In this article, we focus on building a content-based recommendation system, aiming to systematically implement and code the underlying theoretical concepts.
Introduction
Everyone is accustomed to encountering recommended products on e-commerce platforms or online news websites. Amazon, perhaps, was the first retailer to effectively implement the surge fostered by recommendations and, in this series of articles, our objective is to explore in depth how such a system is practically constructed. We will discover that there are in fact various approaches and particularly focus on content-based recommendations. Even within this constrained scenario, we will find numerous possibilities for customization and utilize the widely adopted tf-idf algorithm. Finally, we will apply these concepts to an open dataset, recommending articles for the Huffington Post.
The following authoritative textbook on this topic merit consultation. This book extends beyond recommendation systems and covers a myriad of expansive and general data mining topics. It notably emphasizes implementations for managing vast quantities of data.
Mining of Massive Datasets (Leskovec, Rajaraman, Ullman)
This article is inspired by an originally posted article available here. Refer to it for a comprehensive review.
For those in a hurry, you can promptly download the source code and tailor it to your requirements. Alternatively, if you are unafraid of theory or simply curious about how certain facets of online ecommerce function, feel free to continue reading.
What Do We Mean by Recommendation System?
A recommendation system is a software application or algorithm designed to provide personalized suggestions or recommendations to users. These suggestions can range from products, services, or content, such as movies, music, books, or articles, based on the user's preferences, behavior, or historical interactions with the system. Recommendation systems are commonly used in various online platforms to enhance user experience by offering tailored suggestions that align with individual preferences.
This comprehensive definition is applicable to various contexts, encompassing both online platforms and traditional brick-and-mortar stores. The concept is not a novelty that emerged solely with the advent of the internet. In physical retail stores, large outlets traditionally highlight products through displays, yet the same products are often promoted universally. The distinct capability of online platforms to present different products to individual users with each interaction has spurred the growth of specialized companies in this field.
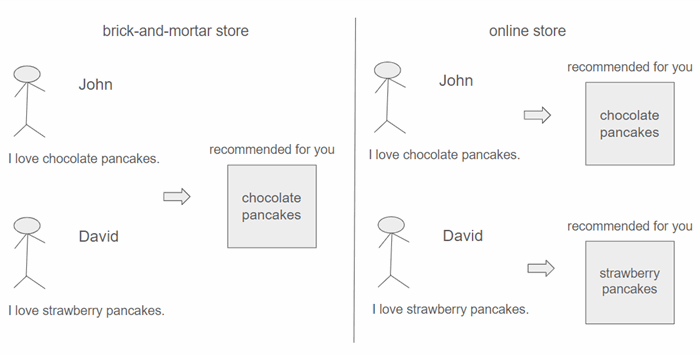
In a traditional retail store, both John and Dave would encounter the same product, regardless of Dave's preferences or needs. The static nature of the front display in physical stores hinders adaptation to each user. In contrast, online platforms have the flexibility to rearrange products dynamically with each request, enabling personalized recommendations tailored to individual users based on their preferences.
Our objective is to unveil the methodologies employed, explore the algorithms in use, and implement them through a tangible example.
I Need to Implement a Recommendation System! Where Should I Begin?
There are primarily two distinct methodologies for implementing recommendations: content-based filtering and collaborative filtering. We will provide a brief description of each.
Recommendations With Content-Based Filtering
Content-based filtering is a recommendation system technique that suggests items based on the features or attributes of the items themselves and the user's preferences. Instead of relying on the preferences of other users, it analyzes the content of the items the user has interacted with or liked in the past. The system recommends items with similar characteristics to those the user has shown interest in previously. This approach is particularly useful when there is sufficient information about the items and their attributes.

Content-based filtering proves to be highly effective in the context of online newspapers, where user preferences and interests can be inferred from the content and attributes of the articles.
Recommendations with Collaborative Filtering
Collaborative filtering is a recommendation system approach that relies on the preferences and behaviors of a group of users to make personalized suggestions. It involves analyzing user interactions and preferences to identify patterns and recommend items that similar users have liked or interacted with.
We suggest items based on the customer journey of other users. The collaborative term should become evident from this illustration.
We suggest items based on the purchase history of other users.
Important 1
These two methodologies are not mutually exclusive and are often combined to create hybrid recommendation systems.
Important 2
Collaborative filtering requires some historical data to be applied, whereas content-based filtering can be used at the early stages. This phenomenon is known as the cold start problem.
We will only explore content-based filtering in this series, but those eager to delve deeper into collaborative filtering can refer to this book.
Focus on Our Roadmap
Now that the underlying concepts have been identified and explained, it is time to delve deeper into the topic. As already mentioned, we will implement content-based filtering and apply it to a series of news articles available here. It is a dataset of some articles proposed on the Huffington Post, and our goal will be to propose 5 recommended articles for each item.
Our dataset contains more than 5000 articles, presented as follows. Notice that some articles are written in Spanish and we will have to take this into account.
Each article has various attributes such as headline, URL, short description, and so on. At first glance, it is not at all evident to manually guess what to recommend just from this file.
A First Approach
In our dataset, each article possesses various significant attributes, including tags that signify the general topic of the item. While one approach could involve grouping articles based on these tags and recommending items from the same group for a given item, this method has its limitations. It is relatively straightforward to implement but may be somewhat naive due to several reasons. Firstly, tags can be either empty or inaccurate. Secondly, it doesn't consider the actual content of the articles. Lastly, it doesn't provide a ranking within a specific group, leaving the question unanswered: among 20 articles in the same topic, which 5 are the most relevant?
In our example, an article has the tags "computer, elderly, fifty". While "computer" might be a general and suitable tag, "elderly" and "fifty" are likely too specific and may not accurately define the article.
Additionally, this technique requires manual intervention as we need to tag each article manually with the corresponding attributes. This process can be time-consuming and lacks automation and so we should resort to other techniques.
A Second Approach
We will introduce the venerable tf-idf algorithm, which addresses nearly all the issues mentioned earlier. You can find the continuation of this article here.
History
- 2nd December, 2023: Initial version

