In this post, we will look at Bitwise Algorithms and usage of Bitwise operations on Bitfields as a primitive SIMD.
Contents
- Introduction
- Bitwise Functions
- Bitwise And Or Xor
- Bitwise Not
- Bitwise Shift Left and Right
- Odd / Even
- Classical : Modulo
- Bitwise : Mask
- Multiplication / Division by 2
- Classical Solution
- Bitwise Solution
- Count bits set to 1
- Classical : Bit by Bit Solution
- Bitwise Solution
- Run of 1's
- Classical : Bit by Bit Solution
- Bitwise Solution
- Gray Code
- Floating Point Encoding
- Handling Huge Array Of Bits
- Huffman Compression
- Encoding
- Decoding
- N Queens
- Classical Solution
- Bitwise Solution
- Benchmark for both versions
- Conway's Game of Life
- Classical : Single Cell
- Bitwise : A parallel treatment
- Benchmark for both versions
- The 5 Wordle problem
- Letters to Bitmap Transform
- Loading the words file
- Composing groups of 5 words
- Points of Interest
- Links
- History
Introduction
Bitwise operations are extremely basic and fast processor instructions, they are about applying logical operators to data, but in a way most of us are not familiar with.
The usage of bitwise operations mainly fall into 2 categories:
- Data chopping/sewing : Example, a floating point value is an assemblage of 3 parts packed in a binary value, accessing to individual parts require some chopping.
- SIMD on bitfields : Same operation is applied to each bit of a bitfield. Conway's Game of life is the perfect example.
The problem is that using bitwise operations require some expertise to know when there is an interest, and how to build an algorithm taking advantage of them.
Cost of operations
Here is a small table of cost of operations:
| Operation | Cost 32 bits operands | Cost 64 bits operands | Comment |
Integer Division
Integer Modulo | 16 + house keeping | 32 + house keeping | Cost is 1 clock cycle per 2 bits
When data width double, it takes double clock cycles.
O(n)=n |
| Integer Multiplication | 5 + house keeping | 6 + house keeping | When data width double, it takes 1 more clock cycle.
O(n)= log(n) |
Addition
Subtraction | 1 | 1 | Cost is constant for any data width
O(n)= 1 |
Bitwise operations
And, Or, Shift ... | 1 | 1 | Cost is constant for any data width
O(n)= 1 |
In this article, the big O notation is about the size of data in bits.
Bitwise Functions
From a single bit point of view, bitwise operators are mainly identical to logical ones (And, Or, Not).
The difference is that the logical operation is applied independently to each bits of a value (variable/register). This lead to up to 64 simultaneous logical operations, without even resorting to multithreading.
Bitwise And Or Xor
Those are binary operators (2 operands). Xor is generally not available as logical operator.
| A | B | A And B | A Or B | A Xor B |
| 0011 | 0101 | 0001 | 0111 | 0110 |
The cost of bitwize solutions is O(n)= 1, the cost of logical solutions is O(n)= n.
C = A & B;
for (int i = 0; i < ISize; i++)
CA[i] = (AA[i] && BA[i]);
Print("A and B = ", C, "A[] and B[]= ", CA);
C = A | B;
for (int i = 0; i < ISize; i++)
CA[i] = (AA[i] || BA[i]);
Print("A or B = ", C, "A[] or B[] = ", CA);
C = A ^ B;
for (int i = 0; i < ISize; i++)
CA[i] = ((AA[i] == 0) != (BA[i] == 0));
Print("A xor B = ", C, "A[] xor B[]= ", CA);
Bitwise.cpp in Bitwise.zip.
A = 0b00110010011110110010001111000110
AA[] = 0b00110010011110110010001111000110
B = 0b01100100001111001001100001101001
BA[] = 0b01100100001111001001100001101001
A and B = 0b00100000001110000000000001000000
A[] and B[]= 0b00100000001110000000000001000000
A or B = 0b01110110011111111011101111101111
A[] or B[] = 0b01110110011111111011101111101111
A xor B = 0b01010110010001111011101110101111
A[] xor B[]= 0b01010110010001111011101110101111
A and B are integers and bitwise operations are applied. AA and BA are integer arrays, each integer contain 1 bit and logical operations are applied. Results are same.
Bitwise Not
Not is a unary operator (1 operand).
The cost of bitwize solutions is O(n)= 1, the cost of logical solutions is O(n)= n.
C = ~A;
for (int i = 0; i < ISize; i++)
CA[i] = (!AA[i]);
Print("not A = ", C, "not A[] = ", CA);
Bitwise.cpp in Bitwise.zip.
A = 0b00110010011110110010001111000110
AA[] = 0b00110010011110110010001111000110
not A = 0b11001101100001001101110000111001
not A[] = 0b11001101100001001101110000111001
A is an integers and bitwise operation is applied. AA is an integer array, each integer contain 1 bit and logical operation is applied. Results are same.
Bitwise Shift Left and Right
The shift operators are moving bits by a given number of places, they basically multiply or divide by a power of 2.
| A | B | A Shift Left B | A Shift Right B |
| 0101 | 1 | 01010 | 00010 |
| 0101 | 2 | 10100 | 00001 |
The cost of bitwize solutions is O(n)= 1, the cost of logical solutions is O(n)= n.
C = A << 1;
CA[0] = 0;
for (int i = 0; i < ISize - 1; i++)
CA[i + 1] = (AA[i]);
Print("A << 1 = ", C, "A[] << 1 = ", CA);
C = A << 2;
CA[0] = 0;
CA[1] = 0;
for (int i = 0; i < ISize - 2; i++)
CA[i + 2] = (AA[i]);
Print("A << 2 = ", C, "A[] << 2 = ", CA);
Bitwise.cpp in Bitwise.zip.
A = 0b00110010011110110010001111000110
AA[] = 0b00110010011110110010001111000110
A << 1 = 0b01100100111101100100011110001100
A[] << 1 = 0b01100100111101100100011110001100
A << 2 = 0b11001001111011001000111100011000
A[] << 2 = 0b11001001111011001000111100011000
A is an integers and bitwise operation is applied. AA is an integer array, each integer contain 1 bit and logical operation is applied. Results are same.
Odd / Even
Often, one want to know if an integer is odd or even.
For humans, it is base 10, and we just take the unit digit and look at its value.
For computers, it is base 2, and the unit bit is doing the same, if bit=0, it is even, otherwise it is odd.
The cost of bitwise solution is O(n)= 1, the cost of math solution (modulo) is O(n)= n.
Classical : Modulo
The classical solution is to get the reminder of an integer division, the modulo.
int IsOdd(int X) {
return (X % 2); }
int IsEven(int X) {
return 1-(X % 2); }
Bitwise : Mask
The bitwise solution is to mask the unit bit. Inlining the code can even improve the efficiency.
int IsOdd(int X) {
return (X & 1); }
int IsEven(int X) {
return 1-(X & 1); }
Multiplication / Division by 2, 4, 8
Multiplication and division are very good general purpose operations, but with operations on powers of 2, bitwise solutions are more efficient.
For a computer, multiplication and division by 2, 4, 8 are like multiplication and division by 10, 100, 1000 for us humans.
The cost of bitwise solution is O(n)= 1, the cost of math solution (division, modulo) is O(n)= n, (multiplication) is O(n)= log(n).
Classical Solution
int Mult2(int X) {
return (X * 2); }
int Mult4(int X) {
return (X * 4); }
int Mult8(int X) {
return (X * 8); }
int Div2(int X) {
return (X / 2); }
int Div4(int X) {
return (X / 4); }
int Div8(int X) {
return (X / 8); }
int Mod2(int X) {
return (X % 2); }
int Mod4(int X) {
return (X % 4); }
int Mod8(int X) {
return (X % 8); }
Bitwise Solution
int Mult2(int X) {
return (X << 1); }
int Mult4(int X) {
return (X << 2); }
int Mult8(int X) {
return (X << 3); }
int Div2(int X) {
return (X >> 1); }
int Div4(int X) {
return (X >> 2); }
int Div8(int X) {
return (X >> 3); }
int Mod2(int X) {
return (X & 0b0001); }
int Mod4(int X) {
return (X & 0b0011); }
int Mod8(int X) {
return (X & 0b0111); }
Count bits set to 1
A classical problem: Counting bits set to 1 in an integer.
Classical : Bit by Bit Solution
The classical solution count bits 1 by 1. The cost depends on bit size of data O(n)=n.
int BitsCnt(unsigned long int Bits) {
int Cnt=0;
do {
Cnt += Bits % 2;
Bits = Bits / 2;
}
while (Bits != 0)
return Cnt;
}
int BitsCnt(unsigned long int Bits) {
int Cnt=0;
do {
Cnt += Bits & 1;
Bits = Bits >> 1;
}
while (Bits != 0)
return Cnt;
}
Bitwise Solution
With a clever bitwise solution, every time the size of data doubles in size, it add 1 step to the solution, this is a SIMD usage of bitwise operations. The cost depends on log of bit size of data O(n)=log(n).
int BitsCnt(unsigned long int Bits) {
Bits= (Bits & 0x55555555) + ((Bits >> 1) & 0x55555555);
Bits= (Bits & 0x33333333) + ((Bits >> 2) & 0x33333333);
Bits= (Bits & 0x0f0f0f0f) + ((Bits >> 4) & 0x0f0f0f0f);
Bits= (Bits & 0x00ff00ff) + ((Bits >> 8) & 0x00ff00ff);
Bits= Bits + (Bits >>16);
return Bits & 0xff;
}
Longuest Run of 1's
I recently encountered a quick question where one was asking for a speed up of its algorithm : Can this code in C become shorter, with the same time complexity?[^]
This code is about finding the longest run of 1's in a binary integer.
Classical : Bit by Bit Solution
In this solution, bits are checked 1 by 1.
The number of times this code loops depends on the position of leftmost bit set to 1, and the loop contain a division/modulo. The cost depends on bit size of data O(n)=n.
int LargestRunof1(int n){
int count=0,max=0;
while(n>0)
{
if(n%2==1) count++;
else
{
if(count>max)
max=count;
count=0;
}
n/=2; }
if(count>max)
max=count;
return max;
}
Source code from author of question.
Bitwise Solution
In bitwise solution, same operations are performed simultaneously on each bit, it is SIMD.
The number of times this code loops depends on length of largest run of 1's. In worst case (all bits set), cost is O(n)= n.
int LargestRunof1(int n){
int max=0,Tmp;
Tmp= n;
while(n>0)
{
max++;
Tmp >>= 1; n &= Tmp; }
return max;
}
int LargestRunof1(int n){
int max=0;
while(n>0)
{
max++;
n &= (n >> 1); }
return max;
}
Gray Code
Even if little known by general population, Gray code is of extremely wide usage. In almost any device with some moving part controlled by a processor, Gray code is in use in the sensor that tells the position of that part. Such devices are Computer Numerical Control (CNC) machines, Robotic arms, 3D Printers and so on.
If you have a robotic arm, you want to know the angle of each elbow, not just folded or unfolded, you need a sensor to get that angle. If using simple binary encoding, things work perfectly as long as you are in a given position, if you are exactly between positions 2 and 3, sensor outputs 2 or 3 depending on some threshold, if you are exactly between positions 3 and 4, problem arise because 3 bits flips between 3 and 4, you can be sure that those bits will not flip on same threshold. this lead to sequences like 3 7 5 4 because of the threshold problem.
Gray code is a solution because binary values are reordered in such a way that only 1 bit will flip between any consecutive values.
List of binary values and their Gray encoding
Binary Gray
0 0b0000 0b0000
1 0b0001 0b0001
2 0b0010 0b0011
3 0b0011 0b0010
4 0b0100 0b0110
5 0b0101 0b0111
6 0b0110 0b0101
7 0b0111 0b0100
8 0b1000 0b1100
9 0b1001 0b1101
10 0b1010 0b1111
11 0b1011 0b1110
12 0b1100 0b1010
13 0b1101 0b1011
14 0b1110 0b1001
15 0b1111 0b1000
C = A ^ (A >> 1);
CA[31] = AA[31];
for (int i = ISize - 2; i >= 0; i--)
CA[i] = (AA[i + 1] == 0) != (AA[i] == 0);
Print("Gray(A) = ", C, "Gray(A[]) = ", CA);
C ^= C >> 16;
C ^= C >> 8;
C ^= C >> 4;
C ^= C >> 2;
C ^= C >> 1;
for (int i = ISize - 2; i >= 0; i--)
CA[i] = (CA[i + 1] == 0) != (CA[i] == 0);
Print("DeGray(A) = ", C, "DeGray(A[])= ", CA);
Bitwise.cpp in Bitwise.zip.
A = 0b00110010011110110010001111000110
AA[] = 0b00110010011110110010001111000110
Gray(A) = 0b00101011010001101011001000100101
Gray(A[]) = 0b00101011010001101011001000100101
DeGray(A) = 0b00110010011110110010001111000110
DeGray(A[])= 0b00110010011110110010001111000110
As one can see with bitwise solution, encoding and decoding is done simultaneously on each bit, it is SIMD.
The most popular device using gray code was probably the mechanical computer mouse.
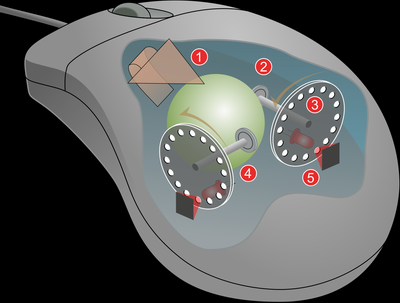 | The Gray code comes from the wheels (3) and the sensors (5).
The wheel is makes sequences of filled parts and holes, the sensors are 2 per wheel, the shift between sensors is of 0.25 sequence in order to get the Gray code output.
File:Mouse mechanism diagram.svg - Wikipedia[^] |
Floating point encoding
A float is made of 3 parts all packed into an integer. If one need to access to a particular part, bitwise operations will come into play.
Floating-point arithmetic - Wikipedia[^]
In C language, there is basically 2 methods to access those parts, either use a bitfield structure, or bitwise operations. The difference is at source code level, the bitfield structure is hiding the technical details, but behind the hood, bitwise operations are used.
#include <stdio.h>
union MyFloat {
unsigned int rawDataRep;
float floatRep;
struct {
unsigned m: 23; unsigned e: 8; unsigned s: 1; }
componentesRep;
};
void printFP(union MyFloat mf) {
unsigned int Sign, Exp, Man, Sew;
printf ("Float: %f\nSign: %i Mantisa: 0x%08x Exponent: %i\nInteger: 0x%08x.\n",
mf.floatRep, (int) mf.componentesRep.s,
(unsigned int) mf.componentesRep.m, (int) mf.componentesRep.e,
mf.rawDataRep);
Sign= mf.rawDataRep >> 31;
Exp= (mf.rawDataRep >> 23) & 0xff;
Man= mf.rawDataRep & 0x7fffff;
Sew= (Sign << 31) | (Exp << 23) | Man;
printf ("Bitwise\nSign: %i Mantisa: 0x%08x Exponent: %i\nInteger: 0x%08x\n\n",
Sign, Man, Exp, Sew);
}
void main() {
union MyFloat mf;
mf.floatRep = 355.0/113.0;
printFP(mf);
mf.floatRep = 355.0/113.0 * 4;
printFP(mf);
}</stdio.h>
Float.cpp in Bitwise.zip.
Float: 3.141593
Sign: 0 Mantisa: 0x00490fdc Exponent: 128
Integer: 0x40490fdc.
Bitwise
Sign: 0 Mantisa: 0x00490fdc Exponent: 128
Integer: 0x40490fdc
Float: 12.566372
Sign: 0 Mantisa: 0x00490fdc Exponent: 130
Integer: 0x41490fdc.
Bitwise
Sign: 0 Mantisa: 0x00490fdc Exponent: 130
Integer: 0x41490fdc
Handling Huge Array Of Bits
In article : Integer Factorization: Dreaded list of primes[^], I describe a method to compress the huge list of primes, the solution involve a huge array of bits.
By using a wheel of 30 (discussed in article : Integer Factorization: Trial Division Algorithm[^]), I endup with the conclusion that there is only 8 possible primes per slice of 30, it is the result of removing multiples of 2, 3 and 5.
Since a number is prime or not, a single bit can hold the information, and 8 bits are exactly a byte. We are lucky as it simplify the handling, but other values than 8 can be handled too.
Here is how the array is built. The sample code generate the array to paste in the header.
void TD_EncodeArray(int Max) {
long long Wheel[] = { 6, 4, 2, 4, 2, 4, 6, 2, 0 };
long long Cand = 1;
cout << "Encodage liste nombres premiers compressée" << endl;
cout << "{";
while (Cand < Max) {
int Code = 0;
int Index = 1;
int Ind = 0;
do {
if ((TD_SRW(Cand) == Cand) && (Cand != 1)) {
Code |= Index; }
Cand += Wheel[Ind];
Index = Index << 1;
Ind++;
} while (Wheel[Ind] != 0);
cout << "0x";
cout << setfill('0') << setw(2) << hex << Code << ",";
}
cout << "0}" << dec << endl;
}
Source code and download file are in article Integer Factorization: Dreaded list of primes[^].
Here is how the function IsPrime() use the bitwise And to retrieve the information, a simple mask of 1 bit on position says if it is a prime or not. In sample code, a header encode primes up to 1,000,000 in an array of size 33,334 chars.
int IsPrimeLP(MyBigInt Cand) {
const unsigned long long Wheel[] = { 6, 4, 2, 4, 2, 4, 6, 2, 0 };
const unsigned long long WOffset[] = { 1, 7, 11, 13, 17, 19, 23, 29, 0 };
if (Cand <= EPrimesMax) {
Count = 1;
long long x = Cand / WSize; long long y = Cand % WSize; for (int Index = 0; WOffset[Index] != 0; Index++) {
if (WOffset[Index] == y) {
return ((EPrimes[x] >> Index) & 0x01);
}
}
if (Cand == 2)
return 1;
else if (Cand == 3)
return 1;
else if (Cand == 5)
return 1;
else
return 0; }
return (TD_SRLPW(Cand) == 1);
}
Source code and download file are in article Integer Factorization: Dreaded list of primes[^].
Huffman Compression
While an RLE compressed stream is made of bytes, a Huffman compressed stream is made of bits. Thus, with Huffman compression, one need to convert the stream of bits to bytes, and reverse for decompression.
Huffman coding - Wikipedia[^]
Here is the Huffman tree for sample sentence : "code project for those who code"

Tree translation in sample code. Note that Huffman codes must be read from right to left.
struct Huffman {
char Letter;
int Freq;
int Code;
int Len;
};
string Sentence = "code project for those who code";
Huffman HTree[] = { { 'o', 6, 0b00, 2 }, { 'c', 3, 0b010, 3 }, { 'r', 2, 0b0110, 4 },
{ 't', 2, 0b1110, 4 }, { 'p', 1, 0b00001, 5 }, { 'j', 1, 0b10001, 5 },
{ 'd', 2, 0b1001, 4 }, { 'e', 4, 0b101, 3 }, { 'h', 2, 0b0011, 4 },
{ 'w', 1, 0b01011, 5 }, { 'f', 1, 0b011011, 6 }, { 's', 1, 0b111011, 6 },
{ ' ', 6, 0b111, 3 } };
int HTreeLen = 13;
Huffman.cpp in Bitwise.zip.
For encoding/decoding, one need to use a variable (buffer) that is at least 8 bits (a byte) + largest Huffman code (here, it is 6 bits), so 16 bits or more.
Encoding
We are concatening Huffman codes in a buffer, and when we have 8 bits or more, we save the byte to stream. Concatenation is done using bitwise shifts and bitwise Or. We are sewing parts together.
cout << "Huffman encoded by bytes" << endl;
unsigned char HList[20];
unsigned int HBuf = 0, HOffset = 0, HIndex = 0;
for (int i = 0; Sentence[i] != 0; i++) {
for (l = 0; Sentence[i] != HTree[l].Letter; l++)
;
HBuf |= HTree[l].Code << HOffset;
HOffset += HTree[l].Len;
if (HOffset > 7) {
HList[HIndex] = HBuf & 0xff;
HIndex++;
for (int j = 7; j >= 0; j--) {
cout << (((HBuf & 0xff) >> j) & 1);
}
cout << " ";
HBuf >>= 8;
HOffset -= 8;
}
}
HBuf |= 1 << HOffset;
HList[HIndex] = HBuf & 0xff;
HIndex++;
HOffset += 1;
for (int j = 7; j >= 0; j--) {
cout << (((HBuf & 0xff) >> j) & 1);
}
cout << endl << endl;
Huffman.cpp in Bitwise.zip.
Encoding result :
Letters match in Huffman table :
c o d e p r o j e c t f o r t h o s e w h o c o d e
010 00 1001 101 111 10000 0110 00 10001 101 010 0111 111 110110 00 0110 111 0111 1100 00 110111 101 111 11010 1100 00 111 010 00 1001 101
Huffman encoded by bytes
00100010 11111011 01100000 11000100 11001010 10111111 01100001 11110111 01100001 11101111 11010111 01110000 10010001 00001101
Here is how the stream of bytes is build :
Huffman encoding Steps
0000000000000000 = Huffman Buffer reset
010 = Huffman code
010 = Huffman code Shifted
0000000000000010 = Merged to buffer
00 = Huffman code
00 = Huffman code Shifted
0000000000000010 = Merged to buffer
1001 = Huffman code
1001 = Huffman code Shifted
0000000100100010 = Merged to buffer
00100010 = Byte to save
0000000000000001 = Huffman Buffer updated
101 = Huffman code
101 = Huffman code Shifted
0000000000001011 = Merged to buffer
111 = Huffman code
111 = Huffman code Shifted
0000000001111011 = Merged to buffer
...
Decoding
For decoding, we need a variable (buffer) of same size as for encoding. For decoding, we use bitwise operation to chop the input stream.
cout << "Huffman decode" << endl;
HBuf = 0;
HOffset = 0;
int i = 0;
while (i < HIndex || HBuf > 1) {
while (i < HIndex && HOffset < 25) {
HBuf |= ((unsigned int) HList[i]) << HOffset;
HOffset += 8;
i++;
}
for (l = 0; l < HTreeLen; l++) {
int Mask = ~(0xffffffff << HTree[l].Len);
if ((HBuf & Mask) == HTree[l].Code) {
break;
}
}
if (l < HTreeLen) {
cout << HTree[l].Letter;
HBuf >>= HTree[l].Len;
HOffset -= HTree[l].Len;
} else {
cout << "Error";
}
}
cout << endl << endl;
Huffman.cpp in Bitwise.zip.
Here is how the stream of bytes is decoded :
Huffman decoding Steps
0000000000000000 = Huffman Buffer
00100010 = Read byte
00100010 = Shift
0000000000100010 = Merge in Huffman Buffer
11111011 = Read byte
11111011 = Shift
1111101100100010 = Merge in Huffman Buffer
010 = Matched code
0001111101100100 = Huffman Buffer
00 = Matched code
0000011111011001 = Huffman Buffer
1001 = Matched code
0000000001111101 = Huffman Buffer
01100000 = Read byte
01100000 = Shift
0011000001111101 = Merge in Huffman Buffer
101 = Matched code
0000011000001111 = Huffman Buffer
111 = Matched code
0000000011000001 = Huffman Buffer
00001 = Matched code
0000000000000110 = Huffman Buffer
11000100 = Read byte
11000100 = Shift
...
N Queens
In the N Queens problem, we have to place chess queens in such a way that they do not attack each other.
Eight queens puzzle - Wikipedia[^]
Every time one want to place a queen on a new row, one need to check which positions are available and skip all positions locked by previous queens.
Classical Solution
In classical solution, for every queen on board, we save the column number, and for a new queen on next row, we have to check if the column chosen if locked by a previous queen or not. We have to check all previous queens to know if a column is locked or not.
int IsFree(int Row, int Col, int *Board) {
for (int Scan = 0; Scan < Row; Scan++) {
Checks++;
if (Board[Scan] == Col)
return 0;
Checks++;
if (Board[Scan] == Col + (Row - Scan))
return 0;
Checks++;
if (Board[Scan] == Col - (Row - Scan))
return 0;
}
return 1;
}
void NQueensClas(int Size) {
int Board[Size + 1];
int Row = 0;
cout << endl << "NQueen Classical Backtraking " << Size << endl;
Checks = 0;
Board[0] = 0;
while (Row < Size) {
while (Board[Row] < Size) {
if (IsFree(Row, Board[Row], Board)) {
break;
} else {
Board[Row]++;
}
}
if (Board[Row] < Size) { Row++;
Board[Row] = 0;
} else { Row--;
Board[Row]++;
}
}
cout << "First Solution ";
for (Row = 0; Row < Size; Row++) {
cout << Board[Row] + 1 << " ";
}
cout << endl;
cout << "Checks: " << Checks << endl;
}
NQueens.cpp in Bitwise.zip.
Bitwise Solution
With bitwise operations, rather than saving just the column number of a queen, we also use variables as bitmap and set the bit matching the column of each queen as they are placed on the board.
Bitwise operations takes advantage of the fact that for a given row, all previous Queens are fixed and the mask of locked columns can be calculated once.
The whole interest is that when we start a new row, the bitmap of previous row gives the position of all previous queens and just setting the bit of last queen gives a bitmap showing all queens at once.
void NQueensBit(int Size) {
int Board[Size + 1][5];
int Row = 0;
cout << endl << "NQueen Bitwise Backtraking " << Size << endl;
Checks = 0;
Board[0][0] = 0;
Board[0][1] = 0;
Board[0][2] = 0;
Board[0][3] = 0;
Board[0][4] = 0;
while (Row < Size) {
while (Board[Row][0] < Size) {
Checks++;
if (Board[Row][1] & (1 << Board[Row][0])) { Board[Row][0]++;
} else {
break;
}
}
if (Board[Row][0] < Size) { Row++;
Board[Row][0] = 0;
Board[Row][2] = (Board[Row - 1][2] | (1 << Board[Row - 1][0])) << 1; Board[Row][3] = Board[Row - 1][3] | (1 << Board[Row - 1][0]); Board[Row][4] = (Board[Row - 1][4] | (1 << Board[Row - 1][0])) >> 1; Board[Row][1] = Board[Row][2] | Board[Row][3] | Board[Row][4];
} else { Row--;
Board[Row][0]++;
}
}
cout << "First Solution ";
for (Row = 0; Row < Size; Row++) {
cout << Board[Row][0] + 1 << " ";
}
cout << endl;
cout << "Checks: " << Checks << endl;
for (Row = 0; Row < Size; Row++) {
for (int Scan = 1; Scan < 5; Scan++) {
for (int Col = 0; Col < Size; Col++) {
cout << ((Board[Row][Scan] >> Col) & 1);
}
cout << " ";
}
cout << endl;
}
}
NQueens.cpp in Bitwise.zip.
For each row, we keep track of all previous queens in the 3 directions (Vertically and both diagonals), then the 3 bitmaps are combined to get the whole constraint for the current row. A single masking of the combined constraint with the position wanted for the new queen tells if locked or not.
The Bitmap stack for the first solution of size 8
Combined Diag \ Vertical Diag /
00000000 00000000 00000000 00000000 // Constraint for first queen, all positions are free
11000000 01000000 10000000 00000000 // Constraint with first queen in column 1
10111100 00100100 10001000 00010000 // Constraint with second queen in column 5
10111011 00010010 10001001 00100010 // Constraint with third queen in column 8
11001111 00001011 10001101 01001100 // ...
11111101 00010101 10101101 11011000
10111111 00001011 10101111 10110100
11101111 00100101 11101111 11101000
Or by Queen numbers
Combined Diag \ Vertical Diag /
00000000 00000000 00000000 00000000 // Constraint for first queen, all positions are free
11000000 01000000 10000000 00000000 // Constraint with first queen in column 1
10122200 00100200 10002000 00020000 // Constraint with second queen in column 5
10212033 00010020 10002003 00200030 // Constraint with third queen in column 8
12004443 00001042 10002403 02004300 // ...
25553404 00050104 10502403 25043000
50535666 00005016 10502463 50430600
77706563 00700501 17502463 74306000
Benchmark for both versions
Execution results for 8, 15, 25 and 31 Queens : Pay attention to the number of time each solution have to check the wanted position of new queen against all previous queens.
NQueen Classical Backtracking 8
First Solution 1 5 8 6 3 7 2 4
Checks: 6,440 Time taken by function: 0 microseconds
NQueen Bitwise Backtracking 8
First Solution 1 5 8 6 3 7 2 4
Checks: 876 Time taken by function: 0 microseconds
NQueen Classical Backtracking 15
First Solution 1 3 5 2 10 12 14 4 13 9 6 15 7 11 8
Checks: 268,453 Time taken by function: 1,000 microseconds
NQueen Bitwise Backtracking 15
First Solution 1 3 5 2 10 12 14 4 13 9 6 15 7 11 8
Checks: 20,280 Time taken by function: 0 microseconds
NQueen Classical Backtracking 25
First Solution 1 3 5 2 4 9 11 13 15 19 21 24 20 25 23 6 8 10 7 14 16 18 12 17 22
Checks: 26,215,802 Time taken by function: 62,003 microseconds
NQueen Bitwise Backtracking 25
First Solution 1 3 5 2 4 9 11 13 15 19 21 24 20 25 23 6 8 10 7 14 16 18 12 17 22
Checks: 1,216,775 Time taken by function: 11,000 microseconds
NQueen Classical Backtracking 31
First Solution 1 3 5 2 4 9 11 13 15 6 18 23 26 28 31 25 27 30 7 17 29 14 10 8 20 12 16 19 22 24 21
Checks: 10,956,081,667 Time taken by function: 22,742,300 microseconds
NQueen Bitwise Backtracking 31
First Solution 1 3 5 2 4 9 11 13 15 6 18 23 26 28 31 25 27 30 7 17 29 14 10 8 20 12 16 19 22 24 21
Checks: 408,773,285 Time taken by function: 2,689,153 microseconds
Here is runtime for each sizes, see how bitwise algorithm is fast.
| Size | Checks Classical | Checks Bitwise | Runtime Classical | Runtime Bitwise | Classical/Bitwise |
| 8 Queens | 6,440 | 876 | 0 ms | 0 ms | 7.35 |
| 15 Queens | 268,453 | 20,280 | 1 ms | 1 ms | 13.24 |
| 25 Queens | 26,215,802 | 1,216,775 | 80 ms | 14 ms | 21.55 |
| 31 Queens | 10,956,081,667 | 408,773,285 | 23,414 ms | 2,796 ms | 26.80 |
Both programs follow same algorithm and try to place queens the same number of times. Since in bitwise solution one need only a single check to know if a column is available or not, the difference with classical solution is due to the stack of previous queens.
The last column in table shows the mean number of checks to do in order to know if a column is available or not.
For both versions, the algorithm for a chess board of size N, at worst, it takes N rows by N columns by 1 check. For bitwise version, a check is done in constant time, for classical version, a check depend on the number of row N. For classical version, O(n)=n ^ 3, for bitwise version, O(n)=n ^ 2.
Conway's Game of Life
Conway's Game of Life (GoL) is about a huge field of cells either dead or alive. When computing the next generation, the same set of operations is applied to all cells in play field.
A simple optimization : Adding an extra row of empty cells around the play field and handling border cells as normal cells, costs less than checking continuously for border cells.
In sample program GoL.cpp, input data is RLE compressed : RLE: The Human Friendly Compression[^]
Classical : Single Cell
In a field of n*m, for each cell, one have to check the 8 neighbor cells. For a field of size 320*240, it takes 76,800 loops. For each, there is 11 operations.
inline int CellGetN(int Row, int Col) {
return (FieldNext[Row >> 6][Col] >> (Row & 0x3f)) & 1;
}
void LNext() {
Field2N(); for (int Row = 1; Row < FieldRows + 2; Row++) {
for (int Col = 1; Col < FieldCols + 2; Col++) {
int Cnt;
Cnt = CellGetN(Row - 1, Col - 1);
Cnt += CellGetN(Row - 1, Col);
Cnt += CellGetN(Row - 1, Col + 1);
Cnt += CellGetN(Row , Col - 1);
Cnt += CellGetN(Row , Col + 1);
Cnt += CellGetN(Row + 1, Col - 1);
Cnt += CellGetN(Row + 1, Col);
Cnt += CellGetN(Row + 1, Col + 1);
if (Cnt == 3 || (Cnt == 2 && CellGetN(Row, Col))) {
Field[Row >> 6][Col] |= (unsigned long long) 1 << (Row & 0x3f);
} else {
Field[Row >> 6][Col] &= ~((unsigned long long) 1 << (Row & 0x3f));
}
}
}
}
GoL.cpp in Bitwise.zip.
It happen that my compiler (with default settings) do not optimize access to a bit in an array in integers. FieldBits is the constant 64, but my compiler do not automatically optimize the division and modulo to bitwise solution. So I made 2 versions of the function to access a single bit.
inline int CellGetN(int Row, int Col) {
return (FieldNext[Row / FieldBits][Col] >> (Row % FieldBits)) & 1;
}
Bitwise : A parallel treatment
In the case of Conway's Game of Life, bitwise operations allow a parallel treatment, it is really Single Instruction Multiple Data (SIMD). With wordsize of 64 bits, we are handling up to 62 cells at once.
There is 2 main problems with bitwise operations:
- There is no bitwise addition, one have to device a sequence of bitwise operations which will let us know how many neighbor are around each cell.
- Since play field is larger than processor wordsize, we need to device a logic to make links between words. With a play field of 240 columns, I use 4 64 bits integers to store a row, 60 bits hold the play field, and 2 bits are used for links between integers in same row.
For a field of size 320*240, it takes 1,280 loops only because the next generation is calculated by slices of 60 cells. For each block of 60 cells, counting neighbor takes 45 operations, which makes 0.75 operation per cell.
Since the play field is sliced in integers and we use bitwise operations, we need to reserve bits to make links between slices because we need to know the bit on left and on right of slice for next generation calculation.
void LNext() {
unsigned long long Bit0, Bit1, Bit2, Carry0, Carry1;
for (int Row = 0; Row < FieldQWords; Row++) {
for (int Col = 0; Col < FieldCols + 2; Col++) {
unsigned long long Tmp = Field[Row][Col] & (long long) 0x1ffffffffffffffe;
if (Row != 0) {
Tmp = Tmp | ((Field[Row - 1][Col] >> 60) & 1);
}
if (Row != 3) {
Tmp = Tmp | ((Field[Row + 2][Col] & 2) << 60);
}
FieldNext[Row][Col] = Tmp;
}
}
for (int Row = 0; Row < FieldQWords; Row++) {
for (int Col = 1; Col < FieldRows + 1; Col++) {
Bit0 = FieldNext[Row][Col - 1] << 1;
Bit1 = Bit0 & FieldNext[Row][Col - 1];
Bit0 = Bit0 ^ FieldNext[Row][Col - 1];
Bit1 = Bit1 | (Bit0 & (FieldNext[Row][Col - 1] >> 1));
Bit0 = Bit0 ^ (FieldNext[Row][Col - 1] >> 1);
Carry0 = Bit0 & (FieldNext[Row][Col] << 1);
Bit0 = Bit0 ^ (FieldNext[Row][Col] << 1);
Carry1 = Bit1 & Carry0;
Bit1 = Bit1 ^ Carry0;
Bit2 = Carry1;
Carry0 = Bit0 & (FieldNext[Row][Col] >> 1);
Bit0 = Bit0 ^ (FieldNext[Row][Col] >> 1);
Carry1 = Bit1 & Carry0;
Bit1 = Bit1 ^ Carry0;
Bit2 = Bit2 | Carry1;
Carry0 = Bit0 & (FieldNext[Row][Col + 1] << 1);
Bit0 = Bit0 ^ (FieldNext[Row][Col + 1] << 1);
Carry1 = Bit1 & Carry0;
Bit1 = Bit1 ^ Carry0;
Bit2 = Bit2 | Carry1;
Carry0 = Bit0 & FieldNext[Row][Col + 1];
Bit0 = Bit0 ^ FieldNext[Row][Col + 1];
Carry1 = Bit1 & Carry0;
Bit1 = Bit1 ^ Carry0;
Bit2 = Bit2 | Carry1;
Carry0 = Bit0 & (FieldNext[Row][Col + 1] >> 1);
Bit0 = Bit0 ^ (FieldNext[Row][Col + 1] >> 1);
Carry1 = Bit1 & Carry0;
Bit1 = Bit1 ^ Carry0;
Bit2 = Bit2 | Carry1;
Field[Row][Col] = (FieldNext[Row][Col] | Bit0) & Bit1 & ~Bit2;
}
}
}
GoL.cpp in Bitwise.zip.
Benchmark for both versions
Here is runtime for 1000 generations. One can see Bitwise algorithm is tedious but pays off.
| Runtime Classical | Runtime Classical
Bitwise Access | Runtime Bitwise |
| 5,100 ms | 2,313 ms | 48 ms |
One can see that using Bitwise to access to a bit in an array of integers have a huge impact on runtime on classical version, at least with compiler default settings.
The 5 Wordle problem
Lately, I came across a video on YouTube where the speaker was asked if it is possible to pick 5 wordle words without using the same letter twice. Its initial solution was terrible.
First video: Can you find: five five-letter words with twenty-five unique letters? - YouTube[^]
abd second video: Someone improved my code by 40,832,277,770% - YouTube[^]
In order to solve this problem, we need to continuously check is a letter is already in use by previous words. In the naive solution, letters are checked 1 by 1, for the fith word, there is 20 * 5 letters to check to know if fith word is correct. In bitwise solution, we use a bitfield using 1 bit per letter, to know if a fith word is correct, one only need 1 comparison.
Letters to Bitmap Transform
In order to take advantage of Bitwise operations, one need to transform letters to a bitmap.
Uppercase letters A-Z are ASCII encoded from 65-to 90
Lowercase letters a-z are ASCII encoded from 97-to 122
BitNumber = Letter & 0x1f; Mask = 1 << (Letter & 0x1f); zyxwvutsrqponmlkjihgfedcba
'a' => 0b00000000000000000000000000000010
'z' => 0b00000100000000000000000000000000
"panel" => 0b00000000000000010101000000100010
The bitmap of a word is called mask in this article.
Loading the words file
I use a wordfile found in the links of the video, the problem is that the file is very loose about what is a word. I resorted to filtering while reading the file.
- Any word with a size different from 5 chars is rejected.
- Any word with a char that is not alphabet letters is rejected.
- Any word with Uppercase letter is rejected as being probably an acronym.
- Any word with a repeated letter is rejected.
- Any word without voyels is rejected too. Voyels include 'y' because of "glyph".
- Any word with a mask (already in list of words) is rejected as anagram.
Anagrams:
zyxwvutsrqponmlkjihgfedcba
"panel" => 0b00000000000000010101000000100010
"nepal" => 0b00000000000000010101000000100010
void MLit5() {
ifstream Words("words.txt");
string Line;
int Voy = 0;
Voy |= (1 << ('a' & 0x1f));
Voy |= (1 << ('e' & 0x1f));
Voy |= (1 << ('i' & 0x1f));
Voy |= (1 << ('o' & 0x1f));
Voy |= (1 << ('u' & 0x1f));
Voy |= (1 << ('y' & 0x1f));
if (Words.is_open()) {
while (getline(Words, Line)) {
FL++;
if (Line.length() != 5) { RLn++;
} else {
F5++;
FA++;
FD++;
FLC++;
int Mask = 0;
int OK = 1;
for (int Scan = 0; Scan < 5; Scan++) {
if (isalpha(Line[Scan]) != 0) { if ((Line[Scan] & 0x60) == 0x40) { OK = 0;
FLC--;
RLt++;
break;
}
int BSet = 1 << (Line[Scan] & 0x1f); if (Mask & BSet) { OK = 0;
FD--;
RLD++;
break;
}
Mask |= BSet; } else {
OK = 0;
FA--;
FD--;
FLC--;
RLt++;
break;
}
}
if (OK && (Mask & Voy)) { MSort(Mask, Line); }
}
}
Words.close();
Mots5x5.cpp in Bitwise.zip.
Insertion sort with dichotomy search for new word.
void MSort(int Mask, string Line) {
if (MNb == 0) {
MList[MNb].Mask = Mask;
strcpy(MList[MNb].Mot, Line.data());
MNb++;
} else if (MList[MNb - 1].Mask < Mask) {
MList[MNb].Mask = Mask;
strcpy(MList[MNb].Mot, Line.data());
MNb++;
} else {
int Db = 0, Fn = MNb - 1;
while (Db < Fn) {
int Md = (Db + Fn) / 2;
if (MList[Md].Mask < Mask) {
Db = Md + 1;
} else {
Fn = Md;
}
}
if (MList[Fn].Mask != Mask) {
for (int Scan = MNb; Scan > Fn; Scan--) {
MList[Scan].Mask = MList[Scan - 1].Mask;
strcpy(MList[Scan].Mot, MList[Scan - 1].Mot);
}
MList[Fn].Mask = Mask;
strcpy(MList[Fn].Mot, Line.data());
MNb++;
}
}
}
Mots5x5.cpp in Bitwise.zip.
Result of wordfile filtereing.
File Lines :466,551
Five letters Lines :22,950
Alphabet Only Lines :22,240
No UpperCase Letter Lines :13,052
No Duplicate Letter Lines :17,577
No Anagrams :5,334
Composing groups of 5 words
I build the 5 words sets using a non recursive backtracking algorythm. 5 loops are nested.
A simple bitwise AND tells if letters of a new word are already used in current set of words.
if ((Mask[1] & MList[Mot[2]].Mask) == 0) { Mask[2] = Mask[1] | MList[Mot[2]].Mask;
void MLot() {
int Mot[6], Mask[6];
Mask[0] = 0;
for (Mot[1] = 0; Mot[1] < MTop(Mask[0], 5); Mot[1]++) {
MPick++;
if ((Mask[0] & MList[Mot[1]].Mask) == 0) {
Mask[1] = Mask[0] | MList[Mot[1]].Mask;
for (Mot[2] = MBot(Mask[1], Mot[1]); Mot[2] < MTop(Mask[1], 4); Mot[2]++) {
MPick++;
if ((Mask[1] & MList[Mot[2]].Mask) == 0) {
Mask[2] = Mask[1] | MList[Mot[2]].Mask;
for (Mot[3] = MBot(Mask[2], Mot[2]); Mot[3] < MTop(Mask[2], 3); Mot[3]++) {
MPick++;
if ((Mask[2] & MList[Mot[3]].Mask) == 0) {
Mask[3] = Mask[2] | MList[Mot[3]].Mask;
for (Mot[4] = MBot(Mask[3], Mot[3]); Mot[4] < MTop(Mask[3], 2); Mot[4]++) {
MPick++;
if ((Mask[3] & MList[Mot[4]].Mask) == 0) {
Mask[4] = Mask[3] | MList[Mot[4]].Mask;
for (Mot[5] = MBot(Mask[4], Mot[4]); Mot[5] < MTop(Mask[4], 1); Mot[5]++) {
MPick++;
if ((Mask[4] & MList[Mot[5]].Mask) == 0) {
PNb++;
cout << PNb << " " << MList[Mot[1]].Mot << " " << MList[Mot[2]].Mot << " "
<< MList[Mot[3]].Mot << " " << MList[Mot[4]].Mot << " "
<< MList[Mot[5]].Mot;
cout << " " << Mot[1] << " " << Mot[2] << " " << Mot[3] << " " << Mot[4]
<< " " << Mot[5] << endl;
}
}
}
}
}
}
}
}
}
}
}
Mots5x5.cpp in Bitwise.zip.
Result of sets og word search.
Start Search
1 chimb fjord vangs expwy klutz 107 750 3346 5142 5289
2 klong jambs chivw expdt furzy 411 1030 3907 4026 5331
3 klong chivw expdt jumby zarfs 411 3907 4026 4793 5243
4 fjord gucks vibex nymph waltz 750 2675 4074 4311 5299
5 fjord swack vibex glyph muntz 750 3663 4074 4290 5291
6 fjord chivw pbxes glaky muntz 750 3907 4010 4137 5291
7 fjord chivw pbxes mangy klutz 750 3907 4010 4200 5289
8 jambs gconv whilk expdt furzy 1030 3271 3502 4026 5331
9 jocks dwarf vibex glyph muntz 1162 3594 4074 4290 5291
10 gconv whilk expdt jumby zarfs 3271 3502 4026 4793 5243
Picked Words 25,714,697,452
Fini
10 sets found. Numbers after set of words are positions in sorted list. Picked words is the number of words tried while building sets of words.
Points of Interest
A clever usage of bitwise operations can greatly improve efficiency of algorithms, but its usage is more complicated because we are less familiar with those operations.
Links
History
- 21st March, 2022: First draft
- 3rd April, 2022: First Publishingdraft
- 5th April, 2022: Improved version
- 13th April, 2022: second version : added Conway's Game of Life
- 13th June, 2022: version 3 : Improvement
- 31st July, 2022: version 4 : Improvement and more samples
- 5th August, 2022: version 5 : Added handling of huge bits array
- 20th August, 2022: version 5.1 : Typos in source code
- 10th December, 2022: version 6 : Added example with wordle words

