Introduction
This is a distributed(grid) file search, find duplicates, full text index, using HTTP/TCP connections, very high speed using multi-threading, automatically detect physical harddisks and accelerate with NTFS USN Journal, and customized serialization caching hash and full text.
Many features will be coming very soon... this application IS a SERIOUS project, and it's rapidly improving, one big feature every few days.
Current Features
- Distributed: Search on a different computer through internet via HTTP or TCP
- Safe Access: Built-in RBAC
- Fast: Multi-thread concurrent grid computing
- Efficient: Compressed hash, full text index with local serialization storage and compressed network transfer
- Intelligent:
- Detect different physical harddisks (NOT partition) and automatically accelerate by parallel computing
- Detect NTFS and automatically use USN Journal to gain 10x faster file search
- Extensible: Support different full text index interface
Background
File search is a very old topic. It seems like I am reinventing the wheel, but finally I assure you that I am not.
At the very beginning, I just want to find one application to search my 3TB hard disks to quickly find duplicate files. There are quite a few commercial products out there which are really good, but hey, I talked to myself, why not make one yourself, simply to improve your skills while you make your own. And it ends up with this serious application.
Theory
To find duplicate files, you would need to decide the duplicate condition, whether by file name, size, content, etc. Normally, we use MD5 to get the hash value of a file to ensure two files are exactly the same, although MD5 has been proved to be not safe recently. However, you can choose SHA1 to do the hash, it's all up to you.
After getting the key (file name/size/content hash, etc.), we put it in a Dictionary, thus we can easily tell what are the duplicate files.
Code History
There have been 6 versions of my application:
- I simply hash all files, it works, but very slow, because it iterates all disk files content, imagine a 3TB hard disk full of files.
- Then I change to use file name/size/modified date, etc. to get the duplicates first. If it does not have the same size, it wouldn't be identical, right?
- But I am still not satisfied with the speed. Nowadays, most of the CPUs have multi-cores, we should exploit the power of multi-cores by using multi-threading.
- After several tests, the multi-thread works for file info search (
Directory.GetFiles), but not for file content reading(hash), so I only use multi-threading in file info search. - But I am still not satisfied with the speed.:) I figured out that I could dynamically identify whether the files are located in different physical hard disks (NOT different partitions within the same hard disk), if so, we can still use multi-threading to accelerate the speed. I found that I could use fast customized serialization to store the hash values, and every time I do the hash of a file, I first look up the serialization storage, if there is one match, I just use it, without doing the slow hashing.
- Ok, now the speed is not bad. But it is not so useful, since you only do the search within your computer. I came up with a thought that I could implement a distributed file search, using HTTP/TCP to communicate. And finally, here we are. :)
Using the Code
It's very simple to use the code.
Local Search for Exact Same Files
string duplicateFolder = @"d:\backup";
Dictionary<string, MatchFileItem> result;
BaseWork worker = new WorkV6();
result = worker.Find(new FileURI[]
{ new FileURI(@"c:\download\"), new FileURI(duplicateFolder)}
, new string[] { }, "", SearchTypes.Size | SearchTypes.Name, MatchTypes.ContentSame);
List<string> duplicatedFiles = worker.FindAll(result, duplicateFolder);
Distributed Search for Files that Contain a String (full text)
First, we need to initialize something:
WorkUtils.Initialize(new KeyValuePair<string, string>()
, CompressionMethods.GZip
, null, true, true, 5
, null, null, null);
Server
BaseManager manager = new WorkV6HTTPManager();
Role role = new Role("user");
role.AddFilePath(@"c:\temp\New Folder");
role.AddUser(new UserAuth("user", "pass"));
role.AddRight(UserRights.Discover);
role.AddRight(UserRights.Search);
role.AddRight(UserRights.Delete);
manager.Roles.AddRole(role);
manager.Progress += new EventHandler<ProgressEventArgs>(OnWorkProgress);
manager.Request += new EventHandler<DataTransferEventArgs>(OnManagerRequest);
manager.Start(8880);
Client
FileURI remoteFolder = new FileURI(@"202.2.3.4:8880/e:\temp\New Folder",
"user", "pass", 0
, ObjectTypes.RemoteURI);
Dictionary<string, MatchFileItem> result;
result = Worker.Find(new FileURI[] { new FileURI(@"c:\download\"), remoteFolder }
, new string[] { }, "YOUR KEYWORD HERE"
, SearchTypes.Size
, MatchTypes.ContentExtract);
List<string> matchFiles = Worker.FindAll(result, string.Empty);
Mechanism
Looks pretty easy, eh? But the underlining mechanism is really complicated. First, look at the workflow:
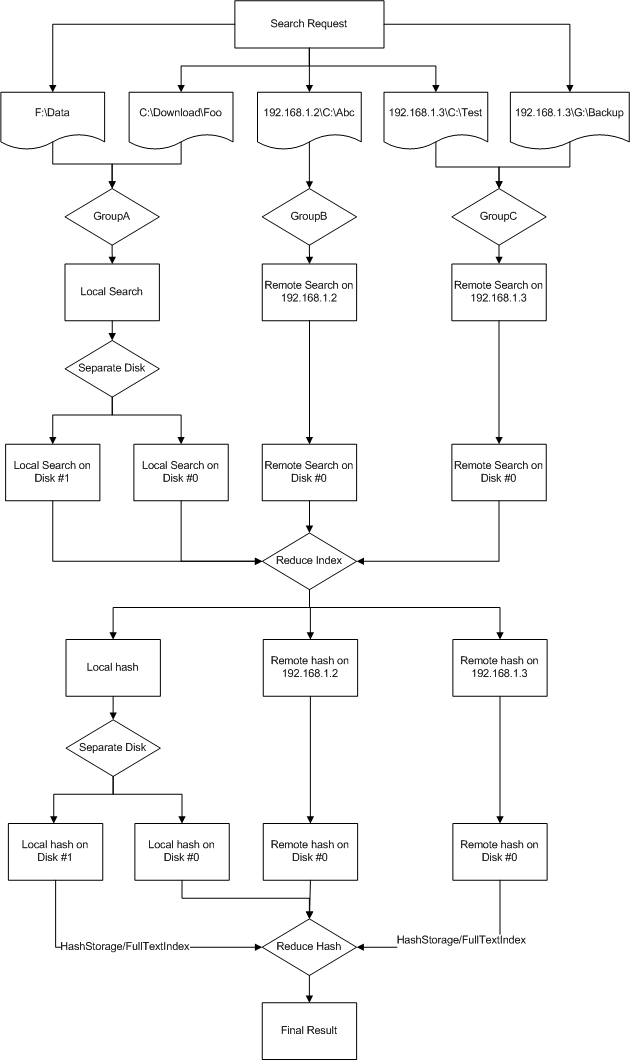
As you can see, the whole search task consists of two big steps: the file info search against file name/size etc., after that, we find these files that have the same content.
For the distributed search, it's more complicated. The first step is to return all the file info from remote computers, because you cannot tell what files are the same before you join the results.
Fast
The whole application aims at fast. It uses different kinds of techniques to gain the performance.
- Hash: I first use file name/size to filter the files, then I use customized serialization which was found here and improved to cache the hash values.
- File info search: Implement NTFS USN Journal which was found here to get the file names extremely fast without recursively going through folders by folders, and automatically detect different physical hard disks then use multi-threading.
- Compression: Implement compression for full text content and network transfer.
- Parallel processing: which is found here.
More than Duplicate Search
It can search for duplicate files, but also search for file names only, or even file content(contains or full text).
Tech Details
File Search
Info Search
Normally, we use Directory.GetDirectories() with SearchOption.AllDirectories option to get all the files within a folder recursively, but you will need to wait for quite a long time if the folder contains a huge amount of files, for example, the Program Files folder. I do the recursive search by myself, so that I can get control of the process, and add event logic to reduce CPU throttle. And within every folder, I use file names, size, modified date, etc. to do the collision according to the SearchTypes option. Please refer to WorkV6FindFileRunner.FindLocal for details.
NTFS USN Journal
About the NTFS USN Journal, you can look at this article: NTFS's Master File Table and USN. Basically, NTFS is a journaling file system, it keep track of the change of the whole file activities, like add/delete/modify, etc. I first detect whether the user wants to search the whole partition, then identifies if it's a NTFS format, the USN Journal will take into effect. It first look up the local NTFS storage using customized serialization, if there is no match(first time), then it will read the MTF(main file table) directly, without recursively searching the files folder by folder, thus it IS FAST, LIGHTENING FAST! Next time for the same request, it will read the local storage, and find the changes of last time snapshot. Please refer to LocalNTFSStorage for details.
Hash
After filtering with SearchTypes, I use MD5CryptoServiceProvider then get the hash value. You can choose to use SHA1CryptoServiceProvider if you do not trust MD5. Please refer to WorkUtils.HashMD5File for details.
The hash values are stored within a customized serialization file. Before really hashing a file, the application will look up the storage for a file that has the same SearchTypes. If there is a match, then it will use the stored value, otherwise, it will calculate the hash and store it to the serialization file. Please refer to LocalHashStorage for details.
File Compare/Match
There are four methods of file comparison: file name, content exact same, content contains and content extract(full text).
Parallel Processing
Right now, I use C# with .NET 2.0, so I do not have Parallel Processing Library shipped with .NET 4.0, but I use simulated code which is found here. The mechanism is to use ThreadPool.QueueUserWorkItem to run every task with ManualResetEvent to control the state of every task, and use WaitHandle.WaitAll to wait for every task to finish. Please refer to ParallelProcessor.ExecuteParallel for details.
Thread Safe
It's a frequently asked question/problem within multi-threading world. Within .NET 2.0, you will need to do the lock for the Dictionary. Right now, I am using SynchronizedDictionary found here. Of course, we can still use the boxing HashTable with HashTable.Synchronized(YourHashTable). If you are using .NET 4.0, you can use ConcurrentDictionary.
Besides the dictionary, you will need to pay attention to the locking of all the file streams.
Task Split
The most important thing in distributed computing is to split the tasks into small pieces and ask different computer/thread to do each task. Firstly, we split the folders into several task groups, then separate tasks according to remote/local folders. Please refer to WorkV6FindFileRunner for details.
After all the file info search tasks are finished, it reduces the result and splits the tasks again to do file comparison according to the MatchTypes. For a local folder, it automatically identifies whether folders are located in different physical hard disks, then it will use multi-threading if so. Please refer to WorkV6FindResultRunner for details.
Distribution
This is the core of the whole application. The mechanism is to have a listener running at each computer waiting for remote commands.
Data Transfer
It does not use XML as the container, but rather uses customized binary buffer. and the content is compressed for performance requirement.
Protocols
Right now, it supports HTTP and TCP. The client will first try to connect via HTTP, then it falls back to TCP if it fails. Each request is done through asynchronous in order not to block the network.
- HTTP: Every request content is POST and compressed through
Request.GetRequestStream via WorkUtils.SendHTTPRequest. At the server side, a HTTPListener is waiting for each HTTPListenerRequest. For each HTTPListenerRequest, it calls ProcessRequest within BaseManager to process Request.InputStream. Please refer to WorkV6HTTPManager for details.
HTTPListener is quite special, you should use HTTPListener.IsSupported first because it only works on winxp sp2+. It is built on http.sys, and does not support SSL natively, but you can use HTTPCfg.exe which could be downloaded from MSDN.
- TCP: The client uses
AsynchronousClient to connect to the server, and the server uses AsynchronousSocketListener to wait for every request, and processes the request within Received event. Please refer to WorkV6TCPManager for details.
Provider Pattern
In version v1.70, Filio introduced provider pattern, now, it supports different kinds of protocols through BaseWorkProvider:
Before
ip:port /remoteaddress/remotefile
Now
protocol://ip:port/remoteaddress/remotefile
You can use your imagination to add support for many storages, for example:
c:\temp\abc.txt
\\lancomputer\temp\abc.txt
http://1.2.3.4:88/foo/abc.txt
tcp://1.2.3.4:55/foo/abc.txt
ftp://1.2.3.4:21/foo/abc.txt
pop3://1.2.3.4:101/foo/abc.txt
skydrive://foo/abc.txt
dropbox://foo/abc.txt
AmazonS3://foo/abc.txt
flicker://foo/abc.jpg
facebook://foo/abc.jpg
Points of Interest
I am crazy about open source and performance, and I have learned quite a lot through the development of this application. Because I take quite a few credits from the open source world, I decided to make the application open source at http://filio.codeplex.com/.
Known Issues
- The
IFilter does not work properly within multi-threading environment. - The NTFS USN Journal might cause the
ExcutionEngineException problem, and you cannot proceed.
To Do
- File upload, download and synchronization
- Support for Cloud storage like Microsoft Azure, Amazon s3 etc. using provider pattern for extension
- Port the code to .NET 4.0 utilizing the power of new features like PPL/Linq, etc.
History
- 2010-8-02: v1
- 2010-8-11: v2: Filio v1.70

