We embark on a series of articles focusing on the construction of a naive Bayes classifier for language detection. Our objective is to seamlessly integrate theoretical concepts with practical implementation, providing illustrations of the challenges involved.
Introduction
Language detection refers to the process of automatically identifying and determining the language in which a given text or document is written. This task is crucial in various applications, such as natural language processing, machine translation, and content filtering. The goal of language detection is to analyze a piece of text and accurately determine the language it is written in, even when dealing with multilingual or diverse content. It involves utilizing computational techniques and algorithms to recognize distinctive patterns, linguistic features, and statistical properties associated with different languages.
Common approaches to language detection include statistical methods, machine learning algorithms, and rule-based systems. Statistical methods often involve analyzing character or word frequencies, while machine learning approaches, learn from labeled training data to make predictions about the language of a given text.
In this article, we will utilize the naive Bayes algorithm to perform this task. In reality, the primary objective is not just to create a language classifier but, more importantly, to unveil the intricacies of the Bayes algorithm. We will discover that, despite its seemingly simplistic designation as "naive," it proves to be an exceptionally powerful algorithm.
We referred to the following book to elucidate certain concepts.
What Is Probability Theory?
Probability theory is a branch of mathematics that provides a framework for modeling and quantifying uncertainty or randomness. It deals with the analysis of random phenomena and the likelihood of different outcomes occurring in a given event or experiment. The primary goal of probability theory is to formalize and mathematically describe the principles governing randomness and uncertainty.
In this article, we will presume that the reader is already familiar with the concept of probability. While our articles typically adopt a holistic approach, providing comprehensive details, the complexity of the probability field discourages a thorough exploration of the underlying theory in this instance. We encourage them to refer to this resource for a quick refresher.
How Can Naive Bayes Be Leveraged for Language Detection?
As mentioned earlier, language detection refers to the process of automatically identifying and determining the language in which a given text or document is written.
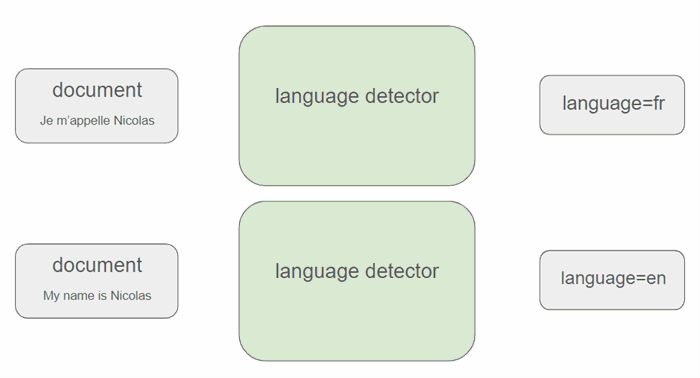
Our objective is to implement a language detector employing a precise algorithm. Specifically, when provided with a specific document d, we aim to determine the language l of that document. Even more precisely, our objective is to obtain a probability for each language given a specific document: mathematically, we want P(l∣d).
Information
This problem exemplifies a typical machine learning process. While individuals with common sense can swiftly identify the language of a document, a computer (a machine) is incapable of performing such a seemingly straightforward task without undergoing extensive training.
What Is the Naive Bayes Algorithm?
The naive Bayes algorithm is a probabilistic classification algorithm based on Bayes' theorem (see our refresher). It is named "naive" because it makes the assumption of independence among the features (as we will see later),
With the notation employed earlier, P(l∣d)=P(d∣l)P(l)/P(d) (Bayes's theorem).
- P(d∣l) is the document d probability given language l.
- P(l) is the language l probability.
- P(d) is the document d probability.
It's a Bit of Gibberish. What Do All These Terms Mean?
As mentioned in the introduction, a computer requires examples to learn. Naive Bayes is no exception, and we must provide it with a training set for it to make accurate predictions. In this context, naive Bayes serves as an example of a supervised algorithm, meaning that we need to furnish it with labeled data. To be more precise, it implies that we possess a corpus of documents for which we already know the language, and we will provide these to the language detector for training—similar to how a footballer would train before a match.

In this context, the language probability P(l) is better understood as the ratio of documents written in a specific language to the total number of documents. For instance, if our corpus consists of 90 documents in English and 10 in French, our belief is that there is a 90% chance the next document will be in English. This belief is formalized through a prior probability.
Information
In practice, it is advisable for the number of documents in each language to be roughly equal or not excessively disproportionate.
And What Does P(d|l) Mean?
Expressed in that manner, the concept might indeed seem abstract and challenging to envision. However, in our scenario, a document is essentially perceived by a computer as a sequence of characters, nothing more and nothing less. It is our responsibility to extract meaningful insights and useful attributes from these characters. For example, we could observe the length of each word in the document and create an attribute named "number of 5-letter words". Similarly, we could track the occurrences of the letter 'z' and create an attribute named "number of 'z' in the document". These attributes that we collect are referred to as features.
Therefore, we can transform a conceptual document object into a mathematical object with quantitative features.
d(170)=(numberof5letterwords=2,numberof′z′=0,...)
Information
The choice of features is entirely subjective. While opting for conventional features is advisable, the addition of specific, custom attributes is the unique touch of each individual.
Equipped with these notations, we have P(d|l)=P(numberof5letterwords,numberof′z′,...|l).
At this stage, the assumptions of naive Bayes come into play. We assume independence among the features within a given language, implying that the presence or absence of one feature does not influence the presence or absence of another feature. This is a conditional property based on the language.
P(numberof5letterwords,numberof′z′,...|l)=P(numberof5letterwords|l)P(numberof′z′|l)...P(...|l)
We end up with probabilities of individual features instead of a joint distribution.
How to Calculate the Probabilities of These Individual Features?
Consider, for instance, calculating the probability of the occurrence of 5-letter words in each language. In this case, we would need to gather all the documents in the specified language (e.g., the English corpus), determine the number of 5-letter words, and normalize it by the total number of words in the English corpus. This process would then be replicated for other features, such as the number of 'z', and so on.
Therefore, we proceed to calculate the probabilities for each individual feature, enabling us to compute the joint probability in the Bayes' formula. It's worth noting that these probabilities are derived from observed data, and in the literature, this probability is occasionally referred to as the evidence.
Information
In this terminology, the desired probability P(l|d) is referred to as the posterior probability, and it's crucial to recall the following formula: posterior = prior x evidence. Philosophically, our posterior belief is adjusted based on the observed data (evidence) and our prior belief.
How to Choose the Right Class for a New Document?
Now, consider a new document arriving for which we want to predict the language. The process involves examining each feature employed to train the algorithm and noting its probability for each class.
The naive Bayes algorithm calculates the posterior probabilities for each language given the input features. Then, it assigns the language with the highest probability as the predicted class.
Despite its simplicity, naive Bayes can be surprisingly effective.
Minute, and P(d) ?
Defining the probability of the document P(d) is a challenging task, but in any case, it remains the same for all classes (as it does not depend on a specific class). In this context, it does not impact the posterior probability and is often disregarded or simply ignored.
Still a Few Subtleties
The theory is generally straightforward, but the devil is in the details. When it comes to implementing an algorithm, there are subtleties that we need to consider.
Calculate Log Probabilities
A probability is always less than 1. When dealing with many features, computing the product of all independent probabilities may lead to underflows in floating-point arithmetic. That's why, in practice, log probabilities are calculated to avoid such intricacies.
The Bayes' formula can then be rewritten (P(d) was ignored as explained earlier).
logP(l∣d)=logP(d∣l)+logP(l)
Since the logarithm is a monotonically increasing function, it doesn't affect the fact that a higher probability represents the most likely choice. However, it offers the advantage of transforming products into sums, mitigating issues associated with underflows.
What Happens if One of the Languages Includes an Unknown Feature?
It is possible that one of the languages does not have occurrences of a certain feature. In such a case, the probability of this feature becomes 0, and taking the logarithm may result in an error.
To circumvent such issues, it is recommended to add 1 to each count of occurrences during the training phase.
Information
This technique is commonly referred to in the literature as Laplace smoothing. While we won't delve into the nitty-gritty details of Laplace smoothing, it's crucial to ensure that we continue calculating a probability. Consequently, we need to correct the denominator by adding the total number of possible features to it.
After introducing the naive Bayes algorithm, it's time to put it into action. We will apply the theoretical concepts we've just described to illustrate our language detector example. Visit the following link for details.
History
- 12th December, 2023: Initial version

