Introduction
Each of you knows, to convert raw Bytes to readable Strings and vice-versa, you need a conversion-algorithm, namely an "Encoding". There are several Encodings available, and problems come up, when you read a file using another Encoding than the one, which wrote the file:
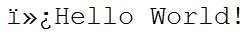
Very usual encode-mismatch: write with Utf8, then read with Ansi - most of you will recognize the typical 3 leading chars - this is how Ansi tries to display the ByteOrderMarks of Utf8
| 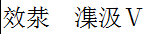
My favourite:
"Hello World", written with Ansi-encoding, and read with Utf16
|
In the "Windows-world", there is a very common technique to ship information about the applied encoding together with the file itself, called "ByteOrderMarking" (BOM):
The first 2, 3 or 4 bytes of the file are not meant to be readable chars, but to indicate the used encoding.
Unfortunately not every encoding has a BOM defined. But the most important encodings do so, namely Utf8, Utf16, Utf32. In the "Windows-world" there is one more "most important" encoding: Ansi - its Webname: "Windows-1252". For instance, Visual Studio saves its files with Ansi. And Ansi has no BOM defined. :(
So an unsafe, heuristic way to guess the encoding is to check for BOM, and if there is none, assume Encoding.Ansi. I admit: This is "quick and dirty at its best" - and I only recommend this approach in cases where you can strongly expect files to be written in one of the common Encodings.
(To learn about a real sophisticated way of guessing the encoding directly from the raw Bytes, refer to [^] Carsten Zeumers article).
How Not To Do It
using(var r = new StreamReader(filename)) {
richtextBox1.Text = r.ReadToEnd();
}
Although StreamReader is smart enough to detect BOMs by default, this will cause 2 disadvantages:
- If no BOM is detected,
StreamReader guesses Utf8 by default. IMO a suboptimal choice, since Utf8 can be detected. As I said, in cases of BOM-absence, better assume Encoding.Ansi. - The detected/guessed Encoding gets lost. Now when you save the file,
StreamWriter will choose by default Utf8, so your file-encoding may become changed, but you haven't noticed.
How To Do
Tell StreamReader to guess Encoding.Ansi by default, and store the detected/guessed encoding, to re-use it when writing the file. So the file-encoding will be left as it was before.
private Encoding _Detected;
using(var r = new StreamReader(filename, Encoding.Default)) {
richtextBox1.Text = r.ReadToEnd();
_Detected = r.CurrentEncoding;
}
File.WriteAllText(filename, richtextBox1.Text, _Detected);
Caution! Because the BOM is checked while reading, StreamReader.CurrentEncoding only is meaningful after minimum one Char was tried to be read.
About Foot-traps
May be the main foot-trap is the suboptimal documentation of StreamReaders smartness. Checking out StreamReaders-constructor in Objectbrowser:
public StreamReader(string path, System.Text.Encoding encoding)
Member of System.IO.StreamReader
Summary: Initializes a new instance of the StreamReader class for the specified file name, with the specified character encoding.
Would you now expect, that byte order mark detection is enabled, and the specified encoding may be ignored?
In a way, the summary lies to us: Yes, it instantiates a StreamReader with the given encoding, but it will not use it, in case of detecting a BOM.
To get a more correct description, you must refer to the [^] online-MSDN, since your offline-MSDN may be not up to date. (For instance: on my system, the following hint is missing):
Remarks
This constructor initializes the encoding as specified by the encoding parameter, and the internal buffer to the default size. The StreamReader object attempts to detect the encoding by looking at the first three bytes of the stream. It automatically recognizes UTF-8, little-endian Unicode, and big-endian Unicode text if the file starts with the appropriate byte order marks. Otherwise, the user-provided encoding is used. See the Encoding.GetPreamble method for more information.
Encodings in XML/HTML
For XML, there is a simple and common standard about the used encoding: It should be specified in the document definition tag, for example:
="1.0"="utf-8"
<root>
<value1>hällö</value1>
</root>
.NET-XmlReader, XmlDocument and XDocument handle such data properly, so if the encoding is specified, you can rely on that the data is read correct.
It's difficult, but still possible to save XML with one encoding, and specify a wrong encoding in the definition-tag, but that's not yours, but the responsibility of the XML author.
The Sample-app
I just built a little thing, with that you can read and write files with different encodings. You can detect encodings, change them, and reproduce mismatches.
History
- 7/15/2010: First post
- 8/15/2010: Add section "Encodings in XML/HTML", added corresponding code to sample-app

