This article deals with the implementation and empirical testing of a method to achieve practical perfect hashing. The method was devised by G.V. Cormack, R.N.S. Horspool and M. Kaiserwerth, and was published in The Computer Journal (Vol. 28, No. 1, 1985, pp. 54-58). The paper can be downloaded from the web at http://comjnl.oxfordjournals.org. The code described in this article is a C# version of a Turbo Pascal program that I wrote in 1990 when I was teaching at the Computer Sciences Department of the University of Texas at Austin. The Pascal code is my solution to Programming Assignment 10.2 from my unpublished textbook Applied Algorithms and Data Structures.
The main goal of the implementation of the method was to determine in an empirical way to what extent its authors’ claims were justified. The following description highlights the major points of the paper and adds some practical information not provided by the authors, but the reader is urged to read the paper in order to be thoroughly familiar with the data structures, and the insertion and retrieval algorithms.
The algorithms described by Cormack, Horspool and Kaiserwerth use a family of hash functions denoted by
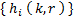
Where i is the index of a particular hash function, k is a numerical key, and r is a range (or interval) of consecutive elements in a data array. In mathematical terms, the ith hash function can be described as
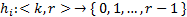 ,
,
That is, the hash function maps a tuple < k, r > into a unique number in the interval [ 0, r ). In the actual implementation, Cormack, Horspool and Kaiserwerth found that the general function
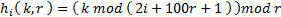
worked well if the implicit assumption k >> 2i + 100r +1 was satisfied. Observe that the index i of each hash function is an argument to the general function.
The elements of the Header Table (denoted by H) are triples < i, r, p >, where i is the index of a hash function, r is the size of a range of elements in the Data Table (denoted by D), and p is the index the first element of such a range in the Data Table. The size of the Header Table, S, must be a prime number. In general, the elements (or records) of the Data Table consist of a key field and additional data fields.
Both the insertion and retrieval algorithms depend on the conversion of a record’s key field into a numerical key k, which is used as the first argument to the hash functions. If the keys are alphanumeric strings, the first step in the implementation of these algorithms is to figure out a way to derive a large numerical value from the characters in a key. The simplest way to achieve this is to consider the characters as if they were “digits” in a positional number system (by using their ASCII codes as their numerical equivalents) and to multiply them by weights that yield reasonably-distributed “random” numbers having almost no common factors. For example, the weights could be prime numbers.
Assume that a function Int64 KeyToK( string key ) is available to compute the value of k that corresponds to an alphanumeric key, and that the family of hash functions is implemented by a function int H( int i, Int64 k, int r ). Once the alphanumeric key has been converted to a numerical key k, the value of k is used to compute indices x and y into tables H and D respectively as follows:
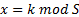
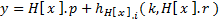
H[ x ] contains a reference to a Header Table element and D[ y ] contains a reference to a Data Table element. The dots in the formula to compute y correspond to the C# field-access operator, or just the dot operator. (Observe that the hash function (H) and the Header Table H are not the same thing.) Given these definitions, the insertion and retrieval algorithms can be described in pseudo-code in a little more precise fashion than the one provided by Cormack, Horspool and Kaiserwerth.
Insertion Algorithm
For the insertion of data records, it is assumed that each element of the Header Table H[ j ], for 0 ≤ j < S, was initialized with a reference to a triple < i, r, p >, where i = r = p = 0. In addition, each element of the Data Table must have been initialized as free, which is signaled by a NULL reference.
To insert the record < key, data >:
k = KeyToK( key );
x = k % S;
< i, r, p > = H[ x ];
if ( r == 0 ) {
y = index of any free element in D;
H[ x ] = reference to < 0, 1, y >;
D[ y ] = reference to < key, data >;
}
else {
< kj, dj > = D[ p + j ];
Find an m such that the r + 1 values
h( m, kj, r+1 ), 0 <= j < r,
and h( m, k, r+1 )
are all distinct;
y = index of the first r + 1 consecutive free slots in D;
H[ x ] = < m, r+1, y >;
D[ y + h( m, k, r+1 ) ] = reference to < key, data >;
for ( j = 0; j < r; ++j )
move < kj, dj > to D[ y + h( m, kj, r+1 ) ];
Mark the r elements D[ p ] ... D[ p + r – 1 ] as free;
}
Notes on the Insertion Algorithm
- The computation
x = k % S determines a group of records in the Data Table D.
All records whose keys hash to the same value of x are stored as a contiguous group in D.
The element referenced by H[ x ] contains the starting index for the group (p), the size of the group (r), and a parameter (i) to compute the second hash index.
A group may start at an arbitrary position in D.
- The hash function
H( i, k, r ) yields the offset of the desired record within the group.
As new records are inserted, groups grow in size.
When the size of a group increases, a new hash function H<sub>m</sub> must be found, and new storage in D must be found for the group. The details of this storage management are omitted from the algorithm. Groups could be shifted down to make space where is needed, which is a very expensive operation. Alternatively, it would be possible to use another area of memory to move the groups and use first-fit or best-fit memory management to keep track of them.
Retrieval Algorithm
k = KeyToK( akey );
x = k % S;
< i, r, p > = H[ x ];
if ( r == 0 )
there is no record with akey
else {
y = p + h( i, k, r );
< key, data > = D[ y ];
if ( key and akey are equal )
the record with akey has been found
else
there is no record with akey
}
Implementation in C#
As mentioned before, the C# implementation of practical perfect hashing was based on a Turbo Pascal program written in 1990. The Pascal program was implemented by means of a powerful strategy of synthesis, namely wishful thinking. This strategy has been amply demonstrated by Harold Abelson and Gerald Jay Sussman in their masterpiece Structure and Interpretation of Computer Programs (The MIT Press, 1985, p. 75; Second Edition, 1996, p. 84), and is equivalent to the programming technique known as top-down design: to solve a problem, start with a top-level function and decompose it into auxiliary functions (wishing they were available), each of them solving a single sub-problem. To finish the implementation repeat the process on each of those functions. I will describe the C# implementation as a console application following this pattern.
Constants and Fundamental Data Structures
To begin with, it is convenient to define some constants to be used throughout the code. They are defined as follows.
namespace PracticalPerfectHashing
{
public static class Constants
{
public static Int64
s = 1009,
n = 908;
public static Int16
thr = Int16.MaxValue;
public static int
maxL = 14,
avgL = 8,
fail = -1,
nPr = 6,
nPr_1 = 5;
}
}
The constants maxL and avgL are not strictly necessary because the C# code uses strings instead of the character arrays used in the Pascal code. I kept them to verify that both implementations produce the same results. The constants nPr and nPr_1 are related to an array of prime numbers, which are used as weights when converting an alphanumeric key to a numerical value k.
Next, it is necessary to define the data structures for the elements of the Header Table and of the Data table.
namespace PracticalPerfectHashing
{
public class HeaderElement
{
private int i, r, p;
public HeaderElement( int _i, int _r, int _p )
{
i = _i; r = _r; p = _p;
}
public HeaderElement( HeaderElement hdrElem )
{
i = hdrElem.I; r = hdrElem.R; p = hdrElem.P;
}
public int I { get { return i; } set { i = value; } }
public int R { get { return r; } set { r = value; } }
public int P { get { return p; } set { p = value; } }
}
}
namespace PracticalPerfectHashing
{
public class DataElement
{
private Int64 k;
private string key;
public DataElement( Int64 _k, string _key )
{
k = _k;
key = String.Copy( _key );
}
public Int64 K { get { return k; } }
public string Key { get { return key; } }
}
}
Hereafter, the class Program resides within the PracticalPerfectHashing namespace, and all the functions are methods of the Program class.
Class Program and Main Function
The class Program defines the global variables to be used: the Header Table, the Data Table, the array of prime numbers and some counters to report statistics. The top-level Main function drives the whole computation.
class Program
{
public static HeaderElement[] header;
public static DataElement[] data;
public static int[] prime;
public static int mMax, mSum,
wordSum,
collSum,
failSum,
nomvSum;
public static void Main( string[] args )
{
Initialize();
LoadTable();
ShowDataTable();
ReportStatistics();
TestRetrieve();
}
Function Initialize takes care of initializing the Header and Data tables, as described above, as well as the array of prime numbers and the counter variables.
private static void Initialize()
{
int i;
header = new HeaderElement[ Constants.s ];
for ( i = 0; i < Constants.s; ++i )
{
header[ i ] = new HeaderElement( 0, 0, 0 );
}
data = new DataElement[ Constants.n ];
for ( i = 0; i < Constants.n; ++i )
{
data[ i ] = null;
}
prime = new int[ Constants.nPr ];
prime[ 0 ] = 2; prime[ 1 ] = 3; prime[ 2 ] = 5;
prime[ 3 ] = 7; prime[ 4 ] = 11; prime[ 5 ] = 13;
mMax = mSum = wordSum = collSum = failSum = nomvSum = 0;
}
The definitions of functions ShowDataTable, ReportStatistics and TestRetrieve will be given at the end of this section. Function LoadTable reads words from a text file and, for each word, calls function Store, which implements the insertion algorithm. The words in the text file are assumed to occur one per line without repetitions.
private static void LoadTable()
{
string fName, key;
FileStream fs;
StreamReader sr;
int p;
Console.Write( "Input file? " );
try
{
fName = Console.ReadLine();
Console.WriteLine( fName );
fs = new FileStream( fName, FileMode.Open );
sr = new StreamReader( fs );
while ( !sr.EndOfStream )
{
key = sr.ReadLine();
++wordSum;
p = Store( key );
if ( p == Constants.fail )
{
Console.WriteLine(
String.Format( " Failure to store '{0} '\n", key ) );
++failSum;
}
}
sr.Close();
fs.Close();
}
catch ( Exception exc )
{
Console.WriteLine();
Console.WriteLine( exc.Message );
Console.WriteLine();
Console.WriteLine( exc.StackTrace );
}
}
Observe that function LoadTable uses a try-catch clause in order to report possible exceptions. If an exception occurs its message is reported, followed by a printout of the stack trace for debugging purposes.
Aside from the reporting code (calls to Console.WriteLine, and ReportCollision) function Store implements the insertion algorithm as described above. It relies on several auxiliary functions whose names reflect the description of the algorithm in pseudo-code: KeyToK, FindCfreeSlots, FindRp1distinctValues, the general hash function H, Install, and ResetDataPtr. The definition of function ShowData is given with the description of the functions dealing with the retrieval algorithm.
private static int Store( string key )
{
int x, y, m, j, offset;
HeaderElement irp;
Int64 k, kj;
k = KeyToK( key );
x = (int)( k % Constants.s );
irp = new HeaderElement( header[ x ] );
if ( irp.R == 0 )
{
y = FindCfreeSlots( 1 );
if ( y != Constants.fail )
{
header[ x ].P = y;
header[ x ].I = 0;
header[ x ].R = 1;
Install( k, key, ref data[ y ] );
ShowData( y );
return y;
}
else return Constants.fail;
}
else
{
ReportCollision( irp, k, key );
m = FindRp1distinctValues( irp.P, irp.R, k );
if ( m != Constants.fail )
{
mSum += m;
if ( m > mMax )
mMax = m;
y = FindCfreeSlots( irp.R + 1 );
if ( y != Constants.fail )
{
header[ x ].P = y;
header[ x ].I = m;
header[ x ].R = irp.R + 1;
offset = H( m, k, irp.R + 1 );
Console.WriteLine( "\ty = {0}, offset = {1}", y, offset );
Console.WriteLine(
String.Format( "\tinstalling {0} at y + off = {1}\n",
key, y + offset ) );
Install( k, key, ref data[ y + offset ] );
ShowData( y + offset );
for ( j = 0; j < irp.R; ++j )
{
if ( data[ irp.P + j ] != null )
{
kj = data[ irp.P + j ].K;
int index = y + H( m, kj, irp.R + 1 );
Console.WriteLine(
String.Format(
"\tresetting data from irp.P + j = {0} to index = {1}",
irp.P + j, index ) );
ResetDataPtr( index, irp.P + j );
}
}
Console.WriteLine();
return y + offset;
}
else return Constants.fail;
}
else return Constants.fail;
}
}
Function KeyToK implements the conversion of an alphanumeric key into a number (num) which corresponds to the numeric key k. It uses in a circular fashion the elements from the array of prime numbers as weights to be multiplied by the ASCII codes of successive characters from the key. If the length of the key is less than Constants.maxL, the function “pads” the sum using the ASCII code of a blank space as the weight. Finally, if the number calculated is less than Constants.thr (i.e., the number is too small) that constant is added to it (cf. the shifting of the value of k on page 54 of the original paper).
private static Int64 KeyToK( string key )
{
int i, j, l, md;
Int64 num;
l = key.Length;
if ( l <= Constants.avgL )
{
md = Constants.nPr;
}
else
{
md = Constants.nPr / 2;
}
j = 0;
num = 0;
for ( i = 0; i < l; ++i )
{
num = prime[ j ] * num + (int)( key[ i ] );
j = ( j + 1 ) % md;
}
for ( i = l; i < Constants.maxL; ++i )
{
num += prime[ j ] * ( (int)' ' );
j = ( j + 1 ) % md;
}
if ( num < Constants.thr )
{
num += Constants.thr;
}
return num;
}
The original pseudo-code description of the retrieval algorithm contains the line (broken into four lines above) “Find an m such that the r + 1 values h( m, k<sub>j</sub>, r+1 ), 0 <= j < r, and h( m, k, r+1 ) are all distinct”. Function FindRp1distinctValues is the implementation of such a line! This function relies on the implementation of singly-linked lists where insertions occur at the end. Instead of using the standard generic List class from C#, I used my own implementation of generic singly-linked lists (plus a couple of utility functions) because it offers some interesting operations. The generic singly-linked list class (Glist) is implemented in file Glist.cs and the utility functions are in file Util.cs. For brevity’s sake, I will not describe them.
private static int FindRp1distinctValues( int p, int r, Int64 k )
{
int c, j, v, rp1, m;
Int64 kj;
Glist<int> list;
bool eqKeys;
Console.WriteLine( String.Format( "\tFindRp1distinctValues == {0}", r + 1 ) );
eqKeys = false;
j = 0;
while ( j < r && !eqKeys )
{
if ( data[ p + j ] != null )
{
eqKeys = k == data[ p + j ].K;
}
++j;
}
if ( eqKeys )
{
Console.Write( "\n###" );
return Constants.fail;
}
else
{
c = 0;
m = 1;
list = new Glist<int>();
list.ToStringNodeItem = Util.IntToString;
list.EqualItems = Util.EqualInts;
rp1 = r + 1;
while ( m < Int16.MaxValue && c < rp1 )
{
for ( j = 0; j <= r - 1; ++j )
{
if ( data[ p + j ] != null )
{
kj = data[ p + j ].K;
v = H( m, kj, rp1 );
if ( list.InsertUnique( v ) )
{
++c;
}
else
{
c = 0;
}
}
}
if ( c == r )
{
v = H( m, k, rp1 );
if ( list.InsertUnique( v ) )
{
++c;
}
}
if ( c < rp1 )
{
c = 0;
++m;
list.Empty();
}
}
Console.WriteLine( String.Format( "\tm == {0}", m ) );
if ( c == rp1 )
{
list = null;
return m;
}
else
{
return Constants.fail;
}
}
}
Function FindCfreeSlots attempts to find c consecutive free (i.e., NULL) elements in the Data Table. If it finds them, it returns the starting index of the range; otherwise it returns failure.
private static int FindCfreeSlots( int c )
{
int i = 1, cc = 0;
while ( i <= Constants.n && cc < c )
{
if ( data[ i ] == null )
{
++cc;
}
else
{
cc = 0;
}
++i;
}
if ( cc == c )
{
return i - cc;
}
else
{
return Constants.fail;
}
}
Function H implements the general hash function as described in the original paper by Cormack, Horspool and Kaiserwerth.
private static int H( int i, Int64 k, int r )
{
Int64 a = 2 * i + 100 * r + 1;
return (int)( ( k % a ) ) % r;
}
Function Install simply creates a new DataElement instance somewhere in the Data Table. Observe that the element in the Data Table is passed by reference. (See the calls to this function.)
private static void Install( Int64 kVal, string iKey, ref DataElement dp )
{
dp = new DataElement( kVal, String.Copy( iKey ) );
}
Function ResetDataPtr “moves” an element of the Data Table from one index (source) to another (dest) and sets the source element to NULL. The movement is accomplished by changing a reference to a DataElement at the dest index. The function will not “move” to a non-NULL dest element nor from an element to itself.
private static void ResetDataPtr( int dest, int source )
{
if ( dest != source )
{
if ( data[ dest ] != null )
{
Console.WriteLine(
String.Format( "\tcannot move data[ {0} ] ({1}) to data[ {2} ] ({3})",
source, data[ source ].Key, dest, data[ dest ].Key ) );
++nomvSum;
}
else
{
Console.WriteLine( String.Format( "\t{0,14} moved from {1,3} to {2,3}",
data[ source ].Key, source, dest ) );
data[ dest ] = data[ source ];
data[ source ] = null;
}
}
else
{
Console.WriteLine(
String.Format( "\tmoving data[ {0} ] ({1}) into itself would make it null",
source, data[ source ].Key ) );
}
}
Function ReportCollision simply displays information about a collision. When a collision occurs, the insertion algorithm attempts to resolve it (see function Store above).
private static void ReportCollision( HeaderElement irp, Int64 k, string key )
{
Console.WriteLine( "collision:" );
Console.WriteLine(
String.Format( "\t<i, r, p> = <{0,3}, {1,3}, {2,3}> : {3,10} == {4}",
irp.I, irp.R, irp.P, k, key ) );
++collSum;
}
Functions ShowDataTable and ReportStatistics display, respectively, the non-NULL elements of the Data Table, and the values of the global counter variables.
private static void ShowDataTable()
{
int wCount = 0;
Console.WriteLine( "\n\nData Table:\n(entries not listed are null)\n\n" );
for ( int i = 0; i < Constants.n; ++i )
{
if ( data[ i ] != null )
{
Console.WriteLine( String.Format( "{0,4}: {1,20}", i, data[ i ].Key ) );
++wCount;
}
}
Console.WriteLine( String.Format( "\n{0} data items stored\n\n", wCount ) );
}
private static void ReportStatistics()
{
float avgM;
if ( collSum > 0 )
{
Console.WriteLine( String.Format( "\n{0} words read", wordSum ) );
Console.WriteLine( String.Format( "{0} collisions", collSum ) );
if ( failSum > 0 )
{
Console.WriteLine( String.Format( "{0} failures", failSum ) );
}
if ( nomvSum > 0 )
{
Console.WriteLine( String.Format( "{0} failed moves\n\n", nomvSum ) );
}
Console.WriteLine( String.Format( "\nMaximum 'm' == {0}", mMax ) );
avgM = ( (float)mSum ) / ( (float)collSum );
Console.WriteLine( String.Format( "Average 'm' == {0:######.###}\n", avgM ) );
}
}
After all the words from the input file have been processed, function TestRetrieve continuously prompts the user for search keys. For each key, this function calls function Retrieve, which is a straightforward implementation of the retrieval algorithm. If the key is found, function ShowData is called to display it.
private static void TestRetrieve()
{
string key;
int p;
bool go;
Console.WriteLine();
do
{
Console.Write( "Search key? " );
key = Console.ReadLine();
if ( ( go = !String.IsNullOrWhiteSpace( key ) ) )
{
p = Retrieve( key );
if ( p == Constants.fail )
{
Console.WriteLine(
String.Format( "\tThe key '{0}' does not exist", key ) );
}
else
{
Console.Write( "\t" ); ShowData( p );
}
}
} while ( go );
}
private static void ShowData( int i )
{
if ( data[ i ] == null )
{
Console.WriteLine( String.Format( "data[ {0,5} ] == null", i ) );
}
else
{
Console.WriteLine( String.Format( "data[ {0,4} ]:{1,10} == {2}",
i, data[ i ].K, data[ i ].Key ) );
}
}
private static int Retrieve( string key )
{
int x, y;
Int64 k;
k = KeyToK( key );
x = (int)( k % Constants.s );
if ( header[ x ].R == 0 )
{
return Constants.fail;
}
else
{
y = header[ x ].P + H( header[ x ].I, k, header[ x ].R );
if ( String.Equals( key, data[ y ].Key ) )
{
return y;
}
else
{
return Constants.fail;
}
}
}
Testing of the Insertion and Retrieval Algorithms
To test the insertion and retrieval algorithms I used two text files, maya0.wr and maya1.wr, which contain Chontal Maya words (one word per line without repetitions). These are the files I used to test the original Turbo Pascal code. When tested with these files, the C# code produced exactly the same results that the Pascal code produced. The files are in the bin\Debug subdirectory of the C# project in PPH_C#.zip, and they should remain there when the C# program is run as a console application. The program must be built and run under Visual Studio 2010.
As can be verified by running the C# program either from the Visual Studio 2010 IDE or from a stand-alone command prompt in the bin\debug subdirectory, the output is rather long, and I will not show it here in its entirety. The following are excerpts from the output at interesting points.
Output up to the point of the second collision
Input file? maya0.wr
data[ 1 ]: 2384129 == tichel
data[ 2 ]: 13818855 == paxbolon
data[ 3 ]: 4272418 == chontal
data[ 4 ]: 51719 == uhal
data[ 5 ]: 14418088 == xachilci
data[ 6 ]: 50167 == hain
data[ 7 ]: 49563 == bane
data[ 8 ]: 35851 == ya
data[ 9 ]: 2458317 == uthani
data[ 10 ]: 163489 == ahlec
data[ 11 ]: 52065 == tuba
data[ 12 ]: 49622 == caha
data[ 13 ]: 2408818 == ukatan
data[ 14 ]: 4466689 == hochlec
data[ 15 ]: 35836 == ta
data[ 16 ]: 37486 == hun
data[ 17 ]: 4746122 == uchelen
data[ 18 ]: 190713 == tupam
data[ 19 ]: 2373215 == uchame
data[ 20 ]: 2466159 == utohal
data[ 21 ]: 51616 == than
data[ 22 ]: 165325 == cheix
data[ 23 ]: 185781 == uhahi
data[ 24 ]: 2257706 == nadzon
data[ 25 ]: 35847 == ui
data[ 26 ]: 35844 == ti
data[ 27 ]: 37305 == cah
data[ 28 ]: 4807506 == tixchel
data[ 29 ]: 51799 == xach
data[ 30 ]: 12394491 == acahoche
data[ 31 ]: 2234174 == dzibil
data[ 32 ]: 2280145 == mexico
data[ 33 ]: 3924939 == chamionihi
data[ 34 ]: 4452888 == unacahibal
data[ 35 ]: 52362 == ynay
data[ 36 ]: 35850 == vi
data[ 37 ]: 187071 == ukaua
data[ 38 ]: 14601319 == upayolel
data[ 39 ]: 2406242 == ukabal
data[ 40 ]: 4815944 == uillayl
data[ 41 ]: 5035468 == yucatan
data[ 42 ]: 35856 == tu
data[ 43 ]: 13378615 == lahunpel
data[ 44 ]: 2416070 == ukinil
data[ 45 ]: 35604 == u
data[ 46 ]: 2170893 == hainob
data[ 47 ]: 2476342 == yithoc
data[ 48 ]: 37333 == cha
data[ 49 ]: 14850963 == yithocob
data[ 50 ]: 50868 == naua
data[ 51 ]: 2407069 == quiuit
data[ 52 ]: 52198 == tuua
data[ 53 ]: 195706 == yucul
data[ 54 ]: 3884049 == canoahaula
data[ 55 ]: 2345182 == tacpam
data[ 56 ]: 49588 == cabi
data[ 57 ]: 162758 == cahai
data[ 58 ]: 50216 == ayan
data[ 59 ]: 37281 == abi
data[ 60 ]: 14588767 == upakibal
data[ 61 ]: 2207683 == uhatantel
data[ 62 ]: 65267358 == nucxibilbaob
data[ 63 ]: 51824 == ukal
data[ 64 ]: 37709 == yol
data[ 65 ]: 195499 == yubin
data[ 66 ]: 5073584 == yuuilan
data[ 67 ]: 2421484 == ybache
data[ 68 ]: 49630 == cahi
data[ 69 ]: 51443 == tali
data[ 70 ]: 2417997 == umamob
data[ 71 ]: 2433441 == upapob
data[ 72 ]: 11638355 == ahauonihobi
data[ 73 ]: 2512145 == uchecte?i
data[ 74 ]: 14742813 == uthaniob
data[ 75 ]: 186862 == ukaba
data[ 76 ]: 1956654 == chacbalam
data[ 77 ]: 2463834 == tutzin
data[ 78 ]: 2122400 == analay
data[ 79 ]: 4356814 == auxaual
data[ 80 ]: 135379228 == cu?umil
data[ 81 ]: 2375949 == uchuci
data[ 82 ]: 162387 == cabil
data[ 83 ]: 162443 == cabob
data[ 84 ]: 37632 == vij
data[ 85 ]: 50729 == hoti
data[ 86 ]: 188824 == umole
data[ 87 ]: 14129506 == tanodzic
data[ 88 ]: 14641431 == unucalob
collision:
<i, r, p> = < 0, 1, 19> : 2274333 == huncha
FindRp1distinctValues == 2
m == 1
y = 89, offset = 0
installing huncha at y + off = 89
data[ 89 ]: 2274333 == huncha
resetting data from irp.P + j = 19 to index = 90
uchame moved from 19 to 90
data[ 19 ]: 179153 == paxoc
data[ 91 ]: 4369774 == uchantulib
collision:
<i, r, p> = < 0, 1, 37> : 4610527 == paxmulu
FindRp1distinctValues == 2
m == 6
y = 92, offset = 0
installing paxmulu at y + off = 92
data[ 92 ]: 4610527 == paxmulu
resetting data from irp.P + j = 37 to index = 93
ukaua moved from 37 to 93
data[ 37 ]: 2170837 == hainix
data[ 94 ]: 2466903 == utolob
data[ 95 ]: 14461822 == ulachuci
data[ 96 ]: 37636 == yai
data[ 97 ]: 2248884 == tuchadzic
data[ 98 ]: 49628 == ahau
Output at the point where the program fails to insert a word
data[ 241 ]: 14760019 == uthuntel
data[ 252 ]: 2270713 == uuincilel
collision:
<i, r, p> = < 0, 1, 36> : 35850 == to
FindRp1distinctValues == 2
### Failure to store 'to'
data[ 253 ]: 35815 == ma
data[ 254 ]: 37641 == yan
collision:
<i, r, p> = < 0, 1, 108> : 2264290 == tuthanobi
FindRp1distinctValues == 2
m == 3
y = 255, offset = 0
installing tuthanobi at y + off = 255
Output at the end of the execution
868: paxhochacchan
869: tamal
870: hum
868 data items stored
871 words read
287 collisions
3 failures
Maximum 'm' == 38
Average 'm' == 2.895
As can be seen, of the 287 collisions that occurred 3 could not be resolved, yielding a failure rate of 3/287 = 0.0104 or 1%. Thus, the empirical test suggests that the practical perfect hashing algorithm of Cormack, Horspool and Kaiserwerth is very effective.
A few tests of the retrieval algorithm
Search key? data[ 32 ]: 2280145 == mexico
Search key? data[ 172 ]: 13818855 == paxbolon
Search key? The key 'foo' does not exist
Search key? The key 'bar' does not exist
Search key? data[ 41 ]: 5035468 == yucatan
Search key?
C# Project Files
The project files for the C# implementation of practical perfect hashing are in PPH_C#.zip. Extract it to a suitable subdirectory of the Visual Studio 2010 Projects directory and run the program as a console application.
Original Pascal Code
For historical reasons, and for the interested reader, I have included the original Pascal code that I wrote in 1990. The code and the sample test files are in PPH_PAS.zip. The code can be built into an executable using Free Pascal (FPC), a free Pascal compiler that can be obtained from the web (the installation program is fpc-2.6.4.i386-win32.exe). With the default installation, the source code PPH.PAS and the test files must be placed in the C:\FPC\2.6.4\i386-win32 directory. Upon building, PPH.exe will be in the same directory, and can be run from a command prompt.

