Abstract
We discuss a generalization of associative binary operations, which leads to an efficient representation of a mathematical semigroup in C++ based on one class template of an augmented B+ tree. The representation is useful for a range of practical applications, including the fast computation of the sum, the minimum/maximum value and statistical parameters of a data set. We also provide a brief comparison with aggregation trees used in SQL queries.
Layout
- Introduction
- Generalization of Basic Algorithms
- Design of Advanced Data Structures and Algorithms
- Semigroup
- STL Facilities
- Basic Applications
- Comparison with Aggregation Trees
- Performance
- Using the Code
- References
Introduction
The balanced search trees have numerous practical applications, because they offer a wider variety of efficient search and update operations than arrays and linked lists. A linear data structure causes a performance bottleneck if it has at least one inefficient operation required by a user algorithm.
The augmented variants of the balanced trees offer additional efficient operations and algorithms, which extend the application area of these trees. For example, conventional balanced search trees efficiently support only ordered containers: std::set, std::multiset, std::map and std::multimap. The augmented trees are suitable for implementing not only ordered but also unordered containers. In some applications, these containers perform better than the standard containers std::vector and std::list. The augmented trees can be even used in the fast summation of huge data sets.
Here we discuss the representation of a mathematical semigroup, which supports various types of associative binary operations, including unrelated ones, such as the arithmetic addition and the selection of the minimum value. The representation is defined as one class template of an augmented B+ tree, which is parameterized on an associative binary operation. This class template can be easily used in algorithms by passing a function object of a specific binary operation as a template argument. A high level of generality is achieved without loss of efficiency, which is an important criterion in the design of general purpose libraries.
The fundamental nature of a mathematical semigroup makes it potentially useful for a wide variety of important applications. However, only a proper implementation of this concept in a programming language delivers the computing power that makes it effective in practice. The benefits of the developed representation are illustrated by the examples of the efficient computation of statistical parameters of a data set, which is compared with the facilities of aggregation trees used in SQL queries.
Generalization of Basic Algorithms
Because of their complexity, the augmented trees belong to the category of advanced data structures. In order to focus on the main ideas rather than on implementation details, it is reasonable to use simplified variants of data structures. Some aspects of the generalized representation can be more easily understood from the consideration of basic variants of algorithms and data structures. Thus, we begin this discussion with the following question: how to find the minimum value in a range of elements using the C++ standard function std::accumulate()?
The solution involves the binary function object that selects the minimum of two values.
template < class _Value >
struct min_value : public std::binary_function < _Value , _Value , _Value >
{
_Value operator ( ) ( const _Value & x , const _Value & y ) const
{
_Value res = ( y < x ) ? y : x ;
return res ;
}
} ;
The use of this function object differs from the use of std::plus. In general, a default value is not safe for a minimum function, thus we use the first element in a range to initialize a result value.
int val_init = *pos_a ;
int val_acc = 0 ;
min_value<int> bop_min ;
val_acc = std::accumulate ( pos_a+1 , pos_b , val_init , bop_min ) ;
Is this solution useful in practice? In C++ code, this is unlikely. The C++ standard library provides the function std::min_element(), which is optimal for the formulated task. The function returns an iterator referring to the first minimum value in the range.
int val_min = *(min_element(pos_a, pos_b)) ;
Despite this fact, the comparison of two methods of finding the minimum value deserves a more detailed discussion. The function object min_value implements the interface of the standard function object std::plus instead of the function std::min(). The example shows that the approach using std::accumulate() is more general than the approach using the function std::min_element(). This important conclusion follows from the fact that the function std::accumulate() can replace in user algorithms the function std::min_element(), but not the other way around. For example, std::min_element() cannot be used with such operations as the addition and multiplication. The solution based on the function std::accumulate() is an example of using a generic algorithm parameterized on a binary operation. The same algorithm with a slightly different binary function object finds the maximum value.
The generalization capacity of the function std::accumulate() might not be obvious. The STL classification of algorithms assigns the discussed standard functions to different categories. The functions are declared in different files: <numeric> and <algorithm> . Nevertheless, the analysis shows that both library functions implement essentially the same algorithm of sequential processing, but with different types of function objects. A comparison function object returns a bool, whereas an addition function object returns a copy object of the value type. The small size of bool makes the code using the function std::min_element() slightly more efficient than the code using the function std::accumulate(). At the same time, this difference in the binary function objects is responsible for the loss of generality of the function std::min_element().
In large scale applications, the advantage of a slightly better performance of the function std::min_element() may become counterproductive. The simple sequential search has linear computational complexity, which is unacceptable for high performance applications. Linear inefficiency of sequential processing is addressed with more advanced algorithms using relatively complex data structures, such as balanced trees. If a replacement is available in an existing library the cost of implementing such a solution is normally not too high. However, if a solution requires the development of new data structures and algorithms, the cost increases quite dramatically.
As an example, suppose that we have an advanced data structure that offers efficient search and update operations and enables the computation of many statistical parameters in logarithmic time using an algorithm superior to that in the function std::accumulate(). The common situation with such data structures is that the implementation limits performance of certain algorithms. In particular, the data structure has the inefficiency that the operations, which find minimum and maximum values in a range, have linear computational complexity.
One typical approach to dealing with this problem is to add to a user algorithm a container, such as std::multiset or std::set. This additional container could provide the necessary efficient search on ordered elements. The implementation of this method might be challenging in practice, since it must synchronize operations on different containers. Another issue of this method is that an inefficient operation on one of the supporting containers can significantly affect performance of a user algorithm.
The discussed example of the generic algorithm parameterized on a binary operation shows how to re-use an efficient algorithm implemented in a class template of an advanced data structure. This method has only a small cost associated with the development of a function object, which represents a specific binary operation, and this cost does not depend on the complexity of an already implemented data structure. This method offers the significant advantage that all of the operations required in user algorithms are supported by only one data structure. The success of this method depends on the quality of the design and implementation of such a data structure.
Design of Advanced Data Structures and Algorithms
Any sequential algorithm takes linear time because of processing each element in a range. In order to improve performance of the algorithm, it is necessary to reduce the number of computational operations. This is possible when elements of a data set are arranged into groups and the algorithm operates on values, which are precomputed for each group. As the data set grows and performance of the algorithm becomes unacceptable, the method can be applied again and again, each time to group the most recently precomputed values.
One of the data structures suitable for implementing this method of performance improvement is a level-linked B+ tree that stores precomputed data in internal nodes. It can support two variants of fast summation algorithms, for a more detailed discussion see [1]. In the context of the generalization of binary operations, of particular interest is the algorithm, which computes a result in any range of consecutive elements. The idea of this algorithm is schematically illustrated in the following figure for the fast summation. For comparison, this figure also shows the standard sequential summation in a linked list. The first operation is the initialization through the assignment operator.
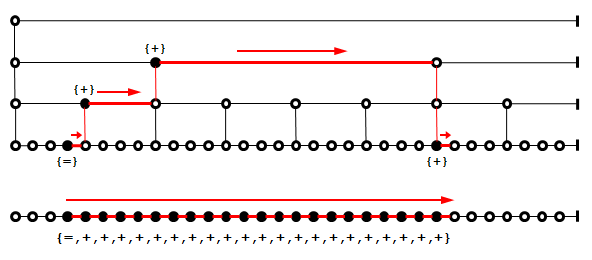
Figure 1: Illustration of a fast summation algorithm using a shortest path between two nodes at the deepest level.
The data structure has an interesting property, which is useful for the improvement of the performance of sequential processing algorithms. A path between two distant nodes at the deepest level is shorter through internal nodes than through nodes at the deepest level. A computational algorithm using a shortest path (not necessarily unique) is the most efficient for such a data structure. It performs the minimum number of binary operations on data stored in the nodes on the path and obtains the same result as the standard sequential algorithm that visits each node at the deepest level.
The values, which are stored in internal nodes of such a data structure, are computed using a binary operation provided by a user algorithm. A parent node stores a result of the binary operation applied to values stored in all of the child nodes. In this way, the binary operation builds its own sub-structure of values.
There is also one special sub-structure that can be implemented for any type of an augmented B+ tree and that does not even require a user provided binary operation. This is a sub-structure of counts of external nodes of a B+ tree that store container elements.

Figure 2: A sub-structure of counts of external nodes and container elements. The bottom line shows the ranks of the external nodes.
The sub-structure of counts enables an augmented B+ tree to efficiently represent a mathematical sequence. Unlike any other sub-structure specific to a user binary operation, the values of counts do not depend on the values of elements in nodes at the deepest level. The sub-structure of counts provides efficient access to an element specified by its rank regardless of whether elements in a container are ordered or not. It supports the fast computation of the distance and the number of elements between any two nodes at the deepest level. It can be used to implement the subscript operator and random access iterators. The counts in internal nodes are also used by the search for a shortest path in the efficient algorithms generalized by binary operations. Because of the importance of these sequence operations and algorithms, the sub-structure of counts is supported by each variant of an augmented B+ tree.
A variant of an augmented B+ tree that supports the fast summation algorithm stores in an internal node both the count of elements and the sum of sum values of its child nodes, which is equal to the sum of all of the values of the elements in a sub-tree rooted at this internal node. The next figure shows the sub-structure of sums only.
Figure 3: A sub-structure of sums of values of container elements.
The sub-structure of sums looks like a more general variant of the sub-structure of counts. When each node at the deepest level stores the integer value 1, these data structures become identical. This fact, however, does not make the count data unnecessary. These sub-structures are similar only because they are built with the same operation of the addition applied to the values of the same type. For other types of a container element and an associative binary operation, the difference between the sub-structure of counts and the sub-structure specific to a user provided binary operation can be much more profound.
The following figure illustrates this fact for the augmented B+ tree that supports the efficient computation of the minimum value. It has the sub-structure of values in internal nodes, which is quite different from both sub-structures discussed before.
Figure 4: A sub-structure of minimum values of container elements.
The sub-structure is built using the binary operation that selects the minimum of two values. The distinctive feature of this data structure is the heap order: the value in a parent node is the minimum of values stored in its child nodes. The heap ordered property enables this data structure to support efficient operations of a priority queue on the whole data set. In this respect, the B+ tree provides the same facilities as a binary heap based on a complete binary tree.
However, compared to a binary heap, the augmented B+ tree offers the additional operations on ranges that have logarithmic running time in the number of elements in a range. The extended facilities of this augmented B+ tree are supported by the sequence representation based on the sub-structure of element counts and the shortest path algorithm. The fast computation of the minimum value in a range uses the same path as the fast summation algorithm (see Figure 1). The only difference is that instead of the addition it uses the binary operation, which selects the minimum of two values.
Semigroup
The choice of a mathematical concept is an important design step in the development of data structures and algorithms. It affects all of the aspects of their effectiveness in user algorithms and the ease of implementing them. The choice is particularly challenging for the generalized variants of data structures and algorithms that combine unrelated operations, such as the addition and the minimum of two values.
From a mathematical perspective, a monoid is a high level concept, which is sufficient to solve a wide range of problems in practice. The definition of a monoid equips a set with an associative binary operation and an identity element. For most binary operations, such as the addition and multiplication, the support for an identity element in programming languages is not a serious complication. However, the minimum and maximum of two values are quite different from other binary operations. Their identity elements have infinite values. For the generalized programming implementation, this is a non-trivial requirement because of the problems of portability and type conversion.
In order to provide a higher level of safety and to avoid complications associated with the representation of infinite values, the class template of an augmented B+ tree models a semigroup instead of a monoid. A semigroup is a more general mathematical concept, which is also simpler from an implementation perspective. A semigroup does not require the support for an identity element. It is specified by a set and an associative binary operation only. The semigroup implemented in the class bp_tree_bin_op, see the file "bp_tree_bin_op.hpp", does not use any sentinels with infinite values and makes no assumptions about specific values that can represent identity elements in user algorithms.
The declaration of the main interface member function bp_tree_bin_op::reduce() is different from the declaration of the function std::accumulate(). The new function requires only a valid non-empty range of elements in a sequence. The initial value is not used to avoid subtle errors caused by default values in minimum/maximum binary operations. The result value is initialized with the value of the first element in the specified range. The function object of a binary operation for this interface function is passed as an argument for the matching template parameter of a container.
The parameterization of the class bp_tree_bin_op with only one type of a binary operation is an important factor for achieving both the generality and efficiency. A specialized algorithm can take advantage of application specific features and deliver better performance than a general algorithm. For example, the sum of any number of consecutive elements in a sequence can be obtained using the method that has constant running time. This fast method stores pre-computed partial sums of sequence elements sum(0, k) in an additional container, such as an array, and computes the required sum using the formula:
sum(m, n) = sum(0, n) - sum(0, m) ;
The high efficiency of this algorithm is achieved by the expense of additional storage and reduced performance of update operations. It is also essential that this method takes advantage of the subtraction, which is the inverse of the addition. The generalization of the described fast method for the computation of the minimum value of any number of consecutive elements is impossible, since there is no inverse operation for the minimum of two values.
The definition of a semigroup broadly covers many types of mathematical objects and does not specify the time and space requirements. The programming representations for some types of mathematical objects may be quite complex. The time and space efficiency of operations is important to make a representation useful in practice. The high performance algorithms supported by the augmented B+ trees discussed here require that the computational complexity of a binary operation be constant. An element in an external node and a precomputed value in an internal node should use a constant amount of space.
An example of an object that does not satisfy these requirements is a string of characters with the binary operation of concatenation. A string is normally represented by a container that uses varying amounts of memory. Technically, an augmented B+ tree can store in external nodes strings as elements of a container. This use of the augmented tree is not efficient, since precomputed strings in internal nodes would use large amounts of memory. The efficient string operations are provided by the relatively simple B+ tree, which is augmented with the count of elements and implements a sequence of characters, see section "Examples" in the project STL Extensions. This variant of an augmented B+ tree is similar to the rope data structure. The string concatenation may be performed by one of the splice() member functions, which has logarithmic running time.
One practical issue, which is important for achieving the high quality of a semigroup representation, is the choice of a data type for a container element. It depends on the safety of an associative binary operation. Some operations, such as the minimum/maximum of two values, logical OR, AND, do not cause any complications. If values of operands are valid, the result is valid too, since it is equal to a value of one of operands. On the other hand, the addition and multiplication operations may produce a result value, which is out of range of a data type. In order to address this issue, C++ provides a wide variety of built-in types and enables programmers to develop user defined types to meet application specific needs.
The integral types and user defined types based on integral types are the most suitable for implementing a semigroup. Their main limitation is caused by overflow and underflow errors in large scale applications. It might be sensible to replace integral types with floating-point types, but there is another potential problem that the computations using the latter types are affected by numerical errors. Strictly speaking, floating-point data types do not satisfy the requirements for associativity of binary operations. Even in the simple case of three variables, there is no guarantee that the floating-point computation of a sum (a + b) + c will provide the same result as a + (b + c). As the number of values increases, the result of computations becomes less accurate. The numerical errors are responsible for the complication that invariants associated with augmented data in internal nodes of a tree may be invalidated. A semigroup based on floating-point types must control accuracy within limits acceptable for an application. The examples in the file "semigroup_demo.cpp" do not use floating-point data types in order to avoid issues of numerical errors.
STL Facilities
This discussion mainly focuses on the generalization of algorithms by binary operations. In addition to this, it is necessary to mention that augmented B+ trees offer a wide variety of efficient search and update operations that enable them to support interfaces of the C++ standard containers: vector, list, deque, set, multiset, map and multimap. The containers based on these trees extend the framework of the standard library. They can be used in complex algorithms as a simple drop-in replacement to avoid inefficiencies that result from the performance of the standard containers. For a more detailed description of the STL extensions based on the augmented B+ trees, refer to the project STL Extensions.
One of the previously developed augmented B+ trees (class bp_tree_array_acc) supports the fast summation algorithm, but it is not suitable for the representation of a semigroup or monoid. The major problem is that its implementation requires the value type provide four C++ operators: +,+=,-,-=. The new variant of an augmented B+ tree (class bp_tree_bin_op in the attached file "bp_tree_bin_op.hpp") addresses this issue by using a single associative binary operation. In this respect, the new tree provides a higher level of generality, extends the application area of the predecessor and allows for the development of more powerful STL facilities based on new containers and algorithms.
The advantage of the new augmented B+ tree can be illustrated for the representation of a priority queue. A binary heap using a complete binary tree in an array suffers from the limitation of a maximum capacity. The representation based on an augmented B+ tree avoids this limitation. Additionally, it supports a sequence and provides various insertion and erasure operations anywhere within a container. Each update operation on such a sequence maintains both the relative order of elements at the deepest level and the heap order in internal nodes.
Since the new augmented B+ tree is a demo variant, it provides a small sub-set of operations of its predecessor. All of the STL compliant member functions developed previously can be implemented in the new class, if needed. The computational complexity of these functions and other operations will be the same. However, the previous variant of the augmented B+ tree can have better absolute values of running times for some operations, since its implementation takes advantage of inverse operations.
Basic Applications
There are two approaches to solving a problem using augmented data structures. Within the first approach, a user algorithm constructs and uses as many augmented B+ trees as needed, one for each specific data type and its binary operation. The second approach uses only one augmented B+ tree, which has a complex structure associated with a combination of all of the relevant data types and binary operations. The choice of the best approach is application specific, since the performance of complex solutions depends on the running times of the most frequent operations.
In simple applications, each specific variant of an augmented B+ tree implements the sub-structure of counts in order to obtain efficient sequence operations and only one sub-structure specific to a binary operation. It can be either the sub-structure of sums of element values for the fast summation or the sub-structure of minimum values to compute the minimum value or find the minimum element in a range. The following code illustrates the computation of the sum of values of container elements in a given range.
std::plus<int> bop_add ;
bp_tree_bin_op< int, std::plus<int> >
semigroup ( bop_add ) ;
sum = semigroup . reduce ( iter_a , iter_b ) ;
The benefit of the generalization is that the use of the member function bp_tree_bin_op::reduce() is simpler than the use of the algorithm std::accumulate() considered in the section "Generalization of Basic Algorithms". The computation of the minimum value differs only in the type of a binary operation.
min_value<int> bop_min ;
bp_tree_bin_op< int, min_value<int> >
semigroup ( bop_min ) ;
val_min = semigroup . reduce ( iter_a , iter_b ) ;
Comparison with Aggregation Trees
The B-tree and B+ tree are the main data structures that store huge data sets in external memory and offer efficient operations on them [2]. SQL provides aggregate functions that can be used for the fast computation of the statistical parameters: min, max, sum, count, avg. These queries are supported by the aggregation tree, which represents a variant of an augmented B+ similar to the one discussed here. A brief comparison of algorithms based on data structures in internal and external memory can provide useful insight into the design of efficient algorithms.
In a B+ tree designed for external searching objects are identified by their keys. For the best performance of search operations on ranges, such a B+ tree stores objects in non-decreasing order of their keys. In terms of the C++ standard containers, a B+ tree for external searching represents an ordered std::multiset or std::set. This type of a tree is not designed for supporting unordered containers. A sequence, such as std::vector, does not place the restriction that elements in a container be ordered. In a sequence, elements are identified by their ranks. The augmented B+ trees discussed here provide efficient operations on ranks through the sub-structure of counts.
Any B+ tree has a structure optimized for sequential access to all of the elements by linking the nodes at the deepest level. However, in B+ trees for external searching, sibling nodes at internal levels are not linked. For this reason, these B+ trees do not support the shortest path algorithm discussed before. The algorithm that efficiently computes statistical parameters of data stored in an aggregation B+ tree is the top down search that starts from the root and passes through all of the levels of the B+ tree [3].
The level linked B+ tree discussed here can also support the top down algorithm, but it is not asymptotically optimal for this tree. The top down algorithm is less efficient than the shortest path algorithm, despite the fact that both algorithms guarantee logarithmic performance. The top down algorithm visits all of the levels of a tree and thus its running time is logarithmic in the total number of elements in a tree. The running time of the shortest path algorithm is logarithmic in the number of elements in a given range, since it visits only as many low levels of a tree as needed.
In the context of the generalization of binary operations, the straightforward implementation of the top down algorithm is not suitable for the representation of a semigroup. The top down order of processing data stored in nodes of a tree requires that a binary operation be commutative instead of associative. In theory, it is possible to guarantee the correct order of processing precomputed data, but this would make the implementation code more complicated. The implementation should also address the issue of identity elements with infinite values for minimum and maximum binary operations.
The high level of generality of the presented augmented B+ trees allows them to support the facilities of aggregation trees. This is an example of an advanced application of augmented B+ trees. It is also a good illustration of the power of generic programming using C++, which enables the low cost development of complex algorithms with a high level of generality and efficiency.
The simultaneous computation of several statistical parameters can be achieved through the use of one augmented B+ tree, which provides the sub-structure of counts plus a combination of several basic sub-structures, such as discussed before. The solution requires a user defined type that collects application specific data to be precomputed and stored in nodes of the tree. In the example code, one container element has the following data:
template < class _Ty_Elem >
struct NodeData
{
_Ty_Elem sum ; _Ty_Elem min ; _Ty_Elem max ; } ;
All of the binary operations on these data are combined in the function object, which is used as an argument for the corresponding template parameter in the class bp_tree_bin_op:
template < class _Ty_Elem >
struct BinOperationNodeData
{
typedef NodeData<_Ty_Elem> NodeDataElem ;
NodeDataElem operator ( ) ( NodeDataElem const & a , NodeDataElem const & b ) const
{
NodeDataElem res ;
res.sum = ( a.sum + b.sum ) ;
res.min = ( b.min < a.min ) ? b.min : a.min ;
res.max = ( a.max < b.max ) ? b.max : a.max ;
return res ;
}
} ;
With this user defined type and binary operation, one call of the function
NodeData<T>
bp_tree_bin_op< NodeData<T>, BinOperationNodeData<T> >::reduce( const_iterator pos_a ,
const_iterator pos_b ) const ;
returns several statistical parameters of consecutive elements: the sum of values, the minimum and maximum values. The running time of obtaining all of these values is logarithmic in the number of elements in a given range.
SemiGroupAddMinMax semigroup ( bin_op_data ) ;
IteratorND iter_a = semigroup.begin() + dist_a ;
IteratorND iter_b = semigroup.begin() + dist_b ;
int count = iter_b - iter_a ;
data_reduce = semigroup . reduce ( iter_a , iter_b ) ;
cout << "semigroup<nodedata>.reduce()" << endl ;
cout << "with the facilities of aggregation trees:" << endl ;
cout << " sum = " << data_reduce.sum << " ;" << std::endl ;
cout << " min = " << data_reduce.min << " ;" << std::endl ;
cout << " max = " << data_reduce.max << " ;" << std::endl ;
cout << " count = " << count << " ;" << endl ;
cout << " average = " << double( data_reduce.sum ) / double( count ) << " ;" << endl ;
</nodedata>
The demo code shows how to compute the count of elements using the difference between two iterators. This is quite an efficient operation, which has constant time. The obtained sum divided by the count provides the average of the values of the elements in the range.
For practical applications, the space efficiency of the example code can be optimized. To avoid data duplication, an external node can store only a container element without any other types of precomputed data required for internal nodes. The demo code does not cover the fast computation of the standard deviation, which is another important statistical parameter. This computation is implemented by storing in internal nodes the additional sums of squared values of elements [1].
Performance
The analysis of performance is important in applications, although it can be a difficult task. The performance of programming implementations of algorithms is not always consistent with abstract models that provide asymptotical computational complexities. In most modern computer systems, physical memory has a few levels of cache with different efficiency of access to data. The running time of a tested algorithm can be affected by complex algorithms of virtual memory management. The cost of an operation, which is constant in a model, in practice is often a function of the problem size.
To get an idea of how useful the efficient representation of a semigroup in C++ is, two systems with different parameters have been tested:
- Windows 7 Professional, 64 bit; PC; processor: Intel i7-3770, 3.40GHz, cores=4, threads=8; RAM=24GB; cache: L1=256KB, L2=1MB, L3=8MB.
- Android v. 4.1.2; Samsung Galaxy III, GT-19305T; processor: Quad-Core Cortex-A9, 1.4GHz; RAM=2GB; cache: L1=32 KB, L2=1 MB.
The main goal of the tests is the measurement of the performance gain, which is offered by the shortest path algorithm compared to the standard sequential processing of all of the elements in a range. It is expected that asymptotically the running time of computations will be improved from linear to logarithmic. The test functions in the attached file "semigroup_performance.hpp" are parameterized on types of a container, its element and a binary operation. The tests can be used to compare performance of the semigroup with that of standard sequence containers. For a container element, three types are currently supported: int, double and complex<double>. As discussed before, type int is not suitable for real world applications due to overflow errors. This type, however, can be helpful to estimate the effect of locality of reference and the computing power of FPU. Each tested algorithm runs in a for loop. The number of test runs can be varied to control accuracy.
For slightly more realistic context, here we consider the performance of the summation of values of type double. A sum of values stored at the deepest level of a tree has been computed with the standard function std::accumulate(). The fast summation of values in the same range uses the function bp_tree_bin_op::reduce(). The first two tables show the running times in microseconds against the number of elements in a range (N). The performance gain is measured as the ratio of running times of the two functions.
The first table shows the results for the Windows system:
| N | 500 | 5,000 | 50,000 | 500,000 |
accumulate() | 0.73 | 7.2 | 73 | 1,620 |
reduce() | 0.064 | 0.080 | 0.11 | 0.140 |
| gain | 11.4 | 90 | 660 | 11,600 |
The second table shows the results for the Android system:
| N | 500 | 5,000 | 50,000 | 500,000 |
accumulate() | 36 | 400 | 4,100 | 42,000 |
reduce() | 3.55 | 4.65 | 5.90 | 7.29 |
| gain | 10.1 | 86 | 690 | 5,760 |
Both tested systems show quite considerable performance improvement as the number of elements in a range increases. Generally, the measured running times are consistent with model performance estimates. The most significant deviation is observed for std::accumulate() at N=500,000 on the Windows system. The super-linear growth of the running time (1,620mcs instead of expected 730mcs) is normally caused by an increase in the number of cache misses. This fact and the fact that the running times of std::accumulate() on the Windows system are better by a factor of about 50 indicate that this system takes advantage of large cache.
The interesting and surprising observation about these tests is that, despite the significant difference in the system parameters and in measured running times, the performance gain is essentially the same for both systems. It is consistent with the expected N / log N gain in the range from 500 to 50,000 elements.
| N | 500 | 5,000 | 50,000 | 500,000 |
| Windows gain | 11.4 | 90 | 660 | 11,600 |
| Android gain | 10.1 | 86 | 690 | 5,760 |
The results of these performance tests suggest that the use of the efficient semigroup in C++ should be beneficial not only in tested, but also in many other types of computer systems.
Using the Code
The attached code has been developed for illustration purposes.
The class template bp_tree_bin_op (in the file "bp_tree_bin_op.hpp") represents a demo variant of an augmented B+ tree that can be used for the development of an efficient semigroup in C++. The main interface member function bp_tree_bin_op::reduce() implements an algorithm of sequential processing that has logarithmic running time in the number of elements in a given range assuming that the cost of an associative binary operation is constant.
The class bp_tree_bin_op has been developed using the augmented B+ tree, which supports interfaces of the C++03 standard containers and the fast summation algorithm, class bp_tree_array_acc in the project STL Extensions. The demo variant of an augmented B+ tree implements a small sub-set of operations of the predecessor. The class bp_tree_bin_op supports only limited facilities of the standard sequence container std::vector.
The file "semigroup_demo.cpp" provides the code for basic and advanced examples discussed in this article.
References
1. V. Stadnik. Fast Sequential Summation Algorithms Using Augmented Data Structures. arXiv:1404.1560, 2014. (http://arxiv.org/abs/1404.1560)
2. D. Comer. The Ubiquitous B-trees. ACM Computing Surveys, 11(2), pages 121-137, 1979.
3. D. Zhang. B Trees. In Handbook of Data Structures and Applications, D. Mehta and S. Sahni (Editors), CRC Press, 2005.

