Introduction
The article evolves the algorithm described in my previous article “An algorithm of “phrases similarity calculation” and its usage in “autocompletion” feature” (http://www.codeproject.com/Articles/638280/An-algorithm-of-phrases-similarity-calculation-and) .
This time I have applied the “phrases similarity calculation” algorithm to a GUI form that displays what I call a two-layer list:
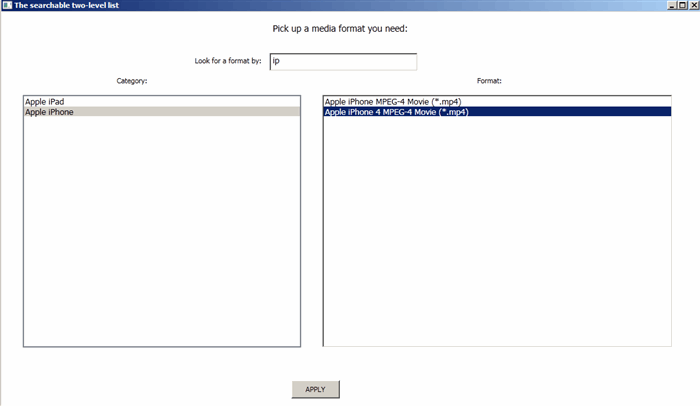
As you see on the screenshot above, the GUI asks a user to select a media format - one of the "Apple iPhone MPEG-4 Movie (*.mp4)", "Apple iPhone 4 MPEG-4 Movie (*.mp4)", "Apple iPad MPEG-4 Movie (*.mp4)" etc. The media formats are gathered into Categories: the Category "Apple iPhone" includes the "Apple iPhone MPEG-4 Movie (*.mp4)", "Apple iPhone 4 MPEG-4 Movie (*.mp4)" etc. A user selects a Category in the Category listbox; then selects a Format in the Format listbox and finally clicks the APPLY button that is supposed to do something with the selected Format. So the name “two-layer list” I use means that the information on the screen is organized on two levels: the Categories are the “upper level” of the hierarchy and the Formats are the “lower level” of the hierarchy. It is also possible to call this approach as a “hierarchical structure with 2 levels of hierarchy”; but I prefer the shortest “two-layer list” definition.
Such a hierarchical GUI organization is the quite standard approach; but I have added there the quick text search by entered keywords – this is the “Look for a format by:” searchbox on the screenshot above. The search filters out the content of the Category and Filter listboxes by the keyword(s) entered; and (what is the most important thing in the article) displays the filtered content in accordance to its relevance to the search query. In other words, the items in the Category and Filter listboxes will be ordered by decrease of their relevancy [to the search query entered].
The article has a Demo application with an implementation of the algorithm attached. The Demo is implemented on C# in form of a WPF Application.
Audience
The possible audience of the article are developers that implement a GUI with large count of “items” – large enough to:
- Have these items be hierarchically organized (gathered into “categories”/”groups”/”folders”/”chapters”/etc)
- Introduce the “quick search” (or “filtering by” – whatever you call it) by entered keyword(s)
An example of this approach is the Control Panel of Windows 7:

The large count of the Control Panel “items” made Microsoft combine them into the groups (“Display”, “Fonts” etc) a long time ago – probably since the first Windows version back in 1980th. But as the count of the items continued to grow, the hierarchical organization became not enough to provide the quick access to the items desired. Microsoft had to also introduce the “quick search” function: you enter a keyword and the Control Panel content is being filtered out.
If your GUI, like Windows Control Panel, has dozens of “items” gathered into many “categories” – it is time to think about adding the “quick search” functionality. The “quick search” will help your end-users finding what they need by simply entering a keyword (or just a couple of initial letters of a keyword). And my algorithm also orders the search results by decrease of their relevancy, thus showing the “most valuable” search results on the top of the lists.
Disclaimers and restrictions
It is necessary to read the previous “An algorithm of “phrases similarity calculation” and its usage in “autocompletion” feature” article prior to reading the given article.
The Demo attached is not a ready-to-use "control" you can "drag and drop" into your application. It is just an example how to implement the approach described in the article.
The Demo is about the specific example with the “media formats” gathered into “categories”; but you can easily use this approach in any GUI where any “items” are gathered into any “categories”.
The attached Demo is a WPF application; but of course this approach may be used in practically any type of GUI applications – for instance, on a Web Page (with JavaScript usage).
The algorithm implementation in the Demo has several "hardcoded" facts that are specific for English language only (a list of the "2nd class words" like "the"). So the Demo should be used with English queries only. If you want to use the algorithm for other languages, then populate the list with the "2nd class words" specific for your language.
Inputs, outputs and usage scenario of the algorithm
The Search algorithm supposes the information is organized as the following 2-level hierarchy: “Folders” that, in turn, may (or may not) contain “Sub-Folders”. Speaking about the Demo attached, the Folders are the media format Categories and the Sub-Folders are the media Formats. For example, the Folder (Category) "Apple iPhone" includes the Sub-Folders (media Formats) "Apple iPhone MPEG-4 Movie (*.mp4)", "Apple iPhone 4 MPEG-4 Movie (*.mp4)" etc.
Every Folder/Sub-Folder has a [non-empty] text description ("Apple iPhone", "Apple iPhone MPEG-4 Movie (*.mp4)"). The keyword search is performed on these texts (let’s call them as “Text properties”). Every Folder/Sub-Folder may also have an arbitrary “data object” associated. The Search algorithm does not consider the “data objects”; they are introduced to associate an object (maybe a complex one) of any type a developer needs (is he/she needs one). For instance, this may be an icon that should be displayed in GUI for a given Folder/Sub-Folder; or anything else.
When a user enters (or modifies) a search phrase (Query) in GUI, the algorithm performs the Search – it looks for the Folders/Sub-Folders that “match” the Query. The Folders/Sub-Folders found will be returned with respect to their relevancy [to the given Query]. If a Folder#1 is “more relevant” than Folder#2, the algorithm will put Folder#1 in the results list before Folder#2.
The relevancy is taken into account for the order of Sub-Folders within a Folder. If, for example, a Search has brought a Folder#1 that contains Sub-Folders Sub-Folder#1 and Sub-Folder#2; and Sub-Folder#1 is “more relevant” (within the Folder#1 scope) than Sub-Folder#2, the algorithm will put Sub-Folder#1 [in the Folder#1 sub-folders list] prior to Sub-Folder#2.
The GUI is supposed to display the Folders/Sub-Folders found in the relevancy-wise order the Search has returned them. In the example below:
the Search algorithm has made a Search by the Query “ip” and brought two Folders – “Apple iPad” and “Apple iPhone”. The algorithm has decided the “Apple iPad” has higher Relevancy Rank than “Apple iPhone”; so the GUI displays “Apple iPad” before “Apple iPhone”.
The “Apple iPhone” brought by the Search contains two Sub-Folders - "Apple iPhone MPEG-4 Movie (*.mp4)" and "Apple iPhone 4 MPEG-4 Movie (*.mp4)". The algorithm has decided the "Apple iPhone MPEG-4 Movie (*.mp4)" has higher Relevancy Rank (within the scope of the “Apple iPad” Folder) than "Apple iPhone 4 MPEG-4 Movie (*.mp4)"; so the GUI displays "Apple iPhone MPEG-4 Movie (*.mp4)" in the first position in the list of the “Apple iPad” Sub-Folders.
A NOTE: as I already said above, the Rank of a Sub-Folder brought by the Search matters only within the scope of its [parent] Folder. In other words, GUI is supposed to display the Sub-Folders of a selected Folder in respect with their Ranks. But whatever Rank of a Sub-Folder is, it does not affect the order the Folders are displayed in their own list (the “Category” listbox in our Demo).
The Overview of the algorithm
We use the algorithms described in the article “An algorithm of “phrases similarity calculation” and its usage in “autocompletion” feature” as the basis. We calculate Rank of (separately) every Folder and every of its Sub-Folders. Then we “combine” all them (Rank of the Folder and Ranks of all its Sub-Folders) into the “final” Rank of the Folder.
Details of the algorithm
We use the algorithms described in the article “An algorithm of “phrases similarity calculation” and its usage in “autocompletion” feature” as the basis. We calculate Rank of (separately) every Folder and every of its Sub-Folders. Then we “combine” all them (Rank of the Folder and Ranks of all its Sub-Folders) into the “final” Rank of the Folder.
When the Search starts, we have a list of the Folders and we have a Query. A Folder may be represented as the following data structure:
- ID property – a unique ID of the Folder;
- Text property – the text description of the Folder (the “Apple iPad”, for instance);
- DataObject property – the “data object” of the Folder; its essence does not matter to the Search algorithm;
- Weight - a number in ]0,….] range that is a “relative weight” of the Folder in comparison to other Folders. Using Weight allows us to make a Folder “more important” in comparison to others or, on the contrary, “less important” in comparison to other Folders. If you do not need this feature – just assign 1.0 to all the Folders you have;
- Sub-Folders list – the list (probably empty) of the Sub-Folders of the Folder.
A Sub-Folder may be represented as the following data structure:
- ID property – a unique ID of the Sub-Folder;
- Text property – the text description of the Sub-Folder (the “Apple iPhone 4 MPEG-4 Movie (*.mp4)”, for instance);
- Weight - a number in ]0,….] range that is a “relative weight” of the Sub-Folder in comparison to other Sub-Folders. Using Weight allows us to make a Sub-Folder “more important” in comparison to others or, on the contrary, “less important” in comparison to other Sub-Folders. If you do not need this feature – just assign 1.0 to all the Sub-Folders you have;
- DataObject property – the “data object” of the Folder; its essence does not matter to the Search algorithm.
The algorithm returns a list of Output Folders. An “Output Folder” may be represented as the following data structure:
- ID property – the ID of the input Folder that corresponds to the Output Folder;
- Rank property – a number that show the “relevancy Rank” of the Output Folder;
- Sub-Folders list – the list (probably empty) of the Output Sub-Folders of the Output Folder
An “Output Sub-Folder” may be represented as the following data structure:
- ID property – the ID of the input Sub-Folder that corresponds to the Output Sub-Folder;
- Rank property – a number that show the “relevancy Rank” of the Sub-Folder;
Let’s also introduce the following constant:
- SubfolderReducingRate = 0.5.
We do the following for every Folder:
1. Apply the “An algorithm of “phrases similarity calculation” and its usage in “autocompletion” feature” algorithm to the Folder (more exactly - to its Text property) and denote the returned value as FolderRank.
Do the following:
FolderRank = FolderRank*Weight [of the folder].
2. Define a variable FinalRank and set 0.0 as its initial value.
3. Iterate all its Sub-Folders and do the following for each of them:
Apply the “An algorithm of “phrases similarity calculation” and its usage in “autocompletion” feature” algorithm to the Sub-Folder (more exactly - to its Text property) and denote the returned value as SubfolderRank.
Do the following:
SubfolderRank = SubfolderRank * Weight [of the Sub-Folder];
SubfolderRank = SubfolderRank * SubfolderReducingRate
If both the FolderRank and is SubfolderRank are 0 (in other words – no matching at all neither for Folder nor for Sub-Folder) – we skip the Sub-Folder and do not add it into the Sub-Folders list of the Output Folder object.
Otherwise we add the new Output Sub-Folder item into the Sub-Folders list of the Output Folder object. The property ID will be filled with the input Sub-Folder ID. The property Rank will be filled with the SubfolderRank calculated.
Do the following:
FinalRank = FinalRank + SubfolderRank
4. After all the Sub-Folders are iterated look into FinalRank calculated.
If it is 0 – we have detected no matching for the Folder.
Otherwise we return the Output Folder object.
Its Sub-Folders list has been built on the Step 3 above (it may be empty). Now we sort the list by decreasing of their Rank values.
Its ID property will be filled with the Folder ID.
Its Rank property will be filled with the FinalRank value.
A NOTE: as you can see from the algorithm, the following logic is used when we make the Output Folder item:
- If the Folder’s Text does match a Query – it is enough to include all the Sub-Folders into the Sub-Folders list (even if their Texts do not match the Query at all);
- A Sub-Folder will not be included into Output Folder Sub-Folders list only when it does not match to the Query and the Folder’s Text does not match to the Query
After all the Folders are iterated, we sort the list of the Output Folder objects by decreasing of their Rank values. The sorted list will be returned as the Search Results of the algorithm.
The implementation
The Demo attached is a simple implementation of the algorithm on C# /WPF. It is about the specific example with the “media formats” (Sub-Folders in terms of the algorithm) gathered into “categories” (Folders in terms of the algorithm). A user is supposed to filter the Category and Format lists by entering a Query in the “Look for a format by:” field:
Then the user is supposed to select a Category in the Category listbox; then select a Format in the Format listbox and finally click the APPLY button that is supposed (if this was a real application instead of the Demo) to do something with the selected Format.
The Folder/Sub-Folder “data objects” and the Weights are not really used in the given example: the Search algorithm supports them, but the GUI does not fill them. So all the Folders/Sub-Folders have the same default value 1.0 of Weight property.
The GUI uses the “try to save the User’s selection” principle when updating the Category and Format lists when the user types in a Query. I mean the following. Suppose a user has typed in the “touch” query and the current situation on the screen is the following:
Then the user, say, replaces the Query “touch” with “i”:
As you see on the screenshot above, the previously selected Category and Format items remain selected, despite the Category and Format lists have been reloaded with several new items.
Now let’s consider a more complicated situation. Suppose the situation on the screen is the following:
Then the user, say, replaces the Query “wmv” with “mp4”:
As you see on the screenshot above, the previously selected Category (the “Microsoft Zune”) remains selected after the replacement. In this situation it is impossible to preserve the selection on the previously selected Format (the "Microsoft Zune WMV Movie (*.wmv)") since it has gone (was filtered out by the new Query). But the GUI at least preserves the selection of the Category; and automatically selects the other its Format that is displayed for the new Query – the "Microsoft Zune MPEG-4 Movie (*.mp4)".
In other words – when the Query field changes and the Category and Format lists are reloaded because of the change, the GUI tries (if this is possible) to preserve the previously used selection for Format and/or for Category lists.This is implemented in the MainWindow.txtQuery_TextChanged method.
The folder AutocompletionEngine comprises all the logic of the Search Algorithm.
The static list AutocompletionEngine.Processor.Word.ArticlesEtc contains the hardcoded list of the "second class" words (see the Similarity factor). If you want the algorithm to work correctly with non-English queries, populate the list with "second-class words" of your language.
The folder UnitTest contains the set of NUnit-based automated tests of the AutocompletionEngine.Processor class. This is why the project requires nunit.framework.dll library.

