Before
Before starting to read this article, please take into your account the following bullets:
- The main target of this part is to evaluate different methods of seaching over different type of data-structures and evaluation of different lanugages will be settle down in the next part.
- Windows is not a Real-Time Operating System (RTOS) so it has pretty non-deterministic job scheduling
- Microsoft has published the .NET source code in C# which allows you to read and understand the way that sophisticated data structures are implemented but still it is not so clear because of CLR`s architecture
- I strongly recommend that before starting to read this article first read about Common Language Runtime (CLR) and Just-In-Time Compiler (JIT).
- The results are not averaged or normalized and they gathered by one-time execution step.
- Time resolution is based on microsecond.
- Try to check-out source from git repository. I have tried to show some nice tricks like using native codes in VB and C# and settings of C++/CLI plus using unit-tests for whole projects and etc.
Introduction
Let's imagine you are working as a software engineer in a company that deals with a big data collection and you have to come up with the best platform, language and also data structure to give a good competition advantage to your company`s business.
The recent horizon of software developments has stressed out large scale run-time data processing and almost any application is suffering from large scale data processing complexity and overhead.
In this article, I will try to give a tentative answer for following important questions:
- Which language is the best one for your team, product, solutions that are/will involve in the whole system?
- Can data structure speed-up your algorithms?
To answer the above questions, you need to have a right estimation about your programming compiler and data structures.
Background
As a programmer, I always used to think about the performance of different data structures under different algorithms execution time and different data-types contents. It was always not so clear for me, to predict the behavior of defined data structure under different events and status over the developed program life cycle.
I believe that object oriented programming introduced very strong concepts to improve programming science but also added some conceptual complexities or even difficulties to understand the code. Like encapsulation which made up programmers blind about the detail of non-primitive data structures like the List, List<T>, Dictionary, etc. (Find more details about these data structures here).
For example, almost everyone who has touched any kind of advanced programming languages like C#.NET, VB.NET or Java, knows about different types of variables, arrays, dynamic lists, and dictionaries. But maybe just a few programmers know detailed implementation of those complex data structures. While having a solid knowledge about the details of each data structure can have a very strong influence on execution time, programmers used to just trust the framework and not take into account any data structure driven bottleneck.
Maybe others also like me used to program under the .NET Framework supported languages such as C#, VB or C++, and its data structures. But, personally, I never thought about the details of used data structures because of having a wrong trust to this black box which is not clear how it works. The rest of this article will explain the meaning of the wrong trust in more detailed.
Using the Code
To answer two above questions, I tried to have a tentative benchmarking over big data structures under .NET Framework by a simple methodology. The method is very simple, I just defined two different data structures (Dictionary and List) with 4 basic sizes 10.000, 100.000, 1.000.000 and 10.000.000. Then, I used a simple function to feel-up each data structure like the immediate code:
private static void FetchMockData(int length)
{
if(list.Count > 0)
length = Monitor.Length += Monitor.Length;
for (int i = list.Count; i < length; i++)
{
list.Add(mocklbl + i);
}
}
After that, I used the following methods to find an item. Note that this item is always the last item because of the worst case scenario.
- In
Dictionary:
Find ByGetValueFind ByKey
- In
List:
Find ByFindFind ByBinarySearchFind ByForFind ByEnumerator
[TestMethod]
[TestCategory("Owner [C'#' Dictionary]")]
public void FindByGetValueInDictionary()
{
string find = mocklbl + (dictionary.Count - 1);
Monitor.Start();
object found = dictionary.TryGetValue(find, out found);
Assert.AreEqual(true, found);
Monitor.Stop();
WrappedMonitor.Elapsed("FindByGetValueInDictionary");
}
[TestMethod]
[TestCategory("Owner [C'#' Dictionary]")]
public void FindByKeyInDictionary()
{
string find = mocklbl + (dictionary.Count - 2);
Monitor.Start();
object found = dictionary[find];
Assert.AreEqual(find, found);
Monitor.Stop();
WrappedMonitor.Elapsed("FindByKeyInDictionary");
}
[TestMethod]
[TestCategory("Owner [C'#' List]")]
public void FindByFindInList()
{
string find = mocklbl + (list.Count - 1);
Monitor.Start();
string found = list.Find(i => i == find);
Assert.AreEqual(find, found);
Monitor.Stop();
WrappedMonitor.Elapsed("FindByFindInList");
}
[TestMethod]
[TestCategory("Owner [C'#' List]")]
public void FindByBinarySearchInList()
{
string find = mocklbl + (list.Count - 1);
Monitor.Start();
int found = list.BinarySearch(find);
Assert.AreEqual(list[found], find);
Monitor.Stop();
WrappedMonitor.Elapsed("FindByBinarySearchInList");
Monitor.Reset();
FetchMockData(Monitor.Length);
FindByBinarySearchInList();
}
[TestMethod]
[TestCategory("Owner [C'#' List]")]
public void FindByForInList()
{
string find = mocklbl + (list.Count - 1);
int length = list.Count;
Monitor.Start();
string found = "";
for (int i = 0; i < length; i++)
{
if (list[i] == find)
{
found = list[i];
break;
}
}
Assert.AreEqual(find, found);
Monitor.Stop();
WrappedMonitor.Elapsed("FindByForInList");
Monitor.Reset();
FetchMockData(Monitor.Length);
FindByForInList();
}
[TestMethod]
[TestCategory("Owner [C'#' List]")]
public void FindByEnumiratorInList()
{
string find = mocklbl + (list.Count - 1);
Monitor.Start();
IEnumerator iEunm = list.GetEnumerator();
string found = "";
while (iEunm.MoveNext())
{
if (iEunm.Current.Equals(find))
{
found = (string)iEunm.Current;
break;
}
}
Assert.AreEqual(find, found);
Monitor.Stop();
WrappedMonitor.Elapsed("FindByEnumiratorInList");
Monitor.Reset();
FetchMockData(Monitor.Length);
FindByEnumiratorInList();
}
Please note that this benchmarking is accomplished under Windows operating system which is not a deterministic operating system. That means if we run any of the above codes, we will have a different execution time. But, the overall results are pretty much enough to have a rough estimation.
For your information, I am going to write my machines specifications:
- CPU: Intel (R) Core (TM) i7-6650U @ 2.2GHz (4 CPUs), ~2.2GHz
- RAM: 8 GB
- O.S: Windows 10 Pro
Important Note: All implemented codes are compiled under CLR with no optimization enabled flag and no specific settings, and results are not average or normalized.
Points of Interest
Here, I would like to present the accomplished results without any survey or scrutiny as I will continue this article for more further parts and I will discuss details and reasons a lot. Note that time resolution is in microseconds which presented over axis X after one-time execution cycle.
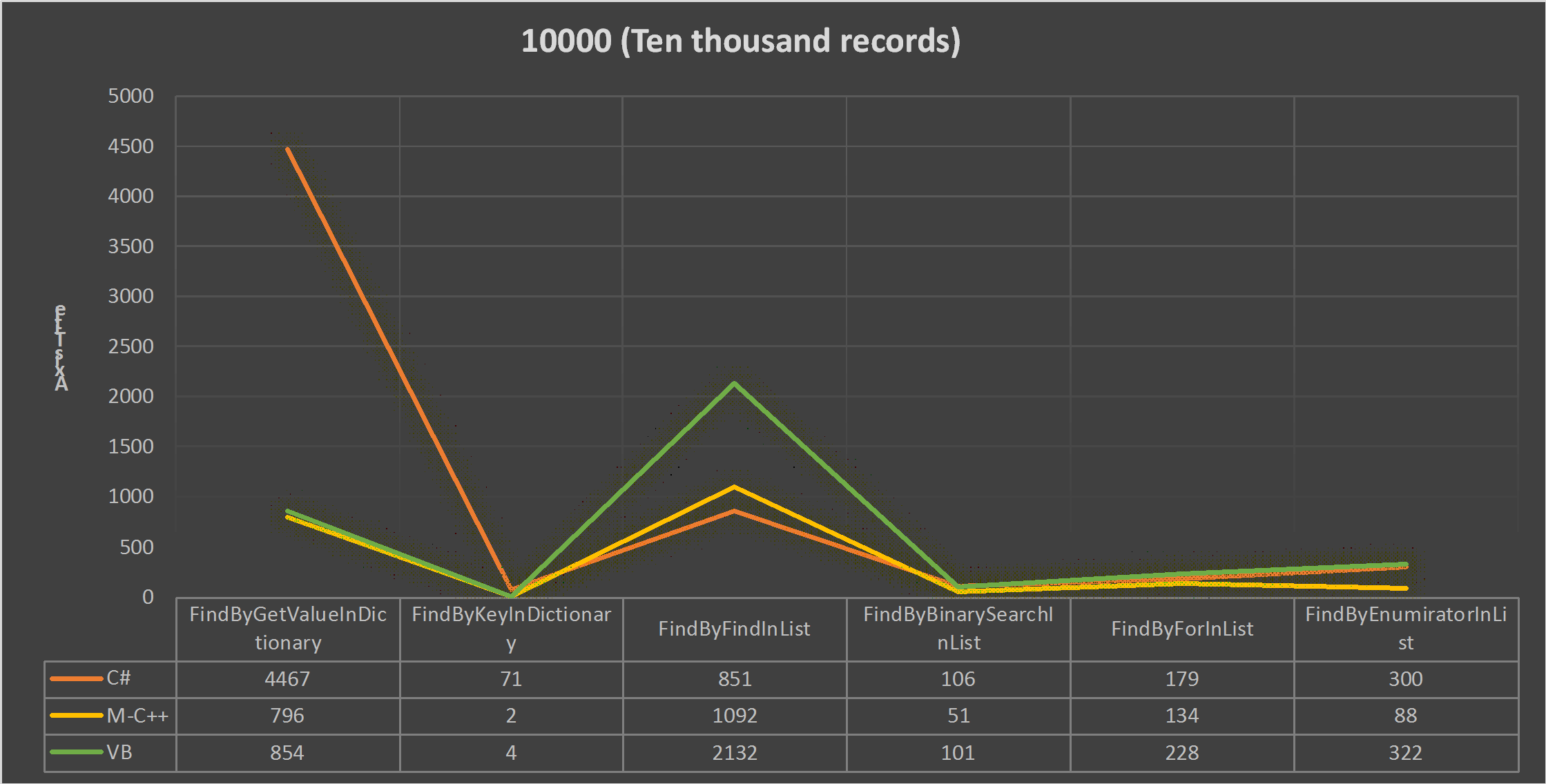
Figure 1: Results has been generated through execution over 10.000 records.

Figure 2: Results has been generated through execution over 100.000 records.
Figure 3: Results has been generated through execution over 1000.000 records.
Figure 4: Results has been generated through execution over 10.000.000 records.
Please keep your eyes open for further parts and cross your fingers that I will manage to find some time to write again.
To have access to the source code of the article, please use this link and kindly consider that project is under development and might have continued changes. I am also trying to add more languages and native codes to this results.
GitHub.
History
- 6th March, 2017: Initial version

