Introduction
CompilationCleaner is a dialog-based .NET app that searches for non-critical compiler and linker generated files, and displays them in its ListView for possible deletion. This is similar to various compilers' "clean" options, except that multiple paths can be searched, and you do not have to delete all the files found. This allows batch-deletion of compiler garbage, which developers normally do not delete as they repeatedly compile.
Gigabytes of thousands of files may be removed using CompilationCleaner, especially if you routinely compile dozens of projects as I do. My first use, after years of continuous compiling, deleted several GBs and thousands of files. Visual Studio generates more intermediate files than most compilers, so it can reclaim a lot of disk space.
Since CompilationCleaner is ultimately a generic file searcher that can test for file signatures, it can be used to find and/or delete any kind of file, such as GIFs, BMPs, databases, and so forth.
Safety first
Although CompilationCleaner was designed to be efficient in critical areas, safety is its primary concern. Simply searching for and deleting files with certain extensions, can be disastrous! Many projects (especially portable or Unix-oriented ones) contain files with inconsistent extensions. For example, the Unix world generally doesn't honour Windows file extensions.
CompilationCleaner checks each file's signature before even listing it, unless you explicitly specify a file pattern without an associated signature (strongly discouraged when avoidable). Almost all Visual Studio intermediates have a distinct signature.
About the code
CompilationCleaner is written in Managed and unmanaged C++. It began life a few years ago as an experiment in Managed C++, but was shelved until Visual Studio .NET 2003 made MC++ more doable. I did not originally intend to use any unmanaged C++, since this was supposed to be a quick-and-dirty utility (how often do we make that assumption?). But due to poor performance, critical file I/O has since been implemented in native code.
While the syntax is Managed C++, it will also compile in the upcoming Visual Studio 2005. The GUI code can be converted to C# or Visual Basic with text replace operations, but the file operations must remain in mixed Managed/unmanaged C++.
Note: A version was tested on VC++ 8 Beta, which compiled and ran, but the new CLR still had bugs in it.
Performance
Experience with both C# and MC++ file searching, exposed performance problems with the CLR file I/O. The likely culprit is the need to marshal good-sized chunks of data to and from managed code. As such, all file searching and signature verification is done via the Win32 API, in unmanaged and mixed C++ classes. With these changes, the speed increased several orders of magnitude, even with DEBUG builds.
The unmanaged code depends on the UNICODE macro, which improves speed and reduces code bloat. This should not be a problem since VS.NET doesn't even run on Win9x platforms, although you can compile a non-Unicode version for use on such systems, for non-VS.NET compilers (ANSI code is in place).
Since CompilationCleaner is foremost a developer utility, I'll explain how to use it before getting into the code. Furthermore, its usefulness is more important to most people than the code details, especially those who are unfamiliar with Managed or regular C++.
CompilationCleaner is simple to use, and is upto date with Visual Studio 2005 beta. By default, your project directory will be preloaded into the search path's ComboBox (if you have VS 8.0, 7.1, 7.0, or 6.0 installed). You can add or replace directories at any time, and they will be saved on app exit. The "Add Path" button is more convenient than a browse button, since it appends search paths, complete with semi-colon. To get typical browse behaviour, just delete the ComboBox text first.
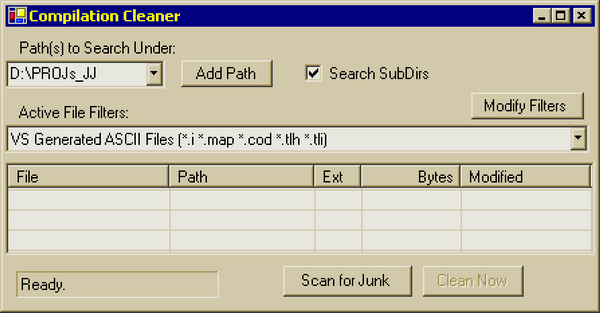
The "Active File Filters" ComboBox is used to select the collection of file filters to be used while scanning. You can add, remove, rename, or rearrange filters by clicking the "Modify Filters" button. That brings up this modal dialog:

The upper ListBox contains named filter collections, and the one below it lists the filter groups the currently selected collection contains. The "Add", "Remove", and "Rename" buttons are standard fare. There are mouse-over Tooltips for the TextBox and CheckBox labels, in case you forget how to use them. If this were a commercial product, I would have created an HTML help file too.
The most important fields are the "File Signature" and "File Matching Pattern(s)" TextBoxes. You must enter at least one valid file pattern, or multiple ones separated by spaces (in standard Windows fashion). CompilationCleaner tries to prevent you from specifying an invalid or empty pattern. If you do so, you will be prompted about the error, and will not be able to take any other actions before you correct the pattern, except "Cancel" or "Restore Defaults".
Currently, the file matching pattern rules are:
- Only ASCII characters.
- No illegal filename characters except *.
- Only one * wildcard may be used per pattern.
- Multiple patterns should be delimited by a space, comma, or tab character.
- A * by itself is not a valid pattern, since there can be no specific match.
Examples of valid patterns are:
*.bsc myfile.* std*.h input*
By far the most likely patterns are extensions, as in the image above.
File signature
Probably the most important feature is the ability to specify file signatures. When binary, these are sometimes known as magic numbers. One does not have to specify a signature, but searching for files by name or extension alone, may be unreliable.
Many Visual Studio generated files have ASCII signatures, such as "Microsoft C/C++" for .bsc files. Some compiler generated files have binary signatures, which must be specified in Hex. This is done by entering a Hex character pair for each byte (in array order), separated by one space, comma, or tab (as with file patterns). Hex characters can be any combination of upper- and lower-case. You must also check the "Signature is in Hex" CheckBox, which makes the text show in highlighted colour. For example:
You can determine a file's signature by opening several different instances of the same file type, preferably in a Hex editor. If a type of file has a signature, the initial bytes of all such files will be identical. If the bytes are readable, they are likely to be ASCII, otherwise you should copy the Hex pairs as shown in a Hex editor, and specify the signature as binary.
Deleting compiler junk
After you have selected the path(s) and a pattern collection, click "Scan for Junk" (or press ENTER) to initiate a scan. If you wish to stop an in-progress scan, click the same button again (it will be relabeled "Stop Scan" in red during a scan), or press ESCAPE. The results look something like this:
Initially, none of the entries are check marked, forcing you to choose which files to delete. The ListView has a right-click context menu that allows you to check/uncheck selected files, and other helpful features. You can also click the column headers for sorting.
Note: CLR v1.x ListViews automatically check a range selection (when using SHIFT), so beware of this.
In the image above, notice that I did not check any .pdb (Program DataBase) files, since I sometimes wish to keep those around for debugging purposes. Another signature-verified VS-generated file you might want to delete judiciously, is an .obj file, since sometimes we compile them for static library use. Everything else is expendable in the pictured filter collection.
When you have checked the files you wish to delete, click on "Clean Checked", and those files will be removed from the ListView and your hard disk(s). Deleted files are not placed in the Recycle Bin.
The code
CompilationCleaner's GUI interface is pure CLR, is mostly standard fare, and has only a couple of mentionable highlights. We'll cover that first, and later deal with the integration of native C++ file searching code.
General purpose ListView sorter
A noteworthy GUI class is LVSorter, in LvSorter.h, which sorts ListView columns both ascending and descending, for multiple types of data. It inherits from IComparer so that it can be assigned to a ListView::ListViewItemSorter property. It is used in the form's header-clicked handler:
void LV_ColumnClick(Object *pSender,
ColumnClickEventArgs *pColClickArgs) {
if (m_pLvSorter != NULL) {
m_pLvSorter->SetColumn(pColClickArgs->Column);
m_pLV->Sort();
}else{
m_pLvSorter =
__gc new LVSorter(pColClickArgs->Column);
m_pLV->ListViewItemSorter = m_pLvSorter;
}
}
You could just use the code in the else block, as MSDN documentation suggests, but I have an aversion to creating loads of sorter objects on the GC heap for no good reason. Besides, that means the last known sort order would not be preserved, so sort order wouldn't toggle so easily. MSDN suggests keeping a SortOrder data member around, but that means we'd need to keep track of the last sorted column too. I went for encapsulation instead, so that there's just one member object: m_pLvSorter.
Note that when you assign to the ListView::ListViewItemSorter property, ListView::Sort() is effectively called (in Win32 terms, LVM_SORTITEMSEX). If this property has already been set, the column must first be set using LVSorter::SetColumn(), so that ListView::Sort() will sort the correct column. Why the ListView designers decided not to pass the column index (ColumnClickEventArgs::Column) to the required Compare() method, I cannot fathom. If they instead specified inheriting from an interface that uses the column to sort, LVSorter would be much simpler, as are my MFC and WTL versions of LVSorter, which ironically are easier to use.
The class itself is implemented as:
#define dcast dynamic_cast //Bjarne Stroustrup intentionally
private __gc class LVSorter : public IComparer {
private:
int m_iCol;
SortOrder m_order;
public:
LVSorter() : m_iCol(-1),
m_order(SortOrder::Ascending) {}
LVSorter(int iColumn) : m_iCol(iColumn),
m_order(SortOrder::Ascending) {}
void SetColumn(int iColumn) {
if (iColumn != m_iCol)
m_order = SortOrder::Ascending;
else
m_order = (SortOrder)((int)m_order ^ 3);
m_iCol = iColumn;
}
int Compare(Object* pA, Object* pB) {
typedef System::Windows::Forms::
ListViewItem::ListViewSubItem LvSubItemT;
LvSubItemT *pSubA =
(dcast<ListViewItem*>(pA))->SubItems->Item[m_iCol];
LvSubItemT *pSubB =
(dcast<ListViewItem*>(pB))->SubItems->Item[m_iCol];
int iRet;
switch (m_iCol) {
case 0:
case 1:
case 2:
String_Comparison:
iRet = String::Compare(pSubA->Text, pSubB->Text);
break;
case 3:
iRet = (int)(Int64::Parse(pSubA->Text, NumberStyles::Number) -
Int64::Parse(pSubB->Text, NumberStyles::Number));
break;
case 4:
try {
iRet = DateTime::Compare(DateTime::Parse(pSubA->Text),
DateTime::Parse(pSubB->Text));
}catch (...) {
goto String_Comparison;
}
break;
default:
Debug::Assert(0,
S"Need to implement sorting on all columns");
goto String_Comparison;
}
if (m_order == SortOrder::Descending)
iRet = -iRet;
return iRet;
}
};
Note that the default constructor should not be used, but it exists because .NET requires it.
SetColumn() exists because the column index is not passed to the required Compare() method. When a different column is clicked on, the sort order is set to ascending. When the same column is clicked consecutively, the order toggles, which is a standard Windows behaviour. Note that drawing an arrow image onto ListView headers is even more trouble than usual with the CLR, so I didn't bother.
Compare() is passed generic object pointers, which again I cannot fathom. There is no other possible type except ListViewItem that can be passed, so this loosely-typed implementation requires dynamically casting to the actual type (even in C#). As you can tell, I am not at all happy about generic types, so I can't wait for VS 2005 to come out of beta (although the ListView interface has not changed). This method exactly mirrors virtually every other Compare() method in the CLR, but I can't think of any good reason why; it's user-unfriendly.
The CLR date parsing is a bit of a kludge, and thus date sorting is not very fast, but livable. If this were a commercial product, I'd assign an Int64 of the FILETIME value to each item's Tag property, which would allow much faster code for time sorting:
try {
Int64 iA = *reinterpret_cast<Int64*>(
(dcast<ListViewItem*>(pA))->Tag);
Int64 iB = *reinterpret_cast<Int64*>(
(dcast<ListViewItem*>(pA))->Tag);
const Int64 i64diff = (iA - iB);
iRet = (i64diff > 0) ? 1 : (i64diff < 0) ?
-1 : 0;
}catch (...) {
goto String_Comparison;
}
But the existing parsing code is adequate for this project.
A nicer message box
NiceMsgBox.h contains a convenience wrapper I've been using for years now. Class NiceMsgBox::MsgBox contains static methods to avoid verbose coding, like:
DialogResult dr = MessageBox::Show(this,
S"Question text", S"Dialog Caption",
MessageBoxButtons::YesNo,
MessageBoxIcon::Question,
MessageBoxDefaultButton::Button2);
And instead allows:
DialogResult dr = MsgBox::Question(this,
S"Question text", S"Dialog Caption",
Btn::YesNo, Default::Btn2);
And the simplest of all:
MsgBox::Info(this, S"message");
I prefer simpler and terser code, as long as it doesn't sacrifice readability. The code itself is very simple, and not worth covering beyond explaining the calls, which you will see in much of the project's code. I use a similar class for C#.
The managed public class MFindFilesByPatternAndSig, in GatherFilenames.h, provides the CLR interface for file searching, and can be used with any CLR application. It contains not only CLR marshalling code, but also the Win32 file finding code, which is why CompilationCleaner is not painfully slow, and in fact is surprisingly fast (now limited primarily by the CLR ListView). The Win32 code for enumerating files and directories is standard fare, with a modest focus on efficiency rather than politically-correct coding fashion. As such, I won't cover the methods in detail here.
The straight C++ class, _CFilePatternMatcher, encapsulates Win32 code for matching files, and is used exclusively by MFindFilesByPatternAndSig. Since both classes interoperate, here are both declarations together for easier reading:
typedef ::std::basic_string<TCHAR> StrT;
typedef ::std::basic_string<BYTE> ByteStrT;
typedef ::std::vector<StrT> StrVecT;
__nogc class _CFilePatternMatcher {
enum EPatternFlags {
k3LtrExt = 1,
kEndsWith = 2,
kStartsWith = 4,
kWholeMatch = 8,
};
#ifdef UNICODE
typedef UINT64 _FourChrUInt;
typedef wchar_t UnsignedChrT;
#else
typedef UINT32 _FourChrUInt;
typedef BYTE UnsignedChrT;
#endif
public:
typedef ::std::vector<ByteStrT> ByteStrVecT;
struct Pattern {
size_t uFlags;
StrT sPrefix;
StrT sSuffix;
size_t uSigID;
size_t uSigIdx;
};
typedef ::std::vector<Pattern> PattVecT;
PattVecT m_vPatts;
ByteStrVecT m_vSigs;
public:
_CFilePatternMatcher() {}
static void ParsePatternStr(LPCWSTR pwzPatt,
Pattern &patt);
bool FileMatches(const WIN32_FIND_DATA &fd,
size_t &uSigIDRet);
};
public __gc class MFindFilesByPatternAndSig {
public:
__gc struct ManagedFileData {
String *psFName;
String *psPath;
UInt64 uSize;
UInt64 ftMod;
UInt32 uSigGroup;
UInt32 uAttribs;
};
__gc struct ManagedPatternGroup {
UInt32 uSigID;
Byte signature __gc[];
String* aPatts __gc[];
};
__delegate void DelFileCB(ManagedFileData *pFD);
private:
_CFilePatternMatcher *m_pFPM;
DelFileCB *m_pDelFileCB;
ManagedFileData *m_pFileData;
IAsyncResult __gc*volatile m_pRes;
volatile bool __nogc*m_pbStop;
public:
explicit MFindFilesByPatternAndSig(
ManagedPatternGroup* aPattGrp __gc[],
bool *pbStop);
~MFindFilesByPatternAndSig();
UInt32 FindFiles(String *psDir, bool bSubdirs,
DelFileCB *pDelFileCB);
private:
size_t _FindDeeperFiles(LPCTSTR ptzSubDir,
::std::wstring &wsSubPath);
static void _AppendSubDir(::std::wstring &wsSubPath,
LPCTSTR ptzSubDir);
};
The key to MFindFilesByPatternAndSig's performance and interoperation with a GUI, is the minimal data structures used to marshal data between the GUI and native code. Struct ManagedFileData is the only data marshaled back to the GUI thread. ManagedPatternGroup is only used to pass initialization data to MFindFilesByPatternAndSig.
Whereas a pure CLR implementation would require marshalling copious data on every file enumerated, MFindFilesByPatternAndSig only passes back data on matched files. It does this by passing a ManagedFileData object to its DelFileCB delegate, m_pDelFileCB. (described further in Synchronisation and performance details). The delegate is implemented by the GUI, and passed to MFindFilesByPatternAndSig via its only public method, FindFiles(), along with the path to search, and a Boolean whether to search sub directories.
Filename pattern and file signature matching
The unmanaged C++ class _CFilePatternMatcher, also in GatherFilenames.h, is the key to how MFindFilesByPatternAndSig finds specific files. When MFindFilesByPatternAndSig enumerates a file rather than a directory, it passes the WIN32_FIND_DATA to _CFilePatternMatcher::FileMatches(), which does the difficult work. Before we discuss how that works, we need to talk about how _CFilePatternMatcher is initialised by MFindFilesByPatternAndSig, via:
static void _CFilePatternMatcher::ParsePatternStr(
LPCWSTR pwzPatt, Pattern &patt);
When an instance of MFindFilesByPatternAndSig is created, its explicit constructor creates an instance of _CFilePatternMatcher, m_pFPM, on the unmanaged heap. It proved difficult putting the pattern parsing code purely in _CFilePatternMatcher's constructor, since it knows nothing about the CLR. Thus, MFindFilesByPatternAndSig's constructor decodes and marshals the CLR data, then calls ParsePatternStr() to load m_pFPM with unmanaged pattern and signature information.
Since CLR strings are always Unicode, ParsePatternStr() takes only Unicode strings (which are lower-cased before being passed-in). Although _CFilePatternMatcher will parse patterns to either ANSI or Unicode (depending on compilation target), it currently doesn't expect non-ASCII characters. I could have used C conversion functions for ANSI builds, but it was ugly and not really necessary, since filenames and extensions of compiler intermediate files are always ASCII.
If you need to port this class for true ANSI string compatibility, you can use WideCharToMultiByte() to copy the passed Unicode string (pwzPatt) into a char buffer for ANSI builds. However, this is not a full solution unless you also handle the possibility of MBCS characters, since in such cases you cannot assume one-byte per character (can be up to five bytes per character). This leads to isleadbyte() and related multibyte ugliness, or similar workarounds. And even if you do so, the fast "3-character extension" detection will break if multibyte characters exist. So, if you really need such support, I leave this as "an exorcise for the reader" (and I do mean exorcise).
We don't need to cover ParsePatternStr() in detail, as it's nothing new, a bit convoluted, and fairly well commented anyway. Suffice it to say, the idea is to find L'*' wildcards and L'.' characters, and determine if the pattern refers to a filename prefix (leading characters), suffix (ending characters), or whole-name match. If it's a suffix, and it looks like a dot with 3-letter extension (the most common case), we can do a fast match verification. The lower-cased string data and flags are stored in a std::vector of unmanaged Pattern structs.
This brings us back to the heart of file detection (some debug code has been removed for clarity):
bool _CFilePatternMatcher::FileMatches(
const WIN32_FIND_DATA &fd, size_t &uSigIDRet) {
ATLASSERT(*fd.cFileName != 0);
const size_t uLen = ::lstrlen(fd.cFileName);
const size_t uBytes =
(uLen * sizeof(TCHAR)) + sizeof(TCHAR);
LPTSTR ptzName = (LPTSTR)_alloca(uBytes);
memcpy(ptzName, fd.cFileName, uBytes);
_tcslwr(ptzName);
LPCTSTR ptzNameEnd = (ptzName + uLen);
for (size_t u = 0; u < m_vPatts.size(); u++) {
const Pattern &patt = m_vPatts[u];
if (patt.uFlags != kWholeMatch) {
if (patt.uFlags & k3LtrExt) {
if (uLen < 5)
continue;
LPCTSTR ptzLast4Chrs = (ptzNameEnd - 4);
if (*(const _FourChrUInt*)ptzLast4Chrs !=
*(const _FourChrUInt*)patt.sSuffix.c_str())
continue;
}else if (patt.uFlags & kEndsWith) {
const size_t uPostLen = patt.sSuffix.length();
if (uLen < uPostLen)
continue;
if (memcmp(patt.sSuffix.c_str(),
ptzNameEnd-uPostLen,
uPostLen*sizeof(TCHAR)) != 0)
continue;
}
if (patt.uFlags & kStartsWith) {
const size_t uPreLen =
patt.sPrefix.length();
if (uLen <= uPreLen)
continue;
if (memcmp(patt.sPrefix.c_str(),
ptzName, uPreLen*sizeof(TCHAR)) != 0)
continue;
}
}else{
if (uLen != patt.sPrefix.length())
continue;
if (memcmp(patt.sPrefix.c_str(),
ptzName, uLen*sizeof(TCHAR)) != 0)
continue;
}
uSigIDRet = patt.uSigID;
if (fd.nFileSizeLow == 0 &&
fd.nFileSizeHigh == 0)
return true;
ATLASSERT(patt.uSigIdx < m_vSigs.size());
const ByteStrT &bsSig = m_vSigs[patt.uSigIdx];
if (!bsSig.empty()) {
HANDLE hFile = ::CreateFile(fd.cFileName,
GENERIC_READ | FILE_WRITE_ATTRIBUTES,
FILE_SHARE_READ, NULL, OPEN_ALWAYS,
0, NULL);
if (hFile != INVALID_HANDLE_VALUE) {
DWORD dwRead;
const DWORD dwSigBytes = (DWORD)bsSig.size();
BYTE *pRead = (BYTE*)_alloca(dwSigBytes);
BOOL bOK = ::ReadFile(hFile, pRead,
dwSigBytes, &dwRead, NULL);
::SetFileTime(hFile, NULL,
&fd.ftLastAccessTime, NULL);
::CloseHandle(hFile);
if (bOK && dwSigBytes == dwRead &&
memcmp(bsSig.c_str(), pRead, dwSigBytes) == 0)
return true;
}else{
ATLTRACE(_T("Unable to open file: %s\n"),
fd.cFileName);
}
}
}
return false;
}
This method is called repeatedly during file enumeration, so it has to be fairly fast. The only significant bottleneck I notice is always converting the filename to lower case, but at least we put it into a stack buffer, ptzName, which is allocated via _alloca() to minimize stack growth. Why not just use lstrcmpi()? For one thing, that function expects complete null-terminated strings, and we sometimes need to do "BeginsWith" or "EndsWith" style comparisons, which compare partial strings. Second, our pattern strings are already lower case, so why call a slow case-insensitive function, when there's only one that needs case adjusting? Besides, memcmp() is very fast. Third, by far the most common comparison is not character-wise, but a comparison of an integral chunk of the last 4 characters, for dot+3 extensions. That's very fast and doesn't require walking either string.
Overall, the code is fairly straightforward. After lower-casing the filename, we iterate through all the patterns we have stored in vector m_vPatts, and see what kind of comparison(s) we need to do. Most often we do the fast extension check just described, else we make simple memcmp() calls. If the file passes all pattern tests, we check the file's size. If it's zero, we can't check the signature, but we say it matches because the file is useless anyway. Otherwise, we drop into the signature-checking code.
By far the slowest part is reading the file's signature, but by the time we get to that point, there is a very good chance of a match, so it doesn't execute very often. If there is a signature to verify, we simply read the initial bytes of the file, and compare it to the signature associated with the current pattern. Note that if you have Visual Studio open, some of its files will be locked and can't be read, so there's no danger of deleting active, signatured files in your open project.
You might notice we open files for both GENERIC_READ and FILE_WRITE_ATTRIBUTES. This allows us to restore each file's last access time. Considerate file searchers do this, since file scanning isn't full accessing like editing or processing a file would be. Backup, defragmenting, and other utilities can go by file access time, and we don't want to give a false impression that the files we sniff are frequently used.
Implementing a worker thread
The last notable bit of GUI code is a private managed class, _FinderThread, implemented in the main form's code. It simply wraps the needed thread data and thread procedure, so a worker thread can call the file finding class (MFindFilesByPatternAndSig, described above). I normally keep a queue of worker thread(s) in my applications (much more efficient, since thread creation can be costly), but this code suits CompilationCleaner's purposes:
__gc class _FinderThread {
public:
__delegate void DelSrchDoneCB();
private:
MFindFilesByPatternAndSig::DelFileCB *m_pDelCB;
MFindFilesByPatternAndSig::
ManagedPatternGroup *m_pPattGrps __gc[];
DelSrchDoneCB *m_pSrchDoneCB;
String *m_aPaths __gc[];
bool m_bSrchSubDirs;
bool *m_pbStop;
public:
_FinderThread(MFindFilesByPatternAndSig::
DelFileCB *pDelCB,
DelSrchDoneCB *pSrchDoneCB,
MFindFilesByPatternAndSig::
ManagedPatternGroup *pPattGrpArr __gc[],
String* aPaths __gc[],
bool bSrchSubDirs, bool __nogc*pbStop)
: m_pDelCB(pDelCB), m_pSrchDoneCB(pSrchDoneCB),
m_aPaths(aPaths), m_pPattGrps(pPattGrpArr),
m_bSrchSubDirs(bSrchSubDirs),
m_pbStop(pbStop) {}
void ThreadProc() {
MFindFilesByPatternAndSig *pGF;
pGF = __gc new MFindFilesByPatternAndSig(
m_pPattGrps, m_pbStop);
for (int i = 0; i < m_aPaths->Length; i++)
pGF->FindFiles(
dcast<String*>(m_aPaths->Item[i]),
_bSrchSubDirs, m_pDelCB);
m_pSrchDoneCB->Invoke();
}
};
You might notice frequent use of GC arrays, as I tried to avoid too many untyped containers such as ArrayList, which can be quite slow. In retrospect, GC arrays are a pain to deal with, unlike plain C++ arrays, but I'm not going to rewrite everything after all that work, just to avoid the confusing syntax (nicer in VS 2005), which is a tad cleaner in C#.
The constructor takes the thread data needed to run the search, and simply copies them into member pointers. There are two delegate parameters, the first for calling back to the GUI thread with found file data (described further below), and the second to be called on completion of all searching, when statistics are gathered. The GC arrays pPattGrpArr and aPaths, describe what kind of files and under which path(s) to search for them, respectively. The ManagedPatternGroup struct is defined as:
__gc struct ManagedPatternGroup {
UInt32 uSigID;
Byte signature __gc[];
String* aPatts __gc[];
};
The first field is mostly for future modifications, to identify which signature a file has when its data is called back. The signature itself is a byte array, so it can be binary or ASCII (Visual Studio files commonly have ASCII signatures). If the array's length is zero, no signature will be checked. The "patterns" array, aPatts, contains one or more strings for finding appropriate filenames (usually by extension), but there are limitations (described fully in Using CompilationCleaner). Pattern limitations were needed to increase searching efficiency, since Win32's FindFirstFile() and friends, cannot take multiple patterns nor enumerate directories while finding by pattern.
Back to the constructor, the bSrchSubDirs parameter specifies whether sub-directories are to be searched, and pbStop is a non-GC pointer to a Boolean, that's set to true to stop the worker thread easily. Fancy synchronization objects, like events or critical sections, are not needed in this simple situation, since there is no data to be locked (it's all marshaled).
The thread procedure creates an instance of MFindFilesByPatternAndSig, and for each path to search, initiates a search. When all searches are done, the "search done" delegate, m_pSrchDoneCB, is invoked to gather and display statistics.
MFindFilesByPatternAndSig is designed to be run on a worker thread (as just described), and uses its delegate's BeginInvoke() and EndInvoke() methods to asynchronously pass data back to the GUI thread safely. FWIW, a pointer to the same GC ManagedFileData struct, m_pFileData, is used throughout the search operation. This is not because GC heap is slow to allocate, it's actually very fast, but this simply avoids allocating many KBs of temporary data on the heap, that will only require cleanup anyway. The performance advantage is minimal, and if new objects were allocated for each callback, we wouldn't have to worry about data synchronization. However, we still need to wait for EndInvoke() anyway, so that we don't call back with more data, before the previously sent data has been consumed by the GUI thread.
The private method _FindDeeperFiles(), is just a slimmer version of FindFiles(), that only gets called when sub-directory searching is enabled. It uses the private static _AppendSubDir() method as a very fast way to append a subdir to a wchar_t based C++ string. By always using a Unicode string, marshaling to a CLR String is straightforward. In fact, the string is never reallocated (unmanaged heap is slow), just effectively "truncated" back to its previous length, as _AppendSubDir() walks back up the directory tree. For greater versatility, compilation for ANSI Win9x platforms is provided for, although CompilationCleaner was initially targeted at NT based platforms on which VS.NET runs.
Persistent data storage
There has long been a controversy whether to store app data in INI files, the Windows registry, COM documents, XML files, or serialized data files. I used the latter, since it's difficult to save binary data in INI files, the registry is already overused (access keeps degrading), documents are MFC-oriented and overkill here, and XML is slow and tedious to use compared to binary storage, although it would be a good choice if we needed to do internet transfers. Even Microsoft are using serialization quite a bit these days.
The managed class MStorage, in Storage.h, wraps CLR serialisation of data to and from disk. It defines three data structures, as shown in this abbreviated declaration:
public __gc class MStorage {
public:
[Serializable]
__gc struct PattGroup {
String *psName;
String* aPattStrs __gc[];
Byte aSig __gc[];
bool bBinSig;
UInt32 uSigID;
};
[Serializable]
__gc class PattColl {
public:
String *psName;
String *psAllPatts;
ArrayList *pGroups;
PattColl() {}
PattColl(String *psCollName,
String *psAllPattStrs, ArrayList *pGrpList)
: psName(psCollName), psAllPatts(psAllPattStrs),
pGroups(pGrpList) {}
PattColl(PattColl *pToCopy);
};
[Serializable]
__gc struct StoredData {
ArrayList *pColls;
ArrayList *pPaths;
int iActiveFilter;
};
StoredData *m_pStore;
MStorage() : m_pStore(__gc new StoredData()) {}
void LoadFromDisk() {
String *psProfDir =
Environment::ExpandEnvironmentVariables(
S"%USERPROFILE%");
FileInfo *pFI =
__gc new FileInfo(String::Concat(psProfDir,
S"\\CompClean1.dat"));
m_pStore = NULL;
if (pFI->Exists) {
BinaryFormatter *pFmtr =
__gc new BinaryFormatter();
FileStream *pStrm;
try {
pStrm = pFI->OpenRead();
m_pStore = dcast<StoredData*>(
pFmtr->Deserialize(pStrm));
}catch (Exception *pE) {
MsgBox::Error(String::Concat(
S"Unable to load data file: ",
pFI->FullName, S", Error: ",
pE->Message));
}__finally{
pStrm->Close();
}
}
if (_PattsInvalid()) {
m_pStore = __gc new StoredData;
m_pStore->pColls =
CreateDefaultPatterns();
}
}
void SaveToDisk() {
String *psProfDir =
Environment::ExpandEnvironmentVariables(
S"%USERPROFILE%");
String *psFullPath = String::Concat(psProfDir,
S"\\CompClean1.dat");
BinaryFormatter *pFmtr = __gc new BinaryFormatter();
FileStream *pStrm;
try {
pStrm = File::Open(psFullPath, FileMode::Create);
pFmtr->Serialize(pStrm, m_pStore);
}catch (Exception *pE) {
MsgBox::Error(String::Concat(
S"Unable to save data to: \"",
psFullPath, S"\", Error: ",
pE->Message));
}__finally{
pStrm->Close();
}
}
static ArrayList* CreateDefaultPatterns();
static String* CopyToGCStrArr(IList *pList) __gc[];
ArrayList* GetDeepCopyOfPatternsCollection();
private:
bool _PattsInvalid();
};
The [Serializable] attribute is what allows data to be automatically serialised. In fact, there is only one overall serialisable object, MStorage::StoredData *m_pStore. It can contain any amount of data, but primarily holds ArrayLists of PattColl objects (which in turn contain PattGroup objects) and search path strings. More serialisable members can be added to StoredData for other needs.
The core methods of MStorage are LoadFromDisk() and SaveToDisk(). Both determine the data storage path by calling the CLR's Environment::ExpandEnvironmentVariables(S"%USERPROFILE%"), which calls its Win32 counterpart with the same name. A BinaryFormatter and FileStream objects are used together to deserialise to, and serialise, m_pStore. It doesn't get much simpler, and it's very fast!
The remaining methods are just run-of-the-mill constructors and helpers with the usual boiler plate code.
Gotchas
ListView and events
The CLR ListView is an object-oriented wrapper around a native Windows ListView Common Control. However, having to always access items as full objects, makes some normally obvious and intuitive features difficult to work with. Workarounds require tricky code or experimentation (just what the CLR is supposed to prevent). Certain native features have no CLR equivalent.
It is easy to select all or no items in a native ListView (checking and unchecking is just as easy). The CLR ListView has no such feature. Instead, one must iterate over the entire collection of items. This also means the ListView's BeginUpdate() and EndUpdate() methods should be called, to avoid painfully-slow one-by-one redrawing of items.
Native ListViews also generate both LVN_ITEMCHANGING and LVN_ITEMCHANGED events. The CLR wrapper has some "changing" events without corresponding "changed" events, whereas other controls have "changed" events without a corresponding "changing" event. For example, the code to enable/disable the "Clean Checked" button depends on the ListView's ItemCheck event ("changing"). The code has to speculatively predict whether the checked count will increase or decrease, and enable the button before any changes actually occur. The predictions work in this simple instance, but it is not a good code practice. Should something like a caught exception prevent a change from occurring, speculations become invalid.
CLR ListBoxes have SelectedIndexChanged events, but no SelectedIndexChange ("changing") event. This makes the Filter dialog's handling more complex than it should be. Changes that should not have been allowed must be blocked, and unacceptable results calculated in the event handler, require undoing the selection change, as well as any changes in other controls and data that occurred due to the original selection change. All this would be simple (and far less confusing to debug) if there were simply a selection "changing" event.
Furthermore, when the user selects multiple items, the CLR's ListView automatically checks all but the selected item with focus. This alone can be frustrating, but if many items are selected, it takes an incredibly long time for the ListView to update.
PtrToStringAuto and Friends
One is tempted to use "Auto"-suffixed marshalling methods, when writing for both Unicode and ANSI builds. This is not incorrect, but if you attempt to debug or run ANSI builds on Unicode platforms, you will get corrupted data.
Why? "Auto" marshalling goes by the platform that is running, not the target platform. Thus, when compiling with mixed managed and unmanaged C++, you might prefer to call something like this instead:
inline String* StringFromLPCTSTR(LPCTSTR ptzStr) {
#ifdef UNICODE
return ::System::Runtime::InteropServices::
Marshal::PtrToStringUni((int*)ptzStr);
#else//ANSI
return ::System::Runtime::InteropServices::
Marshal::PtrToStringAnsi((int*)ptzStr);
#endif
}
Conclusion
I would like to thank the following contributors who provided invaluable feedback:
- Peter Ritchie - identified inadequate explanation of control event problems.

