Get ready for AI. It's not easy, it's not trivial, it's a tough nut to crack. But let's hope we will work it out together. Here's a Microsoft library, DirectML, a low-level way to get you started.
Source
https://github.com/WindowsNT/DirectMLTest
Introduction
Many people discuss, especially after the evolution of ChatGPT and other models, the benefits of Machine Learning in Artificial Intelligence. This article tries, from my own amateur view in ML but otherwise expert in general low-level programming, explain some basics and use DirectML for a real training scenario.
Background
This article aims to the hardcore Windows C++ developer, familiar with COM and DirectX to introduce how machine learning could be done using DirectML. For (way more) simplicity, you would use TensorFlow, PyTorch and Python in general, but, being myself sticky to C++, I would like to explore the internals of DirectML.
DirectML is a low level layer (PyTorch is a layer above it), so do prepare for lots of difficult, dirty stuff.
Machine Learning in general.
I strongly recommend Machine Learning for Absolute Beginners. Machine Learning in general is the ability of the computer to solve f(x) = y for a given x. X and Y may not only be a single variable, but a (big) set of variables. There are three basic types of machine learning:
- Supervised learning. This means that I have a given set of [x,y] and train a model in order to "learn" from it and calculate y for an unknown x. A simple example of that is a set of prices for a car model from 1990 to 2024 (x = year, y = price) and to query the model for a possible price in 2025. Another example would be a set of hours that a student will practice a lesson and whether they will pass it or not in the exams, based on a set of students that studied a specific number of hours (x) and passed it or not (y).
- Unsupervised learning. This means that the [x,y] set that we are trying to learn from is not complete. An example is antivirus detection in where an AV tries to learn not from definite sets, but from similarity patterns.
- Reinforced learning. This is based on the reverse of the f(x) = y, that is, for a given y we are trying to find x's that work. An example of that is an autonomous driving system which takes for granted that it must not crash (y) and finds all x's that will result in that.
In our example, we will stick to the simplest form, the Supervised learning.
A "Hello world" of this mode is the simple-variable linear regression. That is, for a given set of [x,y] variables, we are trying to create a line f(x) = a + bx as such the line is "close" to all of them, like the following picture:
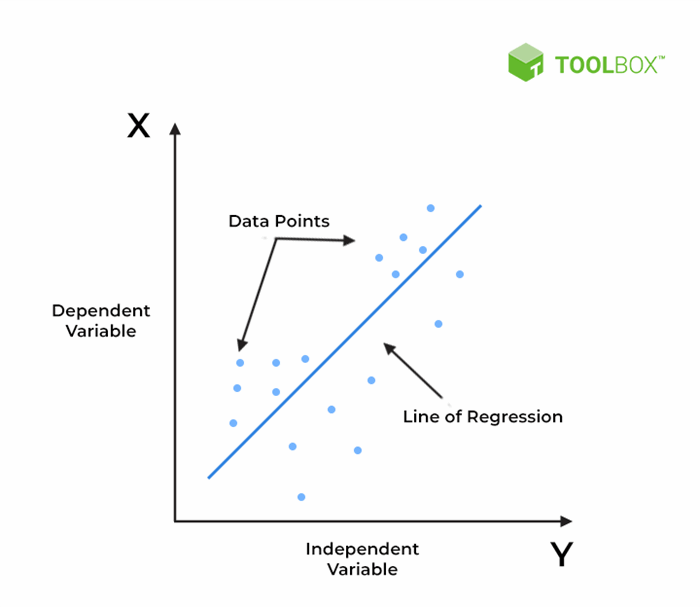
Another Wikipedia example:

The formula to calculate a and b for a given [x,y] set is as follows:
- B = (n*Σxy - ΣxΣy) / ((n*Σx^2) - (Σx)^2)
- A = (Σy - (B * Σx))/n
So, the more sets of [x,y] we have, the more likely is for our model to give a good answer for an unknown x. That's what "training" is.
Of course, this is very old, even my Casio FX 100C has a "LR" mode to input this. However it's time to discuss about GPU cores and how they can perform here.
GPU versus CPU
The GPU cores are a lot of mini-cpus; That is, they are capable of doing simple math stuff, like add, multiply, trigonometry, logarithms etc. If you take a look at HLSL/GLSL code, for example this ShaderToy Grayscale, you will see that a simple algorithm with power, sqrt, dot etc is executed for, at a 1920x1080 resolution = 2073600 times for an image, or 62208000 times per second for a 30fps video. My RTX 4060 has 3072 such "cpus".
Therefore, it is of great imporance to allow these cores to execute simple but massive math operations, way faster than our CPU can.
Linear regression in CPU
It's of course trivial to find the y = A+Bx formula in CPU C++ code. Given two arrays `xs` and `ys` which contain N elements of (x,y) pairs, then:
void LinearRegressionCPU(float* px,float* py,size_t n)
{
auto beg = GetTickCount64();
float Sx = 0, Sy = 0,Sxy = 0,Sx2 = 0;
for (size_t i = 0; i < n; i++)
{
Sx += px[i];
Sx2 += px[i] * px[i];
Sy += py[i];
Sxy += px[i] * py[i];
}
float B = (n * Sxy - Sx * Sy) / ((n * Sx2) - (Sx * Sx));
float A = (Sy - (B * Sx)) / n;
auto end = GetTickCount64();
printf("Linear Regression CPU:\r\nSx = %f\r\nSy = %f\r\nSxy = %f\r\nSx2 = %f\r\nA = %f\r\nB = %f\r\n%zi ticks\r\n\r\n", Sx,Sy,Sxy,Sx2,A,B,end - beg);
}
Now starts your hell. The same result will be achieved in the GPU using DirectML with LOTS of additional and really complex code. Isn't machine learning wonderful?
Tensors
A tensor is a generalization of a matrix, which is a generalization of a vector, which is a generalization of a number. That is, a number is x, a vector is [x y z], a 2x2 matrix is a table that has 2 rows and 2 columns and a tensor can have any number of dimensions.
DirectML can "upload" tensor data to our GPU, "execute" a set of operators (math functions) and "return" the result to the CPU.
DirectML and DirectMLX
DirectML is a low level DirectX12 API code capable of manipulating tensors to the GPU. Start here for the MSDN docs. We will go step by step in it in three operations in our code: A copy, an adding, and the linear regression.
DirectMLX is a header-only helper collection that allows you to build graphs easily. Remember DirectShow or Direct2D filters eh? A graph describes inputs and outputs and which operator is applied between them. We will create three graphs with the aid of DirectMLX.
The list of DirectML structures indicates what operators you have to execute on tensors.
I 've started with HelloDirectML and expanded it for a real linear regression training.
Starting our journey
Initialize DirectX 12. That is, enumerate the DXGI adapters, create a DirectX 12 device, create its Command Allocator, Command Queue and CommandList interfaces:
HRESULT InitializeDirect3D12()
{
CComPtr<ID3D12Debug> d3D12Debug;
#if defined (_DEBUG)
THROW_IF_FAILED(D3D12GetDebugInterface(IID_PPV_ARGS(&d3D12Debug)));
d3D12Debug->EnableDebugLayer();
#endif
CComPtr<IDXGIFactory4> dxgiFactory;
CreateDXGIFactory1(IID_PPV_ARGS(&dxgiFactory));
CComPtr<IDXGIAdapter> dxgiAdapter;
UINT adapterIndex{};
HRESULT hr{};
do
{
dxgiAdapter = nullptr;
dxgiAdapter = 0;
THROW_IF_FAILED(dxgiFactory->EnumAdapters(adapterIndex, &dxgiAdapter));
++adapterIndex;
d3D12Device = 0;
hr = ::D3D12CreateDevice(
dxgiAdapter,
D3D_FEATURE_LEVEL_11_0,
IID_PPV_ARGS(&d3D12Device));
if (hr == DXGI_ERROR_UNSUPPORTED) continue;
THROW_IF_FAILED(hr);
} while (hr != S_OK);
D3D12_COMMAND_QUEUE_DESC commandQueueDesc{};
commandQueueDesc.Type = D3D12_COMMAND_LIST_TYPE_DIRECT;
commandQueueDesc.Flags = D3D12_COMMAND_QUEUE_FLAG_NONE;
commandQueue = 0;
THROW_IF_FAILED(d3D12Device->CreateCommandQueue(
&commandQueueDesc,
IID_PPV_ARGS(&commandQueue)));
commandAllocator = 0;
THROW_IF_FAILED(d3D12Device->CreateCommandAllocator(
D3D12_COMMAND_LIST_TYPE_DIRECT,
IID_PPV_ARGS(&commandAllocator)));
commandList = 0;
THROW_IF_FAILED(d3D12Device->CreateCommandList(
0,
D3D12_COMMAND_LIST_TYPE_DIRECT,
commandAllocator,
nullptr,
IID_PPV_ARGS(&commandList)));
return S_OK;
}
Initialize DirectML with DMLCreateDevice. In debug mode, you can use DML_CREATE_DEVICE_FLAG_DEBUG.
Create DirectML operator graphs
An operator graph is describing which operator operates in which tensor. In our code, depending on the Method defined, we have three sets.
1. The "abs" operator which apples the abs() function to each element of the tensor.
auto CreateCompiledOperatorAbs(std::initializer_list<UINT32> j,UINT64* ts = 0)
{
dml::Graph graph(dmlDevice);
dml::TensorDesc desc = { DML_TENSOR_DATA_TYPE_FLOAT32, j };
dml::Expression input1 = dml::InputTensor(graph, 0, desc);
dml::Expression output = dml::Abs(input1);
if (ts)
*ts = desc.totalTensorSizeInBytes;
return graph.Compile(DML_EXECUTION_FLAG_ALLOW_HALF_PRECISION_COMPUTATION, { output });
}
The 'j' variable is, for example, {2,2} to create a 2x2 tensor of float32, that is, 8 floats, 32 bytes. We have 1 input tensor with that description and the output tensor is created by performing dml::Abs() function. DirectMLX simplifies creating those operators.
In addition, we return the 'total input tensor size' in bytes so we know how big our buffer will later be. The last line compiles the graph and returns an IDMLCompiledOperator.
2. The 'add' operator now takes 2 inputs and produces 1 output, so:
auto CreateCompiledOperatorAdd(std::initializer_list<UINT32> j, UINT64* ts = 0)
{
dml::Graph graph(dmlDevice);
auto desc1 = dml::TensorDesc(DML_TENSOR_DATA_TYPE_FLOAT32, j);
auto input1 = dml::InputTensor(graph, 0, desc1);
auto desc2 = dml::TensorDesc(DML_TENSOR_DATA_TYPE_FLOAT32, j);
auto input2 = dml::InputTensor(graph, 1, desc2);
auto output = dml::Add(input1,input2);
if (ts)
*ts = desc1.totalTensorSizeInBytes + desc2.totalTensorSizeInBytes;
return graph.Compile(DML_EXECUTION_FLAG_ALLOW_HALF_PRECISION_COMPUTATION, { output });
}
I call this also with a {2,2} tensor so we have two input tensors , so we need now 64 bytes (to be returned in *ts). We use the dml::Add to create the output.
3. The linear regression operator is more complex.
auto CreateCompiledOperatorLinearRegression(UINT32 N, UINT64* ts = 0)
{
dml::Graph graph(dmlDevice);
auto desc1 = dml::TensorDesc(DML_TENSOR_DATA_TYPE_FLOAT32, { 1,N });
auto desc2 = dml::TensorDesc(DML_TENSOR_DATA_TYPE_FLOAT32, { 1,N });
auto input1 = dml::InputTensor(graph, 0, desc1);
auto input2 = dml::InputTensor(graph, 1, desc2);
auto o1 = dml::CumulativeSummation(input1, 1, DML_AXIS_DIRECTION_INCREASING, false);
auto o2 = dml::CumulativeSummation(input2, 1, DML_AXIS_DIRECTION_INCREASING, false);
auto o3 = dml::Multiply(input1, input2);
auto o4 = dml::CumulativeSummation(o3, 1, DML_AXIS_DIRECTION_INCREASING, false);
auto o5 = dml::Multiply(input1, input1);
auto o6 = dml::CumulativeSummation(o5, 1, DML_AXIS_DIRECTION_INCREASING, false);
auto d1 = desc1.totalTensorSizeInBytes;
while (d1 % DML_MINIMUM_BUFFER_TENSOR_ALIGNMENT)
d1++;
auto d2 = desc2.totalTensorSizeInBytes;
while (d2 % DML_MINIMUM_BUFFER_TENSOR_ALIGNMENT)
d2++;
if (ts)
*ts = d1 + d2;
return graph.Compile(DML_EXECUTION_FLAG_ALLOW_HALF_PRECISION_COMPUTATION, { o1,o2,o3,o4,o5,o6 });
}
We have 2 input tensors, a [1xN] tensor with the x values and [1xN] tensor with the y values for the linear regression.
Now we have 6 output tensors:
- One for the Σx
- One for the Σy
- One for the xy
- One for the Σxy
- One for the x^2
- One for the Σx^2
For the sums, we use the CumulativeSummation operator which sums all the values in a tensor's axis to another tensor.
Also, we have to care for alignment because DirectML buffers have to be aligned to DML_MINIMUM_BUFFER_TENSOR_ALIGNMENT.
Load our data
Tensors can have padding and stride, but in our examples, tensors are packed (no padding, no stride). So in case of Abs or Add we simply create an inputTensorElementArray vector of 4 floats. In case of the linear regression we load it from a 5-xy set:
std::vector<float> xs = { 10,15,20,25,30,35 };
std::vector<float> ys = { 1003,1005,1010,1008,1014,1022 };
size_t N = xs.size();
However, you can call RandomData() and this will fill these buffers with 32MB of random floats.
Create the initializer
In DirectML, an operator "initializer" must be called and configured once.
IDMLCompiledOperator* dmlCompiledOperators[] = { dmlCompiledOperator };
THROW_IF_FAILED(dmlDevice->CreateOperatorInitializer(
ARRAYSIZE(dmlCompiledOperators),
dmlCompiledOperators,
IID_PPV_ARGS(&dmlOperatorInitializer)));
Binding the initializer
Binding in DirectML simply selects which part of the buffers are assigned to tensors. For example, if you have 32 input bytes as a buffer, you may have 2 input tensors, one from 0-15 and the other from 0-16.
In our Abs example, an input tensor is 16 bytes ( 4 floats) and the output tensor is also 16 bytes (4 floats).
In our Add example, 32 bytes for input, 16 for the first tensor and 16 for the second, and 16 bytes for output.
In our Linear Regression example, if we have 5 sets of (x,y), we need 2 tensors 5 floats each (one for x, one for y) and 6 tensors 5 floats each to hold our sum results as discussed above. Mapping our input and output buffers to tensors is done with DirectML binding.
So first we create a heap:
void CreateHeap()
{
initializeBindingProperties = dmlOperatorInitializer->GetBindingProperties();
executeBindingProperties = dmlCompiledOperator->GetBindingProperties();
descriptorCount = std::max(
initializeBindingProperties.RequiredDescriptorCount,
executeBindingProperties.RequiredDescriptorCount);
D3D12_DESCRIPTOR_HEAP_DESC descriptorHeapDesc{};
descriptorHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV;
descriptorHeapDesc.NumDescriptors = descriptorCount;
descriptorHeapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_SHADER_VISIBLE;
THROW_IF_FAILED(d3D12Device->CreateDescriptorHeap(
&descriptorHeapDesc,
IID_PPV_ARGS(&descriptorHeap)));
SetDescriptorHeaps();
}
Then we create a binding table on it:
DML_BINDING_TABLE_DESC dmlBindingTableDesc{};
CComPtr<IDMLBindingTable> dmlBindingTable;
void CreateBindingTable()
{
dmlBindingTableDesc.Dispatchable = dmlOperatorInitializer;
dmlBindingTableDesc.CPUDescriptorHandle = descriptorHeap->GetCPUDescriptorHandleForHeapStart();
dmlBindingTableDesc.GPUDescriptorHandle = descriptorHeap->GetGPUDescriptorHandleForHeapStart();
dmlBindingTableDesc.SizeInDescriptors = descriptorCount;
THROW_IF_FAILED(dmlDevice->CreateBindingTable(
&dmlBindingTableDesc,
IID_PPV_ARGS(&dmlBindingTable)));
}
Sometimes DirectML needs additional temporary or persistent memory. We check
temporaryResourceSize = std::max(initializeBindingProperties.TemporaryResourceSize, executeBindingProperties.TemporaryResourceSize);
If this is not zero, we create more temporary memory for DirectML:
auto x1 = CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT);
auto x2 = CD3DX12_RESOURCE_DESC::Buffer(temporaryResourceSize, D3D12_RESOURCE_FLAG_ALLOW_UNORDERED_ACCESS);
THROW_IF_FAILED(d3D12Device->CreateCommittedResource(
&x1,
D3D12_HEAP_FLAG_NONE,
&x2,
D3D12_RESOURCE_STATE_COMMON,
nullptr,
IID_PPV_ARGS(&temporaryBuffer)));
RebindTemporary();
The same happens for "persistent resources"
persistentResourceSize = std::max(initializeBindingProperties.PersistentResourceSize, executeBindingProperties.PersistentResourceSize);
Now we need a command recorder:
dmlDevice->CreateCommandRecorder(
IID_PPV_ARGS(&dmlCommandRecorder));
to "record" our initializer to a DirectX 12 command list:
dmlCommandRecorder->RecordDispatch(commandList, dmlOperatorInitializer, dmlBindingTable);
And then we close and "execute" the list:
void CloseExecuteResetWait()
{
THROW_IF_FAILED(commandList->Close());
ID3D12CommandList* commandLists[] = { commandList };
commandQueue->ExecuteCommandLists(ARRAYSIZE(commandLists), commandLists);
CComPtr<ID3D12Fence> d3D12Fence;
THROW_IF_FAILED(d3D12Device->CreateFence(
0,
D3D12_FENCE_FLAG_NONE,
IID_PPV_ARGS(&d3D12Fence)));
auto hfenceEventHandle = ::CreateEvent(nullptr, true, false, nullptr);
THROW_IF_FAILED(commandQueue->Signal(d3D12Fence, 1));
THROW_IF_FAILED(d3D12Fence->SetEventOnCompletion(1, hfenceEventHandle));
::WaitForSingleObjectEx(hfenceEventHandle, INFINITE, FALSE);
THROW_IF_FAILED(commandAllocator->Reset());
THROW_IF_FAILED(commandList->Reset(commandAllocator, nullptr));
CloseHandle(hfenceEventHandle);
}
After this function completes, our "Initializer" is done and need not be called again.
Binding the Operator
We now "reset" the Binding Table with the operator instead of the initializer
dmlBindingTableDesc.Dispatchable = dmlCompiledOperator;
THROW_IF_FAILED(dmlBindingTable->Reset(&dmlBindingTableDesc));
We will rebind the temporary and persistent memory, if needed:
ml.RebindTemporary();
ml.RebindPersistent();
Binding the Input
We will only bind one input buffer with an accumulated byte sum 'tensorInputSize' of all the input tensors:
CComPtr<ID3D12Resource> uploadBuffer;
CComPtr<ID3D12Resource> inputBuffer;
auto x1 = CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_UPLOAD);
auto x2 = CD3DX12_RESOURCE_DESC::Buffer(tensorInputSize);
THROW_IF_FAILED(ml.d3D12Device->CreateCommittedResource(
&x1,
D3D12_HEAP_FLAG_NONE,
&x2,
D3D12_RESOURCE_STATE_GENERIC_READ,
nullptr,
IID_PPV_ARGS(&uploadBuffer)));
auto x3 = CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT);
auto x4 = CD3DX12_RESOURCE_DESC::Buffer(tensorInputSize, D3D12_RESOURCE_FLAG_ALLOW_UNORDERED_ACCESS);
THROW_IF_FAILED(ml.d3D12Device->CreateCommittedResource(
&x3,
D3D12_HEAP_FLAG_NONE,
&x4,
D3D12_RESOURCE_STATE_COPY_DEST,
nullptr,
IID_PPV_ARGS(&inputBuffer)));
And now upload the data to the GPU:
D3D12_SUBRESOURCE_DATA tensorSubresourceData{};
tensorSubresourceData.pData = inputTensorElementArray.data();
tensorSubresourceData.RowPitch = static_cast<LONG_PTR>(tensorInputSize);
tensorSubresourceData.SlicePitch = tensorSubresourceData.RowPitch;
::UpdateSubresources(ml.commandList,inputBuffer,uploadBuffer,0,0,1,&tensorSubresourceData);
auto x9 = CD3DX12_RESOURCE_BARRIER::Transition(inputBuffer,D3D12_RESOURCE_STATE_COPY_DEST,D3D12_RESOURCE_STATE_UNORDERED_ACCESS);
ml.commandList->ResourceBarrier( 1,&x9);
For more on resource barriers, see this.
Binding input tensors
For our "abs" method, there is only one input tensor to bind:
DML_BUFFER_BINDING inputBufferBinding{ inputBuffer, 0, tensorInputSize };
DML_BINDING_DESC inputBindingDesc{ DML_BINDING_TYPE_BUFFER, &inputBufferBinding };
ml.dmlBindingTable->BindInputs(1, &inputBindingDesc);
For "add" and "linear regression" methods, there are two input tensors:
if (Method == 2 || Method == 3)
{
DML_BUFFER_BINDING inputBufferBinding[2] = {};
inputBufferBinding[0].Buffer = inputBuffer;
inputBufferBinding[0].Offset = 0;
inputBufferBinding[0].SizeInBytes = tensorInputSize / 2;
inputBufferBinding[1].Buffer = inputBuffer;
inputBufferBinding[1].Offset = tensorInputSize /2;
inputBufferBinding[1].SizeInBytes = tensorInputSize / 2;
DML_BINDING_DESC inputBindingDesc[2] = {};
inputBindingDesc[0].Type = DML_BINDING_TYPE_BUFFER;
inputBindingDesc[0].Desc = &inputBufferBinding[0];
inputBindingDesc[1].Type = DML_BINDING_TYPE_BUFFER;
inputBindingDesc[1].Desc = &inputBufferBinding[1];
ml.dmlBindingTable->BindInputs(2, inputBindingDesc);
}
As you see, we "split" the input buffer into half.
Binding the output tensors
For "Abs" or "Add", we only have one output equal to input:
CComPtr<ID3D12Resource> outputBuffer;
if (Method == 1)
{
auto x5 = CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT);
auto x6 = CD3DX12_RESOURCE_DESC::Buffer(tensorOutputSize, D3D12_RESOURCE_FLAG_ALLOW_UNORDERED_ACCESS);
THROW_IF_FAILED(ml.d3D12Device->CreateCommittedResource(
&x5,
D3D12_HEAP_FLAG_NONE,
&x6,
D3D12_RESOURCE_STATE_UNORDERED_ACCESS,
nullptr,
IID_PPV_ARGS(&outputBuffer)));
DML_BUFFER_BINDING outputBufferBinding{ outputBuffer, 0, tensorOutputSize };
DML_BINDING_DESC outputBindingDesc{ DML_BINDING_TYPE_BUFFER, &outputBufferBinding };
ml.dmlBindingTable->BindOutputs(1, &outputBindingDesc);
}
For "Linear Regression", we have 6 output tensors so we split them to parts. We had saved the tensor sizes earlier:
auto x5 = CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT);
auto x6 = CD3DX12_RESOURCE_DESC::Buffer(tensorOutputSize, D3D12_RESOURCE_FLAG_ALLOW_UNORDERED_ACCESS);
THROW_IF_FAILED(ml.d3D12Device->CreateCommittedResource(
&x5,
D3D12_HEAP_FLAG_NONE,
&x6,
D3D12_RESOURCE_STATE_UNORDERED_ACCESS,
nullptr,
IID_PPV_ARGS(&outputBuffer)));
DML_BUFFER_BINDING outputBufferBinding[6] = {};
outputBufferBinding[0].Buffer = outputBuffer;
outputBufferBinding[0].Offset = 0;
outputBufferBinding[0].SizeInBytes = Method3TensorSizes[0];
outputBufferBinding[1].Buffer = outputBuffer;
outputBufferBinding[1].Offset = Method3TensorSizes[0];
outputBufferBinding[1].SizeInBytes = Method3TensorSizes[1];
outputBufferBinding[2].Buffer = outputBuffer;
outputBufferBinding[2].Offset = Method3TensorSizes[0] + Method3TensorSizes[1];
outputBufferBinding[2].SizeInBytes = Method3TensorSizes[2];
outputBufferBinding[3].Buffer = outputBuffer;
outputBufferBinding[3].Offset = Method3TensorSizes[0] + Method3TensorSizes[1] + Method3TensorSizes[2];
outputBufferBinding[3].SizeInBytes = Method3TensorSizes[3];
outputBufferBinding[4].Buffer = outputBuffer;
outputBufferBinding[4].Offset = Method3TensorSizes[0] + Method3TensorSizes[1] + Method3TensorSizes[2] + Method3TensorSizes[3];
outputBufferBinding[4].SizeInBytes = Method3TensorSizes[4];
outputBufferBinding[5].Buffer = outputBuffer;
outputBufferBinding[5].Offset = Method3TensorSizes[0] + Method3TensorSizes[1] + Method3TensorSizes[2] + Method3TensorSizes[3] + Method3TensorSizes[4];
outputBufferBinding[5].SizeInBytes = Method3TensorSizes[5];
DML_BINDING_DESC od[6] = {};
od[0].Type = DML_BINDING_TYPE_BUFFER;
od[0].Desc = &outputBufferBinding[0];
od[1].Type = DML_BINDING_TYPE_BUFFER;
od[1].Desc = &outputBufferBinding[1];
od[2].Type = DML_BINDING_TYPE_BUFFER;
od[2].Desc = &outputBufferBinding[2];
od[3].Type = DML_BINDING_TYPE_BUFFER;
od[3].Desc = &outputBufferBinding[3];
od[4].Type = DML_BINDING_TYPE_BUFFER;
od[4].Desc = &outputBufferBinding[4];
od[5].Type = DML_BINDING_TYPE_BUFFER;
od[5].Desc = &outputBufferBinding[5];
ml.dmlBindingTable->BindOutputs(6, od);
Ready!
We "record" as previously, but now not the initializer, but the compiled operator:
dmlCommandRecorder->RecordDispatch(commandList, dmlCompiledOperator, dmlBindingTable);
And then we close and execute the command list as earlier with the CloseExecuteResetWait() function.
Read it back
We want to take data from the GPU back, so we 'd use ID3D12Resource map to get it back:
CComPtr<ID3D12Resource> readbackBuffer;
auto x7 = CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_READBACK);
auto x8 = CD3DX12_RESOURCE_DESC::Buffer(tensorOutputSize);
THROW_IF_FAILED(ml.d3D12Device->CreateCommittedResource(
&x7,
D3D12_HEAP_FLAG_NONE,
&x8,
D3D12_RESOURCE_STATE_COPY_DEST,
nullptr,
IID_PPV_ARGS(&readbackBuffer)));
auto x10 = CD3DX12_RESOURCE_BARRIER::Transition(outputBuffer,D3D12_RESOURCE_STATE_UNORDERED_ACCESS,D3D12_RESOURCE_STATE_COPY_SOURCE);
ml.commandList->ResourceBarrier(1,&x10);
ml.commandList->CopyResource(readbackBuffer, outputBuffer);
ml.CloseExecuteResetWait();
D3D12_RANGE tensorBufferRange{ 0, static_cast<SIZE_T>(tensorOutputSize) };
FLOAT* outputBufferData{};
THROW_IF_FAILED(readbackBuffer->Map(0, &tensorBufferRange, reinterpret_cast<void**>(&outputBufferData)));
This `outputBufferData` now is a pointer to the output buffer. For our linear regression, we know where to take data from:
float Sx = 0, Sy = 0, Sxy = 0, Sx2 = 0;
if (Method == 3)
{
char* o = (char*)outputBufferData;
Sx = outputBufferData[N - 1];
o += Method3TensorSizes[0];
outputBufferData = (float*)o;
Sy = outputBufferData[N - 1];
o += Method3TensorSizes[1];
outputBufferData = (float*)o;
o += Method3TensorSizes[2];
outputBufferData = (float*)o;
Sxy = outputBufferData[N - 1];
o += Method3TensorSizes[3];
outputBufferData = (float*)o;
o += Method3TensorSizes[4];
outputBufferData = (float*)o;
Sx2 = outputBufferData[N - 1];
}
We need the last element of tensor 1,2,4 and 6 (tensors 3 and 5 were used for intermediate calculations).
And finally:
float B = (N * Sxy - Sx * Sy) / ((N * Sx2) - (Sx * Sx));
float A = (Sy - (B * Sx)) / N;
D3D12_RANGE emptyRange{ 0, 0 };
readbackBuffer->Unmap(0, &emptyRange);
Now if you run the app in the method 3:
Linear Regression CPU:
Sx = 135.000000
Sy = 6062.000000
Sxy = 136695.000000
Sx2 = 3475.000000
A = 994.904785
B = 0.685714
Linear Regression GPU:
Sx = 135.000000
Sy = 6062.000000
Sxy = 136695.000000
Sx2 = 3475.000000
A = 994.904785
B = 0.685714
Phew!
Yes, it is hard. Yes, it's Machine Learning. Yes, it's AI. Don't fall for it; It's difficult. You need studying a lot to get it working.
And then of course, you have to decide your own stuff of f(x) = y with LOTs of variables to "train" the models with lots of operators and tensors.
But I hope I 've fired the starter's pistol signal for you.
GOOD LUCK.
History
18-4-2024: First try.

