Introduction
Finding duplicate files is becoming a great deal in case the folder holds large number of files of different file types. Programmers always prefer to do that easily without much complications. There is a possibility of exploring that with SQL Server FILESTREAM and FILETABLE. This tip holds a simple query and it is another easy way of identifying duplicate files with FILETABLE. This FILETABLE is created using FILESTREAM. When coming to the FILESTREAM, we cannot forget Jacob Sebastian, who gave us this extraordinary functionality. Now let's see how this extraordinary functionality allows us to find duplicate files.
Background
The queries in the download source contain the following:
- Enabling
FILESTREAM - Creating
FILESTREAM database - Creating
FILETABLE - Identifying duplicated files
Before getting into the detailed analysis, I will give you the brief explanation for a general question, which may arise in everyone's mind.
Why FILESTREAM and FILETABLE?
FILESTREAM helps us to store and manage unstructured data and this feature allows to store BLOB data (example: Word documents, image files, music and videos, etc.) in the NT file system. This NT file system allows SQL Server to take advantage of the NTFS I/O streaming capabilities and at the same time, maintaining transactional consistency of the data. There were two approaches before introducing FILESTREAM to the coding world; one is VARBINARY which gave us bad performance and another one is storing unstructured data in disk files which did not have transactional consistency of the data even though this approach gave good performance. The FILESTREAM solves both the issues of these two approaches of earlier days.
And this unstructured data is projected in a structured way and that is called FILETABLE.
Here query cycle through all duplicate files in a folder and its sub folders.
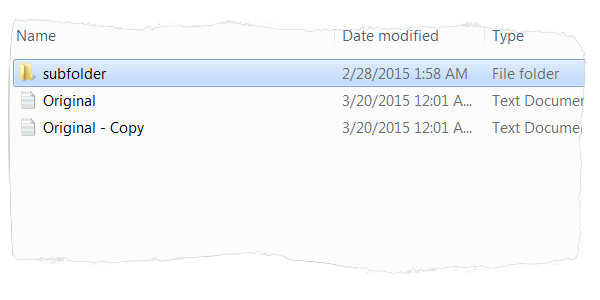
Using the Code
Identifying Duplicated Files
Here in the code below, I have used Common Table Expression (CTE) which is said as temporary table and it is always defined using 'WITH' clause. There may be more than one CTE in a Query. Here, I have used two CTE for identifying duplicate files in the folder.
The first CTE contains two built-in SQL ranking functions:
ROW_NUMBER is assigned as a unique increment sequence number. Numbers are arbitrarily assigned for rows that have duplicate values.
RANK is also assigned as a unique number. For rows that have duplicate values, the same value is assigned with the same number and there number sequence may skip (gap in between numbers) for each duplicate that arises in the table column.
With CTE
as
(
SELECT
ROW_NUMBER() over (order by [file_stream]) as File_Number
, RANK() over (order by [file_stream]) as Find_Dupe
,[name]
,[file_stream]
FROM [dbo].[FileTableTb]
)
, [unique_pull]
as(
SELECT MIN(File_Number) as Unique_File from CTE
group by Find_Dupe
)
SELECT CTE.name from CTE join [unique_pull]
on CTE.File_Number=unique_pull.Unique_File
The solution formula here is to pull the records where row number and rank is not equal and thus we find duplicate files. The MIN mathematical SQL function in second CTE is used to avoid getting repetitive file records in the result.
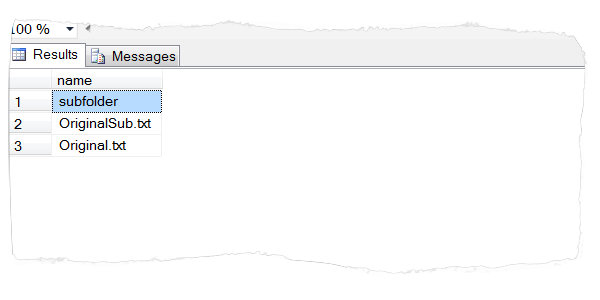
Here in the below result, the duplicate files are identified and the unique files and subfolders are shown in the list.
Points of Interest
Handling actual binary content of a wide range of file types had many complications and I have tried many applications but still those are not efficient. Usually, programmers recommend checking duplicate files carefully before deleting it completely. In such case, this Query would be helpful to finding duplicate files. Hope this post would be useful to all. I would be grateful if you can share your feedback. Thanks!

