Introduction
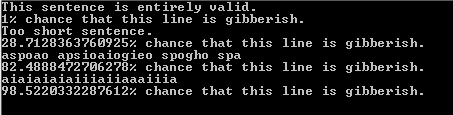
This Gibberish Classification algorithm aims to detect whether text is valid, or randomly typed in a keyboard. It returns a percentage where a low one means valid text, and a high one means gibberish text. The algorithm is at a pretty early stage, so there are still some incorrect return values.
If a result is lower than 50%, it's likely that the text is valid. If a result is higher than 50%, it's likely that the text is gibberish. The algorithm is optimized for the English language and for longer text; it will still work for shorter text (for example, one sentence), but then the results will be less accurate. The algorithm won't give a percentage lower than 1%, except if the input string is null or empty, then it returns 0%.
The C# implementation can be used for the .NET Framework 4.0 and higher (the binary in the download targets .NET 4.5).
The Python implementation can be used in both Python 2.x and Python 3.x.
The source code can also be found on GitHub: C# implementation, Python implementation.
The Algorithm
The algorithm checks three things, then calculates the final score:
- It checks whether the amount of unique chars (in %, in chunks of 35 chars) is in a usual range.
- It checks whether the amount of vowels (in %) of the letters is in a usual range.
- It checks whether the word/char ratio (in %) is in a usual range.
Checking the unique characters
To check the % of unique characters, we first split the string in chunks of 35 characters. When doing this, it can happen that the last chunk does not have 35 characters -- in this case, if the chunk size is less than 10 characters, add these chars to the chunk before the last and delete the last. (This is only possible if there are 2 chunks or more)
After splitting the string into chunks, create an empty list. Then loop over all chunks. Calculate the amount of unique characters in the current chunk. Then divide it by the total amount of characters in the chunk and add it to the list.
After doing the above, calculate the average of the list, multiply it by 100, and return it.
That calculates the percentage of unique characters in chunks; checking whether it is in a usual range is done later.
Checking the vowels
When checking the amount of vowels, first initialize an integer vowels and total. We run over each character in the given string. If the character is not an alphabet letter, continue without doing something for that letter. If it is an alphabet letter, increase total by 1 and check whether it is a vowel: if it is, increase vowels by 1. After running over all characters, return vowels / total * 100.
Checking the word/char ratio
To check the word/char ratio, split the string by the regex [\W_] (splitting by all non-word characters and an underscore). Then remove all whitespace-only/empty items from the resulting array. Thereupon, divide the amount of words by the amount of chars, multiply it by 100 and return it.
Calculating "deviation score"
The above functions all return a percentage, but we cannot directly use these to calculate the final score -- first we have to calculate how much the percentage deviates from the usual range, and then give it a score. The higher this score, the more the percentage deviates.
The function to calculate this score has to accept three arguments: the given percentage, the lower bound of the usual range and the upper bound.
- If the percentage is lower than the lower bound, return
log(lower_bound - percentage, lower_bound) (where the second argument is the base).
- If the percentage is higher than the upper bound, return
log(percentage - upper_bound, 100 - upper_bound).
- If the percentage is none of the above (meaning that it's in the usual range), return
0.
Calculating the final score
Using all above functions, we can calculate the final score! First we calculate the percentages using the first three functions.
Then, we call the deviation score for each of them:
- For the vowels %, the lower bound is 45 and the upper bound is 50 ->
deviation_score(percentage, 45, 50) - For the unique chars %, the lower bound is 35 and the upper bound is 45 ->
deviation_score(percentage, 35, 45) - For the word/char ratio, the lower bound is 15 and the upper bound is 20 ->
deviation_score(percentage, 15, 20)
Where do I get these bounds from? Just from testing and running some paragraphs taken from the internet through all 3 functions.
After calculating these deviation scores, we go through them and we set them to 1 of they are lower than 1. The reason for this is that we are going to call log10 on these scores; having a score lower than 1 can lead to a negative logarithm (or an error in case of zero), which is undesired.
The next step is to calculate the logarithm on base-10 for all deviation scores and divide this by 6. (6, because the max number we can get from the log10 operation is 2, and we have three operations here). We return max(final_score, 1). We do not return the exact final score if it's below one because even if the final score is 0%, it's not impossible that the entered text is gibberish; it's just unlikely. The higher the final score, the higher the chance that a string is gibberish.
C# and Python implementation
In the C# implemenation, all methods are static and put in a GibberishClassifier class.
In the Python implementation, all methods are put in a gibberishclassifier module. The Python version works in both Python 2.x and Python 3.x. Because the Python 2.x division truncates by default, we have to add this at the top of the file:
from __future__ import division
After doing that, division won't be truncating anymore in Python 2.x.
The first implemented method is the method to split a string into chunks. The C# method uses a for loop and Substring to take the appropriate amount of characters. The Python method uses a for loop, range and the slice notation.
public static List<string> SplitInChunks(string text, int chunkSize)
{
List<string> chunks = new List<string>();
for (int i = 0; i < text.Length; i += chunkSize)
{
int size = Math.Min(chunkSize, text.Length - i);
chunks.Add(text.Substring(i, size));
}
int lastIndex = chunks.Count - 1;
if (chunks.Count > 1 && chunks[lastIndex].Length < 10)
{
chunks[chunks.Count - 2] += chunks[lastIndex];
chunks.RemoveAt(lastIndex);
}
return chunks;
}
def split_in_chunks(text, chunk_size):
chunks = []
for i in range(0, len(text), chunk_size):
chunks.append(text[i:i+chunk_size])
if len(chunks) > 1 and len(chunks[-1]) < 10:
chunks[-2] += chunks[-1]
chunks.pop(-1)
return chunks
Then the method to get the percentage unique chars per chunk is implemented. It uses the above method.
The C# implementation uses .Distinct().Count() to get the count of unique characters in one chunk, and .Average() to calculate the average of all percentages of unique characters in the chunks.
The Python implementation uses len(set(chunk)) to get the amount of unique characters in one chunk, and it uses sum to get the sum of all percentages, which gets divided by the amount of all percentages.
public static double UniqueCharsPerChunkPercentage(string text, int chunkSize)
{
List<string> chunks = SplitInChunks(text, chunkSize);
double[] uniqueCharsPercentages = new double[chunks.Count];
for (int x = 0; x < chunks.Count; x++)
{
int total = chunks[x].Length;
int unique = chunks[x].Distinct().Count();
uniqueCharsPercentages[x] = (double)unique / (double)total;
}
return uniqueCharsPercentages.Average() * 100;
}
def unique_chars_per_chunk_percentage(text, chunk_size):
chunks = split_in_chunks(text, chunk_size)
unique_chars_percentages = []
for chunk in chunks:
total = len(chunk)
unique = len(set(chunk))
unique_chars_percentages.append(unique / total)
return sum(unique_chars_percentages) / len(unique_chars_percentages) * 100
The next method is the method to get a percentage of the vowels.
The C# method uses !Char.IsLetter to check if a char is not a letter; in that case, we go to the next char in the string. If it is a letter, it increments the total variable and it checks whether it is a vowel using "aeiouAEIOU".Contains(c). If it is a vowel, in increments the vowels variable. At the end of the method, it returns the percentage if total is not zero, and if it is zero, then the method returns 0.
The Python method uses not c.isalpha() to check if a chat is not a letter; in that case, we go to the next char in the string. If it is a letter, it increments the total variable and it checks whether it is a vowel using c in "aeiouAEIOU". If it is a vowel, in increments the vowels variable. At the end of the method, it returns the percentage if total is not zero, and if it is zero, then the method returns 0.
public static double VowelsPercentage(string text)
{
int vowels = 0, total = 0;
foreach (char c in text)
{
if (!Char.IsLetter(c))
{
continue;
}
total++;
if ("aeiouAEIOU".Contains(c))
{
vowels++;
}
}
if (total != 0)
{
return (double)vowels / (double)total * 100;
}
else
{
return 0;
}
}
def vowels_percentage(text):
vowels = 0
total = 0
for c in text:
if not c.isalpha():
continue
total += 1
if c in "aeiouAEIOU":
vowels += 1
if total != 0:
return vowels / total * 100
else:
return 0
After that method, the method to calculate the word/char ratio comes.
The C# method uses the Regex.Split method (in System.Text.RegularExpressions) to split the string. Then it uses the LINQ .Where method to remove all parts that are whitespace-only (it uses the String.IsNullOrWhitespace method to check that), and the Count() method to get the amount of words.
The Python method uses re.split (requires import re) to split the string, and it uses x for x in ... if ... to remove all whitespace-only parts. It uses x.strip() != "" to check whether a string is whitespace-only or empty. Then it uses the len method to find out the amount of words.
public static double WordToCharRatio(string text)
{
int chars = text.Length;
int words = Regex.Split(text, @"[\W_]")
.Where(x => !String.IsNullOrWhiteSpace(x))
.Count();
return (double)words / (double)chars * 100;
}
def word_to_char_ratio(text):
chars = len(text)
words = len([x for x in re.split(r"[\W_]", text) if x.strip() != ""])
return words / chars * 100
The next method is the one to calculate the deviation score. The C# implementation uses Math.Log for this, and the Python one uses math.log (requires import math):
public static double DeviationScore(double percentage, double lowerBound, double upperBound)
{
if (percentage < lowerBound)
{
return Math.Log(lowerBound - percentage, lowerBound) * 100;
}
else if (percentage > upperBound)
{
return Math.Log(percentage - upperBound, 100 - upperBound) * 100;
}
else
{
return 0;
}
}
def deviation_score(percentage, lower_bound, upper_bound):
if percentage < lower_bound:
return math.log(lower_bound - percentage, lower_bound) * 100
elif percentage > upper_bound:
return math.log(percentage - upper_bound, 100 - upper_bound) * 100
else:
return 0
The last method is the one to do the actual classifying. If the inputted string is empty or null (C#) or None (Python), it returns 0%. It calls the above methods, calculates the deviation score and calculates the final score, as the algorithm describes.
public static double Classify(string text)
{
if (String.IsNullOrEmpty(text))
{
return 0;
}
double ucpcp = UniqueCharsPerChunkPercentage(text, 35);
double vp = VowelsPercentage(text);
double wtcr = WordToCharRatio(text);
double ucpcpDev = Math.Max(DeviationScore(ucpcp, 45, 50), 1);
double vpDev = Math.Max(DeviationScore(vp, 35, 45), 1);
double wtcrDev = Math.Max(DeviationScore(wtcr, 15, 20), 1);
return Math.Max((Math.Log10(ucpcpDev) + Math.Log10(vpDev) + Math.Log10(wtcrDev)) / 6 * 100, 1);
}
def classify(text):
if text is None or len(text) == 0:
return 0.0
ucpcp = unique_chars_per_chunk_percentage(text, 35)
vp = vowels_percentage(text)
wtcr = word_to_char_ratio(text)
ucpcp_dev = max(deviation_score(ucpcp, 45, 50), 1)
vp_dev = max(deviation_score(vp, 35, 45), 1)
wtcr_dev = max(deviation_score(wtcr, 15, 20), 1)
return max((math.log10(ucpcp_dev) + math.log10(vp_dev) +
math.log10(wtcr_dev)) / 6 * 100, 1)
History
- April 17th, 2015: Return 0% for an empty string.
- April 9th, 2015: Don't divide by zero if there are no alphabet letters in the string (at the method to calculate vowels %).
- April 8th, 2015: First version.

