Introduction
The Little Text Transform Language (LTTL, pronounced "little") lets your application's user enter a simple formula that transforms one or more input values to produce an output piece of text. You define the input values; the only real requirement is that each input value has a name and can be converted to a string. The formula is compiled into an internal representation, which lets you use LTTL to process large numbers of records without going through the parsing process for each one.
Background
LTTL arose from a feature I added to our in-house debugging tool at work. The tool records network messages from a group of distributed services and applications. Each message includes several fixed-purpose fields and a free-form text field. We often need to extract data from these recorded messages for use in analysis or for documentation. The extraction process is messy, requiring a trip or three through a text editor, painful formulas in Excel, or both. What we needed was a simple way to identify the bits we wanted, extract parts of interest, and string them together in forms that were useful.
This article is a story about how I implemented LTTL, as much as it is about LTTL itself. Since this was not work for a particular product and I did some of it on my own time, things got out of hand. Rather than just writing code, I discovered I had to define a grammar[^]. That grammar defined tokens and the relationships between them. If you want to add parenthetical expressions to your language (which I did), you start talking about "LL(k) parsers[^]", "recursive descent parsing[^]", and "abstract syntax trees[^]".
"But I'm not afraid!"
"You will be... You will be."
When I work on a problem, most of the time I work from what I know and understand toward what I don't know. Some of the steps I took may seem out of order to you.
Step 0: Finding an Acronym (*)
When I was little, one of my favorite stories was The Little Engine That Could[^] by 'Watty Piper', a pseudonym for Arnold Munk. While I was working on this project it struck me how useful a 'little' language could be, my brain brought up this association, and there we are. (*) This was actually the last step but it makes more sense to talk about it here, plus it explains the test program icon.
Step 1: Defining the Grammar
Many of you will cite the time-tested tools out there to accomplish these tasks: lex, yacc, Bison, and so on. These tools all had a pronounced learning curve and the literature weighs heavily toward the academic merits of one tool or one approach over another. Most of the tools are based on 'C', and I wanted something that didn't require three layers of pointer indirection to find anything. Practical advice seemed hard to find. With my trusty KISS principle in hand, I dove in.
When we hand-edited our data, it was always the same: find the text we want, extract it, find/replace some parts, and add constant text in places. I'm an old guy, so I remember using a lot of command-line editors: TECO[^], EDLIN[^], and so on. From that experience, I came up with pretty simple requirements for my language. Keep the syntax as minimal as possible, as this is intended for something that's used and thrown away when no longer needed. I didn't want users thinking of this as programming, but more like entering a formula in a spreadsheet cell. Make it easy to handle text in either a case-sensitive or case-insensitive way.
Formula Syntax
e1 e2 ...
... eN
It's that simple. A formula is one or more expressions (e1 through eN), separated by spaces, tabs, or line breaks. Line breaks in the formula are passed as-is to the output. What's an expression? Funny you should ask. An LTTL expression is a variable name or a constant string, optionally combined with an operator and any operands required. The definition is recursive, in that operands may be other expressions.
Variables
In my original application, I had a list of 'variables' which were names of fields in each message. Since I knew that the folks using this wouldn't have the patience to type "Connection" or "EventTime", I gave each item a one or two character synonym. I also made variable name matching case-insensitive, since doing otherwise would be annoying and nit-picky.
Side note: For the demo/test program, I defined six variables: alpha (synonym "A"; simple text), beta ("B"; simple text), gamma ("G"; an int), delta ("D"; a double), epsilon ("E"; an enum), and zeta ("Z"; a bool). I'll be using these in the discussion that follows.
Constants
Another thing I needed was constant text: text to be inserted between items extracted from variables, search text, and so on. Double quotes delimit "case-sensitive" constants, and single-quotes mark 'case-insensitive' constants. As it turns out, this wasn't sufficient to meet what I wanted for handling case-sensitivity, but we'll get to that in a minute. I added escape sequences for single quotes, double quotes, carriage returns, and line feeds. The latter two aren't strictly necessary, but they were easy to add and might make some formulas easier to read.
Operators
When I first started this project, I had a vague notion of a formula being one or more "expressions" separated by spaces that were evaluated to produce the output text. My first Eureka moment was when I realized I had my first operator: a space character is actually a concatenation operator. Not to go overboard, I decided multiple consecutive spaces or tabs meant a single concatenation operation. If our alpha variable is "Little", beta is "Transform", and the formula is:
"LTTL: " alpha " Text " beta " Language"
then the output will be:
LTTL: Little Text Transform Language
The second operator was extraction: find a piece of text in a value at a beginning position and extract characters until an end position is found. Sounds simple, no? The extraction part is easy. Specifying the beginning and ending positions is the hard part. Sometimes you know exactly how many characters from the beginning to start, and how many characters to extract. Other times you need to first find a string, then move over so many characters, and extract until you find another string. It may take several steps to find the positions in the data. With that in mind, I arrived at the following syntax for the extraction operator:
expr.b.e
The expr at the beginning is the source you want to extract text from. It can be a variable name, a constant, or another expression in the language. The period '.' is the extraction operator. The 'b' value tells how to find the beginning point of the extraction, where the start is position zero. If b is a positive number, it is an offset from the beginning of the string. If b is a double-quoted string "like this", LTTL searches forward for a case-sensitive match. Similarly, if b is a single-quoted string 'like that', LTTL uses a case-insensitive match. The string position searches include the search string as part of the extracted result. The value e has the same syntax, but uses the b position as a starting point. The result of the expression is the text between the beginning and ending positions.
I added obvious shortcuts: expr.b extracts the text from the beginning point b to the end of the expr value. expr..e extracts from the beginning of the expr to the ending point e. Note that this is the same as specifying a formula of expr.0.e.
The key to making this flexible was to allow multiple b and multiple e values, and apply them sequentially. The final syntax is this:
expr.b[;b][;b][.e][;e][;e]
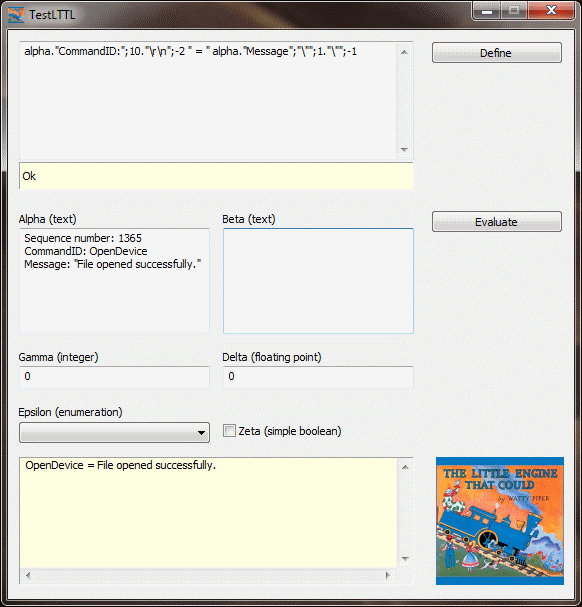
The semicolons separate consecutive b and e values. Kind of ugly, but an example will make things clearer. Suppose the alpha variable contains:
Sequence number: 1365
CommandID: OpenDevice
Message: "File opened successfully."
and the formula is:
alpha."CommandID:";10."\r\n";-2 " = " alpha."Message";"\"";1."\"";-1
You might read this formula as:
- Start at the beginning of the
alpha variable. - Search until you find "CommandID:".
- Move forward 10 characters.
- Extract from here to the end of the current line. Back up two characters to omit the line break.
- Add " = " to the output.
- Start at the beginning of the
alpha variable. - Search until you find "Message".
- Search until you find the open quote.
- Move forward one character to skip over the open quote.
- Extract until you find the closing quote. Back up one character to omit the quote.
When evaluated, the following output is produced:
OpenDevice = File opened successfully.
The other operator I really had to have was replacement: given an expression, replace all occurrences of one string with another:
expr*f[*r]
where expr is the source of the text, * is the replacement operator, f is an expression of the text to be found, and r is an expression for the replacement text. Note that the second replacement operator and the replacement expression are optional. This means you can use the replacement operator to remove all occurrences of a given string from an expression.
Next is a limited form of the 'C' conditional operator:
e1 comparison e2 ? e3 [: e4]
or:
e1 ? e3 [: e4]
where e1, e2, e3, and e4 are expressions. The comparison operator can be ==, !=, <, <=, >, >=. I also defined two new comparisons: ^ (contains) and !^ (does not contain). The containment comparisons evaluate to true if the e2 expression is found anywhere in e1. Containment uses a case-insensitive match if either operand is marked as case-insensitive.
Unlike in 'C' and C++, the 'else' clause : e4 is optional. There are no logical operators (AND and OR). You can achieve the effect of logical-AND by making the 'then' clause of a conditional operator another conditional operator. Logical-OR is simply two conditional operators in sequence.
The second form of the conditional operator is another shortcut. If the expression e1 is non-blank, expression e3 is produced, and expression e4 if otherwise.
An expression in LTTL can be a variable, a constant, one of the operator expressions, or a group of these elements separated by spaces, tabs, or line breaks and surrounded by parentheses ( and ). If you place a plus sign (+) in front of an LTTL expression, it is treated as case-sensitive, and a minus sign (-) makes it case-insensitive.
Step 2: Defining the Interface
I wanted the interface for LTTL to be as simple as possible, and to keep the implementation hidden. Another design goal was to have all errors detected during the 'compile' step, when the formula was being parsed into the internal representation. My use case was to define the formula once, but evaluate it many times. Signaling errors during evaluation would have been obnoxious. The worst-case behavior at evaluation time is to return an empty string.
namespace LTTL
{
class Variables
{
public:
Variables()
{ };
virtual ~Variables()
{ };
virtual const CStringArray& Names() = 0;
virtual CString Evaluate(void *context,CString name) = 0;
};
class Expression;
class Formula
{
public:
Formula();
virtual ~Formula();
bool Define(CString definition,
Variables *variables);
CString Error();
int ErrorOffset();
CString Evaluate(void *context);
protected:
CString _Definition;
Variables *_Variables;
CString _Error;
int _ErrorOffset;
Expression *_Group;
};
};
Sidebar: Yes, I'm using MFC CString's and collection classes. My target environment was a venerable MFC application. It would be relatively minor to rework the code to use STL or other library.
You supply an instance of a class derived from the abstract Variables class. The Names() member returns an array of the variables names you would like to support. The Evaluate() member is called by LTTL to evaluate a variable specified by name and the context value, returning the string form of the variable. Since name recognition for a specific value is entirely up to you, you may have multiple names for the same value. I used this to provide shorter 'synonym' names.
The Formula class is the LTTL implementation. Pass the formula definition (the user-supplied string) and your variables to the Define() member. It returns true it the definition was valid, and false otherwise. If Define() returns false, you can use the Error() and ErrorOffset() members to retrieve a description of the problem and its offset from the beginning of the definition string. I used this in the test program to display a message below the definition, and to reposition the cursor in the definition edit control to the problem location.
You call the Evaluate() member to evaluate a string based on the supplied context. The context value is a void pointer that is treated opaquely by LTTL. Typically this will be a pointer to a class containing actual values of the variables defined in your Variables implementation. In the test program, the Variables implementation and the context are supplied by the same class. This is not a requirement; you can use whatever approach suits your needs. Evaluate() returns a string. The worst-case return value is an empty string ("").
You'll note the only place the underlying implementation peeks out is in the forward declaration of an Expression class, and a protected member that is a pointer to an instance of it.
Step 3: Organizing the Implementation
The first step in my 'compile' process is to convert the string definition into a list of tokens, so I knew I would need a Token class. It also seemed reasonable to have a base class for expressions (called Expression, naturally), and to derive each specific expression type from that base class. I chose to use exceptions internally for error handling. Given that this code was going to be recursive at some point, and that it was logically 'dense' as well, this seemed appropriate.
In a departure from normal best practices, I decided to place the entire implementation in a single .cpp file. The internal class definitions are inline with their declarations. I did this to make it easier to drop LTTL into other applications.
Step 4: Building the 'lexical analyzer'
A lexical analyzer[^] is the code that converts an input stream of characters into a sequence of tokens. I had the following types of tokens:
enum TokenType
{
Unknown,
Break,
Constant, CONSTANT,
Variable,
ForceCaseSensitive, ForceCaseInsensitive,
Replace, Extract, Position, Number,
Equal, NotEqual, LessThan, LessThanOrEqual, GreaterThan, GreaterThanOrEqual, Contains, NotContains,
Conditional, ConditionalElse,
Open, Close };
The Constant, CONSTANT, Variable, and Number token types also have an associated value.
This was the easiest part of the application to write. I used a finite state machine, with a state for each type of token in the grammar, plus an initial/terminal state of 'unknown'. I've written this sort of code many times before, so I didn't need a state diagram. The following is an outline of the code, implemented in the Formula::Define() member function:
bool result = true;
List<Token> tokens;
try
{
Token::TokenType type = Token::Unknown; CString value;
int offset = 0;
int length = _Definition.GetLength();
while (offset < length)
{
char current = _Definition[offset];
char next = '\0';
if (offset < (length - 1))
{
next = _Definition[offset + 1];
}
switch (type)
{
case Token::type:
switch (current)
{
case character:
handle character according token type
break;
}
break;
}
}
}
catch (FormulaException *exception)
{
result = false;
}
The state machine loops through the characters in the definition string one or two characters at a time. It uses a single character lookahead (the next value) to short-circuit some of the state transitions. This simplifies handling escape sequences and the comparison operators in the conditional expressions. The outer switch statement is on the state variable type, the type of the current token. For each state, there is usually an inner switch statement on the current character. The state handling can add the character to the current token's value, complete the current token and add it to the list, change states to another token type, a combination of those actions, or signal an error by throwing a FormulaException as needed.
Step 5: Creating the Expression Handlers
I knew I would need code to handle each type of expression, so next I created classes for each, all derived from an abstract base Expression class:
class LTTL::Expression
{
public:
enum ExpressionType
{
Constant,
Variable,
Replace,
Extract,
Offset,
Position,
Conditional,
Comparison,
Group
};
Expression();
virtual ~Expression();
virtual ExpressionType Type() = 0;
virtual CString Evaluate(void *context) = 0;
bool CaseSensitive;
int SyntaxOffset;
};
Each expression returns its type and evaluates itself according to a context. The expression may be case-sensitive (or not). Finally, the initial offset of the expression in the original definition is recorded during the parsing process.
The Constant expression type implements constant strings, while the Variable handles variables. The Replace, Extract, and Conditional types implement their respective operators. The Offset and Position expressions support the operands to the extraction operator, while the Comparison type supports the conditional operator. The Group expression type implements nesting expressions in parentheses.
Step 6: Creating the Parser: Converting a Stream of Tokens into an Efficient Representation
I now had the 'lexical analyzer' working pretty well. It even handled some of the syntax checking I needed. I now had to convert the list of tokens into some kind of structure that related the various Expression classes I created.
Oh boy.
I started coding this inline in the Formula::Define() member function, as that's where the parsing process was needed. Fairly quickly I realized this was a mistake. From my reading, I remembered that parsers tended to be recursive, so I refactored the parsing code into it's own function. Aha! With the little bit of parsing code I had written in its own function, I recognized something that now seems very obvious. The basic formula syntax e1 e2 e3 ... eN is actually the interior of an expression grouped by parentheses. I then made the parsing function a member of the GroupExpression class (which handles parentheses), and made the outermost expression an instance of that class. This is why in the LTTL.h file the expression member is called _Group.
With that, I started fleshing out the parsing code. I had an outer loop iterating over the list of tokens constructed by the lexical analysis step. The body of the loop was a switch on the token type. I had a 'working' instance of an Expression class object. Based on the current token type, I would either add information to the working instance, or add that instance to the current group expression's list and create a new working instance. I eventually had a complete parser built into a single function. It even recursed for nested parenthetical expressions.
The code was long and somewhat repetitive. There was a lot of duplicated code in places, except for minor differences in each duplication. It was functional, so I went ahead and used it in a new release of our diagnostic tool.
This had been a really fun project, so I told some programmer friends about it. They encouraged me to write a CP article, so I extracted the code from our tool source and got started. It was fairly easy to abstract the 'variables' notion from the original code to the Variables class I described above. I added a simple test program, and started writing the article. When I got to "Step 6: Creating the Parser", I got stuck. The parser wasn't right. While it seemed to work, it had limitations. The extraction and replacement operators could not have white space around them, as the parser considered that a 'break' condition for the current expression. Validation missed some cases, and fixing a couple of those just made it more obvious that the approach wasn't right. It irritated me that the various Expression classes didn't handle their part of the parsing and validation processes.
The most glaring fault in the original code was the fact that the parser 'knew' too much about the interior of the various expression classes. There had to be a way to refactor the parsing so that those classes implemented their part of the task. I knew the key was in the original code's use of a 'working' expression that was either added to or replaced by the product(s) of handling the current token. I added a new virtual member to each of the Expression classes that looked something like this:
Expression *Parse(Token *token,
Expression *current)
{
if (current can be used by this expression)
{
add current to this expression
current = NULL;
}
return current;
}
I then moved all of the 'expression type'-specific bits to their respective Parse() member functions. With this change, it seemed closer. The body of the original parser was now much smaller, and the expression type-specific logic was where it belonged. I looked at the implementation of the Parse() functions, and realized that none of them used the token argument, so I removed that. The parser now consisted of constructing new expression objects and then passing them to the current working object's Parse() function.
Things still seemed a little clunky, until I remembered a phrase I'd seen in one of the parsing algorithm descriptions. It was about expressions consuming tokens. I think I finally found the biggest piece of the puzzle.
The parser (still part of the GroupExpression class) traverses the list of tokens. It has an instance of a 'working' expression that is initially NULL. Based on the current token type, it creates a new Expression class instance called current. If the working instance is NULL, the working instance is set to the current instance, and the traversal continues to the next token. If the working instance is not NULL, however, pass the newly created 'current' expression instance to the working instance's Parse() function. If the working expression uses the 'current' instance ('consumes' it), it returns NULL. If it can't use it, it returns the current instance.
The parser now looks something like this:
Expression *working = NULL;
for (token in token_list)
{
Expression *current = NULL;
switch (token->Type)
{
case type:
current = new ExpressionType(...);
break;
}
if (working != NULL)
{
current = working->Parse(current);
if (current != NULL)
{
working = current;
add working to GroupExpression list of expressions
}
}
else
{
working = current;
add working to GroupExpression list of expressions
}
}
The last refinement to the process came about when I was still having trouble with the validation. I finally realized that some of the Expression classes I was creating in the main body of the parser could simply consume the working expression instance when they were constructed, rather than trying to grab them while they were being parsed. For example, the both extraction operator and the replacement operator work on a 'source' expression. This source expression is the current working instance when the first extraction or replacement operator in one of those expressions is found. This helped move the validation for those values into their respective expression classes, and the parser was finally complete. Whew.
Final Step: The Test Program
Of course, I had a fair amount of the test program already in place while I was writing and debugging the LTTL classes, but that wasn't essential to the story. The biggest effect the test program had on the LTTL classes was the addition of an integer SyntaxOffset member variable to the Token and Expression classes. This value records the offset of the token and it's associated Expression instances in the original definition string. When the LTTL code needs to signal an error, it constructs a FormulaException using the appropriate SyntaxOffset value and a string describing the error and throws the exception. The exception is caught at the outer boundary of the Formula::Define() function and the offset and error values are saved for later retrieval if the application needs them.
Points of Interest
There are further opportunities for LTTL. The current code could be reworked slightly to use STL string and collection classes. A .NET version would require writing a version in C#, but the logic would follow closely. The current debugging code (the ToString() functions you see sprinkled about) were influenced by my .NET background.
The Variables class defined by the outside application could be enhanced to implement application-specific comparisons. As an example, an enumeration value could perform comparisons based on the order of the enumeration values, rather than the order of their string representation. The conditional expression could be enhanced to support logical operators and parenthesized logical expressions.
Another enhancement would be the addition of 'intrinsic' functions. These functions could provide case conversions, leading/trailing space trimming, and similar operations.
A last enhancement which was in the LTTL at one point was support for regular expressions. I originally planned to allow regular expressions to be used for the position arguments of the extraction operator, the 'find' operand of the replacement operator, and so on. I was getting distracted by the requirement to manage regex context values, so I removed it.
History
- April 6, 2015 - Original publication

