Here we discuss the model creation, auto-adjustment and notifications of our CI/CD MLOps Pipeline.
In this series of articles, we’ll walk you through the process of applying CI/CD to the AI tasks. You’ll end up with a functional pipeline that meets the requirements of level 2 in the Google MLOps Maturity Model. We’re assuming that you have some familiarity with Python, Deep Learning, Docker, DevOps, and Flask.
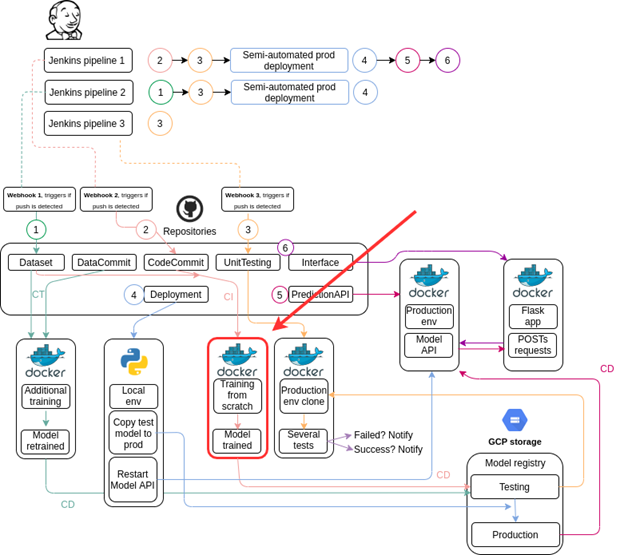
In the previous article, we set up a cloud environment for this project. In this one, we’ll walk you through the code required for continuous integration, model auto-training, auto-tweaking, and continuous delivery. The diagram below shows you where we are in our project process.
We’ll show a condensed version of the code. For the full version, see this repository. We’ll use GCR Docker images for this project (TensorFlow-powered) – but feel free to use alternative ones.
First, we’ll discuss the code that runs these solutions locally. Later, we’ll see how to get ready for the cloud deployment.
The diagram below shows the files structure for our project.

data_utils.py
The data_utils.py file handles data loading, transformation, and model saving to GCS. This file may vary from project to project. In essence, it performs all the data processing tasks before model training. Let’s have a look at the code:
import datetime
from google.cloud import storage
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import tensorflow as tf
import gc
from sklearn import preprocessing
import os
import zipfile
import cv2
import sys
def dataset_transformation(path):
images = []
for dirname, _, filenames in os.walk(path):
for filename in filenames:
if filename.endswith('.png'):
image = cv2.imread(os.path.join(dirname, filename))
image = cv2.resize(image, (128, 128))
images.append(image)
return images
def load_data(args):
file_1 = '/root/AutomaticTraining-Dataset/COVID_RX/normal_images.zip'
file_2 = '/root/AutomaticTraining-Dataset/COVID_RX/covid_images.zip'
file_3 = '/root/AutomaticTraining-Dataset/COVID_RX/viral_images.zip'
extract_to = '/root/AutomaticTraining-Dataset/COVID_RX/'
with zipfile.ZipFile(file_1, 'r') as zip_ref:
zip_ref.extractall(extract_to)
with zipfile.ZipFile(file_2, 'r') as zip_ref:
zip_ref.extractall(extract_to)
with zipfile.ZipFile(file_3, 'r') as zip_ref:
zip_ref.extractall(extract_to)
normal = dataset_transformation('/root/AutomaticTraining-Dataset/COVID_RX/normal_images')
covid = dataset_transformation('/root/AutomaticTraining-Dataset/COVID_RX/covid_images')
viral = dataset_transformation('/root/AutomaticTraining-Dataset/COVID_RX/viral_images')
X = normal + viral + covid
X = np.array(X)
y = []
for i in range(len(normal)):
y.append(0)
for i in range(len(covid)):
y.append(1)
for i in range(len(viral)):
y.append(2)
y = np.array(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0, shuffle = True)
return X_train, X_test, y_train, y_test
def save_model(bucket_name, best_model):
try:
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob1 = bucket.blob('{}/{}'.format('testing',best_model))
blob1.upload_from_filename(best_model)
return True,None
except Exception as e:
return False,e
model_assembly.py
The model_assembly.py file contains the code for model creation and auto-tweaking. We’re looking to start with a very basic model – train it and evaluate it. If the initial model doesn’t reach the desired performance, we’ll introduce refinements until we reach our goal. Let’s take a look at the code:
from tensorflow.keras.models import load_model
from tensorflow.keras import layers
import tensorflow as tf
import numpy as np
def get_base_model():
input_img = layers.Input(shape=(128, 128, 3))
x = layers.Conv2D(64,(3, 3), activation='relu')(input_img)
return input_img,x
def get_additional_layer(filters,x):
x = layers.MaxPooling2D((2, 2))(x)
x = layers.Conv2D(filters, (3, 3), activation='relu')(x)
return x
def get_final_layers(neurons,x):
x = layers.SpatialDropout2D(0.2)(x)
x = layers.Flatten()(x)
x = layers.Dense(neurons)(x)
x = layers.Dense(3)(x)
return x
These functions will be called in a loop and in the first iteration, we’ll get the base_model, the final_layers and stack them to build a very simple model. If after training we find the model doesn't perform well enough, then we’ll again get the base_model, add additional_layers, stack the final_layers, then train and evaluate it once more. If we’re still unable to reach a good performance, then the last process will be repeated in the loop adding more additional_layers until we reach a predefined good metric.
email_notifications.py
The email_notifications.py file is in charge of delivering emails to the product owner via a local SMTP server. These emails tell the owner if everything is well and, if not, what’s wrong.
import smtplib
import os
sender = ‘example@gmail.com’
receiver = ['svirahonda@gmail.com']
smtp_provider = 'smtp.gmail.com'
smtp_port = 587
smtp_account = ‘example@gmail.com’
smtp_password = ‘your_password’
def training_result(result,model_acc):
if result == 'ok':
message = 'The model reached '+str(model_acc)+', It has been saved to GCS.'
if result == 'failed':
message = 'None of the models reached an acceptable accuracy, training execution had to be forcefully ended.’
message = 'Subject: {}\n\n{}'.format('An automatic training job has ended recently', message)
try:
server = smtplib.SMTP(smtp_provider,smtp_port)
server.starttls()
server.login(smtp_account,smtp_password)
server.sendmail(sender, receiver, message)
return
except Exception as e:
print('Something went wrong. Unable to send email: '+str(e),flush=True)
return
def exception(e_message):
try:
message = 'Subject: {}\n\n{}'.format('An automatic training job has failed.', e_message)
server = smtplib.SMTP(smtp_provider,smtp_port)
server.starttls()
server.login(smtp_account,smtp_password)
server.sendmail(sender, receiver, message)
return
except Exception as e:
print('Something went wrong. Unable to send email: '+str(e),flush=True)
return
task.py
The task.py file orchestrates the program. It initializes GPUs – if any are available – starts model training, and tweaks the model if required. It also receives the arguments passed to the app. Here is the code:
import tensorflow as tf
from tensorflow.keras import Model, layers, optimizers
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras import Model
from tensorflow.keras.models import load_model
import argparse
import model_assembly, data_utils, email_notifications
import sys
import os
import gc
from google.cloud import storage
import datetime
import math
model_name = 'best_model.hdf5'
def initialize_gpu():
if len(tf.config.experimental.list_physical_devices('GPU')) > 0:
tf.config.set_soft_device_placement(True)
tf.debugging.set_log_device_placement(True)
return
def start_training(args):
X_train, X_test, y_train, y_test = data_utils.load_data(args)
initialize_gpu()
train_model(X_train, X_test, y_train, y_test, args)
def train_model(X_train, X_test, y_train, y_test,args):
try:
model_loss, model_acc = [0,0]
counter = 0
while model_acc <= 0.85:
input_img,x = model_assembly.get_base_model()
if counter == 0:
x = model_assembly.get_final_layers(64,x)
else:
for i in range(counter):
x = model_assembly.get_additional_layer(int(64*(math.pow(2,counter))),x)
x = model_assembly.get_final_layers(int(64*(math.pow(2,counter))),x)
cnn = Model(input_img, x,name="CNN_COVID_"+str(counter))
cnn.summary()
cnn.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])
checkpoint = ModelCheckpoint(model_name, monitor='val_loss', verbose=1,save_best_only=True, mode='auto', save_freq="epoch")
cnn.fit(X_train, y_train, epochs=args.epochs, validation_data=(X_test, y_test),callbacks=[checkpoint])
cnn = load_model(model_name)
model_loss, model_acc = cnn.evaluate(X_test, y_test,verbose=2)
if model_acc > 0.85:
saved_ok = data_utils.save_model(args.bucket_name,model_name)
if saved_ok[0] == True:
email_notifications.training_result('ok',model_acc)
sys.exit(0)
else:
email_notifications.exception(saved_ok[1])
sys.exit(1)
else:
pass
if counter >= 5:
email_notifications.training_result('failed',None)
sys.exit(1)
counter += 1
except Exception as e:
email_notifications.exception('An exception when training the model has occurred: '+str(e))
sys.exit(1)
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--bucket-name', type=str, default = 'automatictrainingcicd-aiplatform', help = 'GCP bucket name')
parser.add_argument('--epochs', type=int, default=3, help='Epochs number')
args = parser.parse_args()
return args
def main():
args = get_args()
start_training(args)
if __name__ == '__main__':
main()
Dockerfile
Our Dockerfile is in charge of passing the directions to the Docker daemon to build the proper container. This is what it looks like:
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-0
WORKDIR /root
RUN pip install pandas numpy google-cloud-storage scikit-learn opencv-python
RUN apt-get update; apt-get install git -y; apt-get install -y libgl1-mesa-dev
ADD "https://www.random.org/cgi-bin/randbyte?nbytes=10&format=h" skipcache
RUN git clone https://github.com/sergiovirahonda/AutomaticTraining-Dataset.git
ADD "https://www.random.org/cgi-bin/randbyte?nbytes=10&format=h" skipcache
RUN git clone https://github.com/sergiovirahonda/AutomaticTraining-CodeCommit.git
RUN mv /root/AutomaticTraining-CodeCommit/model_assembly.py /root
RUN mv /root/AutomaticTraining-CodeCommit/task.py /root
RUN mv /root/AutomaticTraining-CodeCommit/data_utils.py /root
RUN mv /root/AutomaticTraining-CodeCommit/email_notifications.py /root
ENTRYPOINT ["python","task.py"]
The above file uses the gcr.io/deeplearning-platform-release/tf2-cpu.2-0 image, installs the dependencies, clones the required repositories, moves the files to the main directory, and sets the entry point for the container execution.
Next Steps
In the next article of the series, we’ll deep-dive into the Continuous Training code. Stay tuned!

