like "unsatisfied condition: cuda>=11.0."
Prediction Dockerfile
We suggest that you always start with the smallest base image available for a given task, usually suffixed "runtime." While the "devel" suffix may seem more appropriate, the images it denotes contain a lot of tools not needed in most ML scenarios.
It may be tempting to use a base image provided by Nvidia (e.g., nvidia/cuda:11.2.1-runtime mentioned above), install Python and our libraries there, and be done. Unfortunately, this won’t work, at least not with TensorFlow. We can either follow the provided step-by-step instructions or use the official, recommended Tensorflow Docker image.
We’ll go with the latter option. Apart from the FROM statement, the rest of the new prediction Dockerfile is the same as the one we’ve used for the CPU-only version:
FROM tensorflow/tensorflow:2.3.2-gpu
ARG DEBIAN_FRONTEND=noninteractive
RUN apt-get update \
&& apt-get -y install --no-install-recommends ffmpeg libsm6 libxext6 \
&& apt-get autoremove -y && apt-get clean -y && rm -rf /var/lib/apt/lists/*
ARG USERNAME=mluser
ARG USERID=1000
RUN useradd --system --create-home --shell /bin/bash --uid $USERID $USERNAME
COPY requirements.txt /tmp/requirements.txt
RUN pip3 install --no-cache-dir -r /tmp/requirements.txt \
&& rm /tmp/requirements.txt
USER $USERNAME
WORKDIR /home/$USERNAME/app
COPY app /home/$USERNAME/app
ENTRYPOINT ["python", "predict.py"]
Note that we use TensorFlow version 2.3.2, not 2.4.1 as before. The main reason for this is that the official Docker image for version 2.4.1 is much larger (>5.5GB while the selected one is ~3GB). The slightly older version is good enough for our purposes.
Because we use the base image with TensorFlow already included (and with the matching NumPy version), our requirements.txt shrinks to a single line:
opencv-python==4.5.1.48
After downloading the project code, we can build the image:
$ docker build --build-arg USERID=$(id -u) -t mld05_gpu_predict .
As discussed previously, we can skip the --build-arg USERID argument if it’s not needed (especially on Windows).
Training Dockerfile
Because we would like to use GPU not only for prediction but also for training, we need to introduce an additional image definition – Dockerfile.train:
FROM mld05_gpu_predict:latest
ENTRYPOINT ["python", "train.py"]
We simply take our prediction image as a base and add a single layer that overwrites ENTRYPOINT with the train.py script. It is a small tradeoff to avoid increasing the number of images and code duplication. We don't mind the "latest" tag here, as we have full control over the base image we use.
Now let’s build it:
$ docker build -t mld05_gpu_train -f 'Dockerfile.train' .
Running the Training
Let’s try our training with GPU and CPU – to compare performance.
Training with GPU:
$ docker run -v $(pwd)/data:/home/mluser/data -v $(pwd)/models:/home/mluser/models \
--rm --user $(id -u):$(id -g) --gpus "device=0" \
mld05_gpu_train --model_path ../models/mnist_model.h5 --epochs 5

Note the --model_path and --epochs parameters passed to the training script.
To train with CPU only, we simply remove the --gpus "device=0" argument:
$ docker run -v $(pwd)/data:/home/mluser/data -v $(pwd)/models:/home/mluser/models \
--rm --user $(id -u):$(id -g) \
mld05_gpu_train --model_path ../models/mnist_model.h5 --epochs 5
As you can see, the GPU doubles the training speed (from 18 seconds per epoch on CPU to 8 seconds per epoch on GPU). Not much, but we are training a very simple model here. With a real-life task, you could expect a 5-10 times improvement.
If your results are different, look at the TensorFlow logs. If it failed to use GPU, you will see errors like "Could not load dynamic library (…)."
Running Predictions
Having trained our model, we can check how it performs in predictions:
$ docker run -v $(pwd)/data:/home/mluser/data -v $(pwd)/models:/home/mluser/models \
--rm --user $(id -u):$(id -g) --gpus "device=0" \
mld05_gpu_predict --images_path /home/mluser/data/test_mnist_images
Summary
In this article, we have successfully run training and inference using Docker containers with the GPU support. We are ready to tackle basic ML tasks with Docker. In the next series, we’ll extend our knowledge to address more complex cases, which are typical when working with Docker on real-life scenarios.

