Introduction
"With great power comes great responsibility"... As the hardware world is booming and its processing power increases, the responsibility lies with developers to utilize such power. OK, so the comparison is lame, but I am a fan of the Spider Man movie and was always looking for a way to use its slogan... guess I should keep looking :)
Seriously though, multi-core (and multi-processor) machines are dominant these days. Soon enough, as reported by some lead vendors, you will not be able to find machines with less than 8 cores. As such, the traditional way of writing serial programs will not be able to make use of such power, by default. These programs should be written in a way which utilizes the power of multi-cores.
Do we have to? Some might say. Wouldn't running my program on a multi-core machine automatically improve performance; after all, aren't there more threads? The answer is no! Running a serial program on a multi-core machine has nearly zero performance enhancements. With the exception of IO operations, your program will still use one thread of a single core at a time. Thread switching occurs - which incurs overhead by the way - but at all times, only one thread will be active (again, with the exception of IO operations, which can happen on different threads).
Multi-threaded programming is the way which allows developers to take advantage of multiple threads concurrently. And while it has been available for many years, multi-threaded programming has often been avoided due to its complexity. Developers had to put most of their effort in writing clean multi-threaded code rather than focusing on the business problem.
What does multithreading have to do with multi-cores? Can't we write multi-threaded code if we have a single core? Yes, we can. But again, as long as we have a single core, only one thread at a time will work since all threads belong to that same single core... logical enough. When your multi-threaded program runs on a multi-core machine, threads belonging to different cores will be able to run together and hence your program will take advantage of the hardware power.
One final note before going on: multithreaded programming does not differ if you have a multi-core machine or multi-processer machine. This is a hardware separation; underneath, your code will be working with threads all the same.
Parallel vs. Concurrent
Well, both concepts are related but not the same: in its simplest definition, Concurrency is about executing multiple un-related tasks in a concurrent mode. What these un-related tasks share are system resources, but they do not share a common problem to solve; meaning, they are logically independent. Now, think of these tasks as threads. And, since these threads share system resources, you face the globally common problems of concurrent programming such as deadlocks and data races. This makes concurrent programming extremely difficult and debugging complicated.
What is Parallelism? Parallelism is taking a certain task and dividing it into a set of related tasks to be executed concurrently. Sweet! So again, thinking of these tasks as threads, Parallel Programming still has the same problems of concurrent programming (deadlocks, data races, etc...), and introduces new challenges, most notably, sharing and partitioning data across these related threads. This makes Parallel Programming even more difficult and debugging even more complicated. :(
However, it is not all bad news. .NET 4.0 parallel programming is a great step onwards. The new API solves a lot of problems (but not all) of Parallel Programming, and greatly eases up parallel debugging...
Setting the Context of .NET Parallel Programming
The previous sections introduced multi-threaded programming and its need. This section introduces the context of Parallel Programming in the .NET Framework in a gradual manner:
- We have multi-core machines and we need to think of a way to utilize their power. So is the need to think of Parallel Programming.
- What is Parallel Programming all about? It's about how to partition a single piece of work into multiple concurrent units.
- What partitioning options do we have? Option 1 would be static partitioning. Static partitioning is "hard-coding" the number of units and threads you want to use. For example, saying that you want to divide a large chunk of work into "n" units, each running on a single thread over a single core. The problem with this approach is that it is not scalable. While this solution would be fine on a machine with "n" cores, it quickly will become un-scalable for machines with "n+m" cores.
- The natural evolution of solving the partitioning problem would be dynamic partitioning. This means that you divide your work into a single unit per available core. While this would solve the scalability problem, it introduces another one: load-imbalance. In real problems, it is really unlikely that all work units will take the same amount of time to complete. This means that some cores will finish their work while other cores will still be busy without being able to utilize the now-free cores.
- Moving up the chain of solutions, we now have one more option: partition work into the smallest feasible units which will make use of the most feasible number of available threads. This will solve the load-imbalance issue as work is divided into the smallest possible units where each unit will run over an available thread. However, now we have a problem: thread overhead. Creating and killing threads is an expensive procedure.
- This brings us to the final partitioning option: the .NET Thread Pool. The .NET Thread Pool maintains a scheduler and a thread queue. Instead of killing a thread once it finishes its work, this thread is pushed into the queue and it is now available to be picked up by the next unit of work scheduled for execution. The thread pool is exposed through the
System.Threading.ThreadPool namespace, and it has been available since before .NET v 4.0.
Wait a minute, so what is exactly new in the .NET 4.0 Parallel Programming model if the above discussion applies to pre-v 4.0? The answer will come by inspecting the shortcomings of the thread pool as discussed. The thread pool is a fire-and-forget programming model. Once you create a thread by code, you basically have no way to perform any operations on it. There is no support for continuing, composing, monitoring data flow, performing work cancellation, and work waiting.
So what is the solution? It is the .NET 4.0 Task-based Programming. In v 4.0 of the Framework, you can program over Tasks as opposed to the lower-level threads. Now you can divide your work over Tasks instead of threads. This will give you much more power and control over your parallel work, as we will see later. Of course, you can still work with the thread pool directly if you want to work with the deeper-detail of threads.
.NET 4.0 Parallel Programming
The Parallel Programming model of .NET 4.0 is composed of the following:
- The Task Parallel Library (TPL): this is the base of the Task-based programming discussed in the previous section. It consists of:
Task class: The unit of work you will code against instead of the previous thread model.Parallel class: A static class that exposes a task-based version of some parallel-nature problems. More specifically, it contains the following methods:
- Parallel LINQ (PLINQ): Built on top of the TPL and exposes the familiar LINQ as Parallel extensions.
About the Examples
All examples discussed are downloadable. To illustrate the main ideas, some code samples will be shown in the below sections.
All examples are built using VS2010 RC1; nothing else is required. In order to feel the value of Parallel Programming, you will need a multi-core (or multi-processer) machine; the results shown are that of running the examples on a dual-core machine.
Example 1: Tasks
The first example shows the new Tasks programming model. As explained previously, Tasks - as opposed to the Thread Pool - grants more control over thread programming. In fact, you now deal with Tasks and not threads.
static void Main(string[] args)
{
Task t = Task.Factory.StartNew(() =>
{
Console.WriteLine("I am the first task");
});
var t2 = t.ContinueWith(delegate
{
Thread.Sleep(5000);
return "Tasks Example";
});
Console.ReadLine();
}
In the above code, we first create a new Task using the Task class, and we pass to the lambda expression the code to run inside that Task (in a separate thread).
Another feature is the ability to "continue" on a running Task. What this means is that once the Task is completed (in our example, Task "t"), start running another Task "t2" with the code to run supplied in an anonymous method (through a delegate).
Now uncomment block 1. Here, we see another feature which is to get a result back from a Task. Notice that we have assigned a value for Task "t2" called "Tasks Example" through the "return" statement. Now in block 1, we can retrieve that value. This kicks in a question: what will happen if the statement "t2.Result" is executed before "t2" finishes execution (recall that "t2" is running on a separate thread than the thread of the main program)? Force this behavior (that is why I am using Thread.Sleep), and you will see that in this case, the main thread will wait at "t2.Result" until "t2" finishes execution and its "return" statement is executed. Neat! A power which was not possible before.
Now uncomment block 2. Set two break points at the first and second "Console.WriteLine" statements. Run the program and notice that the line "Waiting my task" is printed before "Here I am". This indicates that the main program (thread) was waiting for task "t2" running on another thread to finish. Once "t2" finishes (delayed by using Thread.Sleep), its statement is printed.
Example 2: Parallel
This example introduces the Parallel class. Specifically, it shows how to use the new For method to perform what usually was done serially in a parallel manner.
static void Main(string[] args)
{
Stopwatch watch;
watch = new Stopwatch();
watch.Start();
for (int i = 0; i < 10; i++)
{
Thread.Sleep(1000);
}
watch.Stop();
Console.WriteLine("Serial Time: " + watch.Elapsed.Seconds.ToString());
watch = new Stopwatch();
watch.Start();
System.Threading.Tasks.Parallel.For(0, 10, i =>
{
Thread.Sleep(1000);
}
);
watch.Stop();
Console.WriteLine("Parallel Time: " + watch.Elapsed.Seconds.ToString());
Console.ReadLine();
}
The above code shows the difference in execution time of performing a unit of work (simulated by a Sleep operation) serially versus in parallel. In my dual-core machine, the time is cut by half. Now, this is a huge improvement! Imagine all the work you usually do inside For loops (or Foreach loops) and think of the time enhancement you now can get by utilizing the new Parallel.For and Parallel.Foreach methods.
One important note: sometimes it's just not that easy though. When parallelizing your work, sometimes you have to take care of special problems like synchronization and dead-locks; you still have to handle these, and I will discuss them in the next examples.
For the sake of variation, let's see an overload of the Parallel.For method. In order to support breaking out of a parallel loop, there is an overload of the Parallel.For method which takes ParallelLoopState as a parameter in the Action delegate:
Parallel.For(0,1000,(int i, ParallelLoopState loopState) =>
{
If(i==500)
loopState.Break();
return;
});
The difference between the Break and Stop methods is that Break ensures that all earlier iterations that started in the loop are executed before exiting the loop.
The Stop method makes no such guarantees; it basically says that this loop is done and should exit as soon as possible.
Both methods will stop future iterations from running.
Example 3: PLINQ
PLINQ is a LINQ Provider, so you still use the familiar LINQ model. In the underlying model, however, PLINQ uses multiple threads to evaluate queries.
static void Main(string[] args)
{
Stopwatch watch;
watch = new Stopwatch();
watch.Start();
bool[] results = new bool[arr.Length];
for (int i = 0; i < arr.Length; i++)
{
results[i] = IsPrime(arr[i]);
}
watch.Stop();
Console.WriteLine("For Loop took: " + watch.Elapsed.Seconds);
watch = new Stopwatch();
watch.Start();
bool[] results1 = arr.Select(x => IsPrime(x))
.ToArray();
watch.Stop();
Console.WriteLine("LINQ took: " + watch.Elapsed.Seconds);
watch = new Stopwatch();
watch.Start();
bool[] results2 = arr.AsParallel().Select(x => IsPrime(x))
.ToArray();
watch.Stop();
Console.WriteLine("PLINQ took: " + watch.Elapsed.Seconds);
Console.ReadLine();
}
The above code shows how to perform a deliberately time-expensive IsPrime function using LINQ (and For) vs. PLINQ. The AsParallel extension allows your code to run using PLINQ instead of LINQ. The step of using AsParallel wraps the data source with a ParallelQuery wrapper and causes the remaining extension methods in the query to bind to PLINQ rather than to LINQ to Objects.
Run the example and you will notice that while the time for execution using a serial For loop and traditional LINQ is nearly the same (actually opposite to many beliefs, LINQ has a performance overhead over For loop... but that's another story), the execution time using PLINQ is nearly cut in half.
Example 4: PLINQ Extensions
PLINQ has many extensions that affect how work partitioning is done. In this example, we will discuss one of these extensions. Examine the below code:
static void Main(string[] args)
{
Stopwatch watch = new Stopwatch();
watch.Start();
int[] src = Enumerable.Range(0, 200).ToArray();
var query = src.AsParallel()
.Select(x => ExpensiveFunc(x));
foreach (var x in query)
{
Console.WriteLine(x);
}
watch.Stop();
Console.WriteLine("Elapsed: " + watch.Elapsed.Seconds.ToString());
Console.ReadLine();
}
private static int ExpensiveFunc(int x)
{
Thread.Sleep(1);
return x;
}
This code is similar to the previous example. It shows how to execute a function using PLINQ's AsParallel extension. Now run the program. What you will see is something that you might not have expected. Notice that values 0 through 199 are printed; however, they are not printed in the correct order.
Think about it: we are using an enumerator from 0 to 200. However, since we are using PLINQ and not LINQ, the partitioning itself is not serial. The work is divided into random parallel units; for example, from 0 till 10 is assigned to thread A, while from 11 till 30 is assigned to thread B, and so on. Once a unit of work is done, its output is immediately flushed back to the final result. That's why the output is not arranged. The below image gives an indication about this:
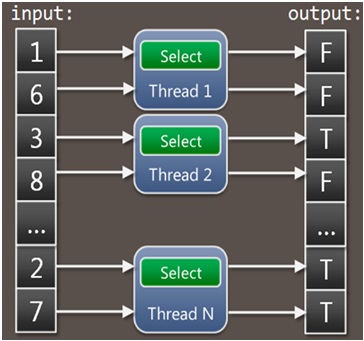
Now, edit the code and use the AsOrdered extension as follows:
var query = src.AsParallel().AsOrdered()
.Select(x => ExpensiveFunc(x));
Run the example again, and this time notice that the output is arranged from 0 till 199. This time, the AsOrdered extension forces the use of a buffer where all work units' outputs are gathered and arranged before being flushed back to the final output. The below image shows the process:

Example 5: Data Races
In Example 2, I mentioned that data races can occur when doing multi-threaded programming. This example shows a Data Race scenario and how to solve it.
static void Main(string[] args)
{
Stopwatch watch = new Stopwatch();
watch.Start();
Parallel.For(0, 100000, i =>
{
Thread.Sleep(1);
counter++;
});
watch.Stop();
Console.WriteLine("Seconds Elapsed: " + watch.Elapsed.Seconds);
Console.WriteLine(counter.ToString());
Console.ReadKey();
}
The above code uses the Parallel.For method to execute a simple Sleep statement. A counter gets incremented each time the loop body gets executed.
What number do you expect to see if you run the program on a multi-core machine? 100000 is the logical result. Now, run the program and you will notice that the number is less than that (if you do get 100000, you are just being lucky, so try again). So what happened here? Why did we get this wrong when it seemed to be so obvious? The answer is data race occurred.
Let's explain this. The trick here is in understanding how the statement counter++ gets executed. When at Intermediate Language (IL) level, counter++ is not a single statement anymore. Actually, it gets executed in 4 IL steps by the JIT (Just In-time Compiler):
- Get the current value of the counter
- Get the value of
1 - Add the two numbers together
- Save the result back to the counter
So what does this have to do with Parallel Programming and using Parallel.For? When executed over multiple cores as we do now, the body of the loop gets executed in parallel over multiple threads. The following image explains what happens in this case:
As a result, one step increment was overlooked due to the fact that two threads were granted access to the variable counter at the same time. The above scenario occurs many times, and you will get the final value wrong, as we did when we ran the program. This is a classical case of Data Race.
The solution to such a case is to lock the variable so that once a thread is accessing that variable, some other thread has to wait until the lock is released before getting access to the variable. Granted this introduces a time delay, but it is a cost we have to pay for solving data races.
There are many ways we could lock a variable, and a full discussion is outside the scope of this article, but I will use the best option in my case, which is the Interlocked.Increment method as shown below (the "lock" statement is another method which is used in another example; the comments show how to use it instead):
static void Main(string[] args)
{
Stopwatch watch = new Stopwatch();
watch.Start();
Parallel.For(0, 100000, i =>
{
Thread.Sleep(1);
#region L
Interlocked.Increment(ref counter);
#endregion
});
watch.Stop();
Console.WriteLine("Seconds Elapsed: " + watch.Elapsed.Seconds);
Console.WriteLine(counter.ToString());
Console.ReadKey();
}
Example 6: Debugging
Note: This example was built by Microsoft.
static void Main(string[] args)
{
var primes =
from n in Enumerable.Range(1, 10000000)
.AsParallel()
.AsOrdered()
.WithMergeOptions(ParallelMergeOptions.NotBuffered)
where IsPrime(n)
select n;
foreach (var prime in primes)
Console.Write(prime + ", ");
}
public static bool IsPrime(int numberToTest)
{
if (numberToTest == 2) return true;
if (numberToTest < 2 || (numberToTest & 1) == 0) return false;
int upperBound = (int)Math.Sqrt(numberToTest);
for (int i = 3; i < upperBound; i += 2)
{
if ((numberToTest % i) == 0) return false;
}
return true;
}
The above code uses PLINQ to print all prime numbers of a given range. There is nothing special about the parallel code itself, except that the IsPrime function has a logical error deliberately thrown inside it: on running the program, you will notice that the numbers 9, 15, and 25 are reported as prime numbers, which is wrong. Now, say, you want to debug the IsPrime function and set a breakpoint inside it. Run the program and you will quickly notice the problem here: because multiple threads are executing, the debugging behavior is unclear as focus will switch from one thread to another as threads take turn hitting the break point.
To solve this issue, Microsoft gave us the Parallel Tasks window (Debug menu -> Windows -> Parallel Tasks):
Through this window, you can see all the running threads in Debug mode. You can select to freeze all threads except the one that you want to actually debug, and once done, you can run the other threads.
Another useful window is the Parallel Stacks window (Debug menu -> Windows -> Parallel Stacks):
Through this window, you can see a graphical representation of the running threads of your program and how they originated.
Example 7: Deadlocks
Note: This example was built by Microsoft.
Example 5 explained Data Races and how to deal with them through locks. However, you should take care that locking can bite you in the ugly form of Deadlocks. Simply put, a deadlock is a case where a thread TA is locking resource R1 and a thread TB is locking resource R2, and now, TA needs R2 to continue while TB needs R1 to continue. Both threads are stuck and cannot continue, thus causing a deadlock.
Let's see an example of such a deadlock.
static void Main(string[] args)
{
int transfersCompleted = 0;
WatchDeadlock.BreakIfRepeats(() => transfersCompleted, 500);
BankAccount a = new BankAccount { Balance = 1000 };
BankAccount b = new BankAccount { Balance = 1000 };
while (true)
{
Parallel.Invoke(
() => Transfer(a, b, 100),
() => Transfer(b, a, 100));
transfersCompleted += 2;
}
}
class BankAccount { public int Balance; }
static void Transfer(BankAccount one, BankAccount two, int amount)
{
lock (one)
{
lock (two)
{
one.Balance -= amount;
two.Balance += amount;
}
}
}
The above code uses Parallel.Invoke to concurrently perform money transfer between bank accounts "a" to "b" and vice versa. Inside the Transfer method, locks are applied on both objects (using a "lock" statement) with the intention of making it thread-safe for concurrent execution. This method of locking will cause a deadlock scenario.
The "WatchDeadlock" class is used to force break using Debugger.Break if it notices that no new transfers have been completed after a certain amount of time.
Run the program and see how we have a deadlock between our hands.
Let's see how the VS 2010 debugging support helps us identify such deadlocks. With the program running, fire the Parallel Tasks window. The window will clearly show you a case of deadlock. Not only that, it will specifically tell you about the two threads causing the lock and how each thread is waiting for a resource (in this case, a Bank object) owned by the other thread:
So how do you avoid deadlocks? The answer is: simply do not do them. When doing parallel programming and locks, always program in a way that deadlocks will not occur!
Takeouts
It's obvious that the new Parallel Programming in .NET 4.0 solves a lot of the multi-threading complexities. It grants you more control over threads in the form of tasks, it gives you many method overloads for performing parallel operations like For, Foreach, and Invoke, it gives you the power of PLINQ, it does take care of partitioning for you, and it introduces new Thread-Safe collections in .NET 4.0 such as ConcurrentDictionary, ConcurrentQueue, and ConcurrentStack. In addition, improved debugging support makes it easier to handle parallel programming related problems. However, you still have to take care of multi-threading related concepts such as Data Races and Deadlocks.
The better news is that for Microsoft, Parallel Programming is still an ongoing project so we can expect more features and improved support in the next releases.

