I recently wrote a quick test to prove something, that ended up being wrong…
Of course, this is the way of science. You form a hypothesis, then you test. The results should prove or disprove your theory.
The Hypothesis
Ok, my theory was that Buffer.BlockCopy() would outperform our current Array.Copy routines on the page level.
When we are loading records off a page, we have to extract some parts of the buffer to build up a row buffer. A typical 8Kb page may have 100 or more records packed into it, and grabbing them out can take quite a bit of time. Each row data is a compressed byte array that may include information that points to extended row data as well.
This is one of the differences between this same app written in C++ and C#. In C++, you would just take a pointer to the original buffer and pass that to the row routines, you wouldn't need a copy of the data. But we don't have pointers in C#, so a copy is made to get out just the part of the buffer needed by that row.
Since we want the fastest way possible to read this block of data into the row, we were looking at alternative ways to do it.
The Experiment
I wrote a program that randomly grabs a length from an 8Kb block that contains 150 records. The length of the row was randomized (but the seed reset to the same value for both tests to ensure the same random numbers were used with both methods). The results were surprising.
class Program
{
public static int pagesize = 8192;
public static int MaxLoops = 100000;
static void Main( string[] args )
{
Stopwatch watch = new Stopwatch();
GC.Collect(GC.MaxGeneration, GCCollectionMode.Forced);
System.Threading.Thread.Sleep(2000);
watch.Start();
DoTest(true);
watch.Stop();
Console.WriteLine("Buffer.BlockCopy took {0} ticks", watch.ElapsedTicks);
watch.Reset();
GC.Collect(GC.MaxGeneration, GCCollectionMode.Forced);
System.Threading.Thread.Sleep(2000);
watch.Start();
DoTest(false);
watch.Stop();
Console.WriteLine("Array.Copy took {0} ticks", watch.ElapsedTicks);
Console.WriteLine("Press enter to exit");
Console.ReadLine();
}
static void DoTest( bool BlockCopy )
{
byte[] src = new byte[pagesize];
byte[] des = new byte[pagesize];
Random rand = new Random(4);
int totalmoved = 0;
int maxRecord = pagesize / 150;
for (int i = 0; i < MaxLoops; i++)
{
int recordsize = rand.Next(maxRecord);
int readlocation = rand.Next(pagesize - recordsize);
int writelocation = rand.Next(pagesize - recordsize);
if (BlockCopy)
{
PartialBufferBlockCopy(ref src, readlocation,
ref des, writelocation, recordsize);
}
else
{
PartialBufferArrayCopy(ref src, readlocation,
ref des, writelocation, recordsize);
}
totalmoved += recordsize;
}
Console.WriteLine("Average block moved: {0} ", totalmoved / MaxLoops);
}
static void PartialBufferBlockCopy( ref byte[] Source, int SourceStart,
ref byte[] Destination, int DestStart, int NumberBytes )
{
Buffer.BlockCopy(Source, SourceStart,
Destination, DestStart,
NumberBytes);
}
static void PartialBufferArrayCopy( ref byte[] Source, int SourceStart,
ref byte[] Destination, int DestStart, int NumberBytes )
{
Array.Copy(Source, SourceStart,
Destination, DestStart,
NumberBytes);
}
}
The Results
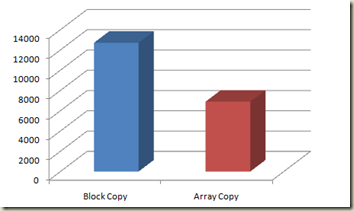
The results surprised me a bit. On my Core 2 laptop, the results are as follows. This was run under Visual Studio 2010 RC and .NET 4 command line app. I ran the same test under .NET 3.5 SP1 and got similar results.
Buffer.BlockCopy took 12706 ticksArray.Copy took 6897 ticks
1.8 times Faster
That load represents a real world scenario for us in the database engine. I did find that Array.Copy can perform really poorly when you are not going from a byte[] to another byte[]. This is probably because the objects are being boxed and unboxed. Array.Copy can convert between types, but it is expensive to do so.
Array.Copy is Very Good
Your scenario may be different. Code it up and test it. In this case, the Array.Copy() working on byte[] arrays worked really well.
What about Unsafe Code?
I got an email asking what if we went to unsafe code and just dropped a pointer in to get the row data. Well, I have tested some parts of the code with unsafe blocks, but to really test this scenario I would have to rip apart a lot of code and change the way the rowdata is loaded, etc. I have not done that for a test because it would probably take a day or two to do the test, and we really have no serious intention to build an unsafe version. It would require us forking our own engine and maintaining two implementations, not something I want to do with the current engine.

