Introduction
Data Science is a growing field. According to CRISP DM model and other Data Mining models, we need to collect data before mining out knowledge and conduct predictive analysis. Data Collection can involve data scraping, which includes web scraping (HTML to Text), image to text and video to text conversion. When data is in text format, we usually use text mining techniques to mine out knowledge.
In this post, I am going to introduce you to web scraping. I developed Just Another Web Scraper (JAWS) to download webpage from URL, then extract text using regular expression or HTMLAgility Pack.
JAWS has features to extract text from HTML website using regular expression and HTMLAgility. I have included the source code for all the features. In this article, I am going to explain only the text extraction using Regular Expression and HtmlAgility.
References
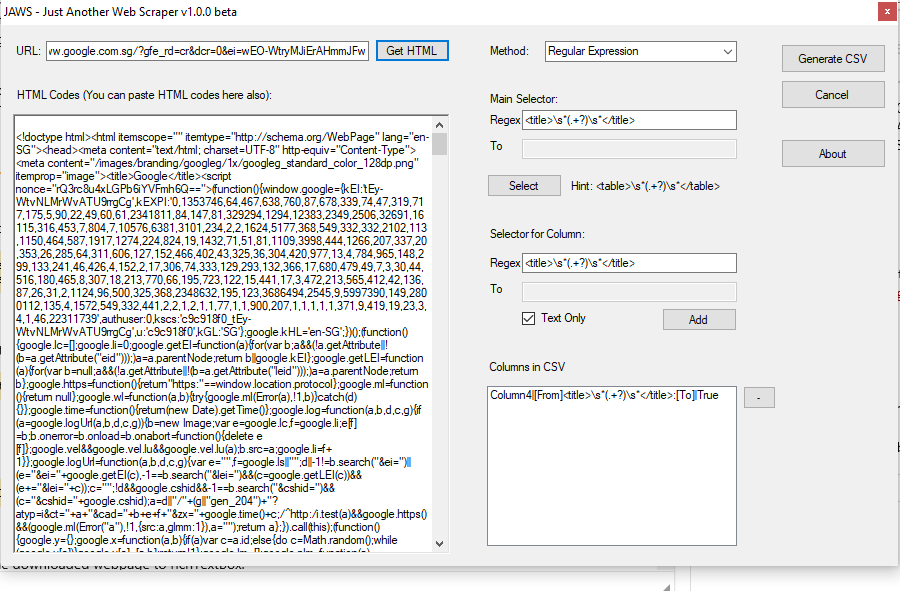
Downloading the Webpage
To download the webpage, we must include the System.Net and System.IO library:
using System.Net;
using System.IO;
Then create the WebClient object:
WebClient web = new WebClient();
We can then download the webpage to a temp file:
web.DownloadFile(url, Directory.GetCurrentDirectory() + "/temp.html");
To load the downloaded webpage to richTextBox:
StreamReader sr = new StreamReader(Directory.GetCurrentDirectory() + "/temp.html");
string line = sr.ReadLine(); int i = 0;
while(line != null) {
richTextBox1.Text += "\n" + line;
line = sr.ReadLine();
i++;
}
sr.Close();
Extracting Text using Regular Expression
To extract text using regular expression, include the following library:
using System.Text.RegularExpressions;
In order to search for text in the richTextBox1, using regular expression at regularExp variable:
MatchCollection matches = Regex.Matches(richTextBox1.Text, regularExp, RegexOptions.Singleline);
regularExp can have the values like "<title>\s*(.+?)\s*</title>"
Then display the results in richTextBox1:
foreach(Match m in matches) {
richTextBox1.Text += m.Value;
}
Extracting Text using HTMLAgility
To extract text using HtmlAgility, include the following library:
using HtmlAgilityPack;
Loading the HTML file into HtmlAgilityPack's HtmlDocument object:
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
doc.Load(Directory.GetCurrentDirectory() + "/temp.html");
Extracting data from HTML:
foreach (HtmlNode n in doc.DocumentNode.SelectNodes(mFromTextBox.Text)) {
richTextBox1.Text += n.InnerHtml;
}
mFromTextBox.Text contains XPath for extraction. mFromTextBox.Text value can be like "//body".

