
Introduction
In this article, I’ll discuss the basics of EDIFACT messages, talk about the evolution of an idea for converted EDI messages into XML, and demonstrate the concepts in code. Ultimately, the goal is to demonstrate how the framework is used to take in EDI messages and turn out whatever format you want using XML transformations. I’ll also point out the most significant pieces of code you may find interesting, and can (better said should) expand on.
Background
About 10 months ago, I was asked to help out in assembling a BizTalk solution for a company that was already delivering late to the customer. I had never sat down with BizTalk before and the only thing I really knew about it was that it automated message processing. That may certainly be an over simplification of the product but, picking up or receiving, processing, and delivering business-centric messages is essentially all that it does.
Back then, I was brand new to business messaging frameworks and didn’t know much about them. Because there are so many different messaging standards, I can still humbly say I don’t know too much. And although I got burned by the previously mentioned company, it was a good experience getting to know BizTalk and the EDIFACT standard.
Like many just getting started with EDI, I Googled my way around to familiarize myself with the standard and read about the experiences of those who have gone before me. What I discovered was that there isn’t much to be discovered. In fact, with the exception of BizTalk, and similar budget-breaking solutions, there isn’t a whole lot written on the subject. What solutions there are, seem more like black-boxes with car-sized prices tags than frameworks to build on. Thus, I began my quest to try and create something useful, which could do similar operations for smaller organizations on the cheap.
The EDIFACT Standard
Like all messaging standards, EDIFACT was created to try and unify a way of sending messages between companies. It is a standard created and maintained by United Nations, comprised of roughly 3000 pages, providing rich semantics for electronic data interchange for both trade commerce and transport. For many mere mortals, the semantic is difficult to understand and implement, however I’ll try to demonstrate that, it really is easy once you understand the construct. The standard defines such things as: pricing catalogs, orders, order responses, invoices, and many others.
Figure 1 - INVOIC implementation

Unfortunately, not every country implements this standard the same way. Adding further complication, different industries only use certain segments relevant to their needs in order to conduct electronic commerce. Figure 1 demonstrates this point by showing one implementation of the INVOIC message. The white boxes highlight the segments that are used, while the gray boxes are ignored. Because of these differences, it may seem more fluid than standardized, but it is really flexible. The documentation for each message aids in making it predictable.
Figure 2 - EDIFACT segment

An EDIFACT message contains many sections called segments. Each segment contains many sub-sections called composites, and each composite contains none or more sections of information called data elements. See Figure 2.
Each segment begins with a three letter acronym identifying what type of segment it is. The EDIFACT standard defines what segments are allowed in which types of messages. For example, whether processing an order or an invoice, the message type can only contain a certain number of predefined segments, in a predefined order. Of course, it’s a large standard that encompasses far more than any one company needs to conduct routine business. As such, many implementations only use a fragment of the segments from each corresponding message standard.
As seen in Figure 2, which is an example of a D93A version message, an EDIFACT message contains three primary delimiters to separate the sub-sections of a segment. Segments themselves are delimited by an apostrophe, while composites are delimited by a plus sign. Data elements within composites are delimited by semicolons. It should be mentioned that there are special circumstances when a delimiter will need to be interpreted as normal character and not as a delimiter. In that case, it’s detectable by observing a question mark in front of the delimiter. For example, 2?+2=4 actually means 2+2=4. A question mark preceding a delimiter restores the character meaning. Question marks are represented as ??.
Figure 3 - Segment grouping

Let’s talk for a minute about grouping. Segments are grouped in a logical manner as to present structure to their meaning. As seen in Figure 3, groupings include: Interchange, Functional, and the actual message. The Service String Advise can generally be ignored.
For the sake of simplicity, the framework presented in this sample is void of structured grouping. That is not to say that grouping segments are not handled, because they are; albeit all but one is ignored. As you will see, it’s easy enough to implement them, but wasn’t pertinent to demonstrating the idea of converting EDI to whatever you want.
EDI to XML Framework
Before going any further, I think it’s worth noting that there are just as many ways to parse delimited files as there are ways to skin a cat. Far be it from me to tell you which one is the right way but, in the examples to follow, the Split function works just fine for the purpose of this demonstration. Additionally, as stated earlier, there are conditions when a delimiter should not be interpreted as a delimiter. In code, those situations are easy to detect with help from such things as regular expressions, but are not implemented in the code. I’ll point out where and when would be a good place to detect the situation, but leave it up to you to implement it (Don’t you hate that? ;-) Come on, it will be fun!) That said, let’s move on.
From the ten-thousand foot view, the framework is a set of sequential steps that cascade upon one another to build up a message object that represents the information it contains.
Figure 4 - EdiMessage overview
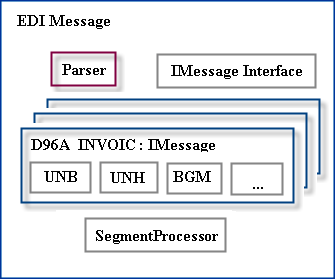
Looking at Figure 4, the initial entry point for handling EDI files is the EdiMessage class. EdiMessage conveniently accepts the file path to an EDI file in the constructor. Handled this way, the constructor reads in the file and instantiates a Parser class. The parser accepts the read in EDI message as a string parameter. The parser then begins to break apart the EDI message into Segment objects by using the Split function. Since the special cases where a delimiter character should not be interpreted as a delimiter are most likely to occur within a segment string, I recommend implementing a regular expression search when the segment string is passed into a Segment object. A Segment object is just a convenient container object for storing the name of the segment (UNH, BGM, etc.), as well as a FieldCollection. The FieldCollection contains both simple and composite data elements. The framework could have been written to avoid wrapping the segment and fields in named objects, and maybe will be in the future, but are used here and now for brevity.
Figure 5 - INVOIC Date/Time/Period (DTM) segment

Because of the way most EDIFACT message implementations are constructed, it’s not always necessary to explicitly separate composite types and the data elements they contain. When parsing the data elements to populate a specific Segment class, the industry specification makes it easy to know what the element offsets are by explicitly stating what is used in the message specification. Used wisely, this information demonstrates how to use the offsets to populate an IMessage-derived object, such as D96A_INVOIC. Figure 5 displays the Date/Time/Period (DTM) segment from such a specification, and is shown here to demonstrate just how easy it is to determine what to expect.
The ParseDocument() method of the Parser class uses the UNB and UNH grouping segments to populate a MessageProperties structure for each message. Since there is potentially several messages within a single file, MessageProperties is used to determine the number of messages it contains, the message identifier, version, and so forth.
The Parser's CreateMessageObject() method is where things really start to get interesting (see Listing 1). First, an array of SegmentCollections is created, where there is one collection for each message in the original file. A new collection gets created every time a new UNH segment is detected. It and each trailing segment are added to the current collection until the next UNH segment is found.
Listing 1
for (Int32 j = 0; j < arSegments .Length; j ++)
{
string name = arSegments[j] .Name;
if( name == "UNA" || name == "UNB" ||
name == "UNG" || name == "UNE" ||
name == "UNZ" ) continue;
if( name == "UNH" ) sc[scCount] =
new SegmentCollection();
if( name == "UNT" )
{
sc[scCount] .Add(segments[j]);
if (j == arSegments .Length - 1)
break;
scCount ++;
continue;
}
sc[scCount] .Add(segments[j]);
}
UNT represents a special case because it flags itself as the last one in a message group. Also because it may be the last segment in the entire segment array. If it is the last one, it exits the loop and moves on to instantiate as many IMessage-derived objects as there are SegmentCollections in the segment collection array.
An IMessage-derived class is simply a message class that implements the IMessage interface. IMessage defines a single method called PopulateMessage(). PopulateMessage() accepts an array of segments and instantiates the equivalent class for each segment. For example, if the current Segment object has a name of UNH, PopulateMessage instantiates a UNH object, populates the appropriate fields with the data element values, and the UNH object gets added to the message class (ORDERS, INVOICE, etc.).
As seen in Listing 2, CreateMessageObject() then starts looping over the array of SegmentCollections. It extracts each item in the collection to build up a temporary array of Segment. A reference to this temporary array of segments gets passed to the IMessage-derived object as a parameter of the PopulateMessage() method.
Listing 2
for(Int32 i = 0; i < sc.Length; i++)
{
this.messageObject[i] = GetMessageType(mp.releaseNumber,
mp.identifier);
Segment [] tempSegments = new Segment[sc[i].Count];
Int32 j=0;
foreach(Segment s in sc[i])
{tempSegments[j] = s;j++;}
try
{
this.messageObject[i].PopulateMessage(
ref tempSegments);
}
catch(Exception e)
{
…
}
finally
{
tempSegments = null;
}
}
You may be asking why not just pass an index of the SegmentCollection into PopulateMessage(). The truth is, as you will see in a moment, I left it up to you to decide how to best implement this part of the message class. As stated earlier, each EDI message class implements the IMessage interface which mandates one method, PopulateMessage(). PopulateMethod() accepts an array of Segment that make up a complete, albeit UNH-UNT, EDIFACT message. However, the message class, for example the D96A_INVOIC class, acts as a wrapper around a single message object, INVOIC, consisting of various group objects, containing various segment class objects. Optionally, if you chose to pass PopulateMessage() the array of SegmentCollection, D96A_INVOIC could then instantiate an array of INVOIC objects and populate each one internally. I chose not to do this specifically because I had other requirements. However, implementing it this way keeps it simple in case I need to refractor it in the future.
Initially, PopulateMessage() would iterate over each Segment, populating a corresponding Segment class object (such as UNH, BGM, DTM, etc.), then submit the object to the INVOIC's Add() method (Listing 3). Add() takes the Segment class object, and using the field identifiers, places it in the appropriate segment group in the INVOIC class (Listing 4).
Listing 3
case "UNH":
UNH unh = new UNH();
for(int j = 0;j < segmentArray[i].Fields.Count;j++)
{
switch(j)
{
case 0:
{
unh.referenceNumber =
segmentArray[i].Fields.Item(j).Value;
break;
}
case 1:
{
unh.typeIdentifier =
segmentArray[i].Fields.Item(j).Value;
break;
}
case 2:
{
unh.versionNumber =
segmentArray[i].Fields.Item(j).Value;
break;
}
case 3:
{
unh.releaseNumber =
segmentArray[i].Fields.Item(j).Value;
break;
}
case 4:
{
unh.controllingAgency =
segmentArray[i].Fields.Item(j).Value;
break;
}
case 5:
{
unh.associationAssignedCode =
segmentArray[i].Fields.Item(j).Value;
break;
}
}
}
INVOIC.Add(SegmentType.UNH,unh);
unh = null;
break;
Listing 4
case SegmentType.DTM:
{
int qualifier =
Int32.Parse(((DTM)obj).dateTimePeriodQualifier);
if(qualifier == 171)
{
if((i= this.GRP1.Count) > 0)
this.GRP1[i-1].DTM = (DTM)obj;
}
else
{
this.DTMCollection.Add((DTM)obj);
}
break;
}
Once I realized I was writing the same iterative code for each message object seen in Listing 3, it made sense to create the SegmentProcessor class for just that purpose. PopulateMessage() instantiates an instance of SegmentProcessor, which accepts a delegate type in the constructor. The delegate gets assigned to a property that points to the Add() method of a message object (See Listing 5). Next, SegmentProcessor’s ProcessSegments() method is called and the Segment objects are created and populated as shown in Listing 3. Only this time, instead of calling the message object's Add() function, SegmentProcessor calls the delegate property AddFunction().
Listing 5
public delegate void AddSegmentDelegate(SegmentType segmentType,
object segmentObject);
public void PopulateMessage(ref Segment [] segments)
{
SegmentProcessor sp = new SegmentProcessor(
new AddSegmentDelegate(this.INVOIC.Add));
sp.ProcessSegments(segments);
}
public SegmentProcessor(AddSegmentDelegate myDelegate)
{
this.addFunction = myDelegate;
}
AddFunction() passes the populated Segment object back to the calling message object and proceeds to add the Segment object as seen in Listing 4.
Finally, once all messages in the original EDI file are parsed, message objects are created and populated, they are made available via the Parser’s GetMessages() method. GetMessages() simply returns the array of IMessage objects the Parser now contains.
Message Objects to XML
At this point, all EDI message processing is done. The only thing left to do now is convert the message objects to XML. I don’t know about you, but I really like what .NET has brought to the table in the sense of XML processing. In cases like these, I’m especially fond of XML attributes and using them with the XmlSerializer class. For example, simply decorating the segment and message classes with XML attributes (See Listing 6) allows me to take advantage of the XmlSerializer class to generate XML documents from my class objects. Brilliant!
Listing 6
[XmlType(TypeName="DTM",Namespace=Declarations.SchemaVersion),
XmlRoot,Serializable]
public class DTM
{
[XmlAttribute(AttributeName="dateTimePeriodQualifier",
Form=XmlSchemaForm.Unqualified,
DataType="string",
Namespace=Declarations.SchemaVersion)]
public string __dateTimePeriodQualifier;
[XmlIgnore]
public bool __dateTimePeriodQualifierSpecified;
[XmlIgnore]
public string dateTimePeriodQualifier
{
get { return __dateTimePeriodQualifier; }
set {
__dateTimePeriodQualifier = value;
__dateTimePeriodQualifierSpecified = true;
}
}
…
public DTM()
{
}
}
Now all we have to do is pass the object type and the actual object we want to convert to XML to an XmlSerializer object and call the Serialize() method (See Listing 7).
Listing 7
public XmlDocument [] SerializeToXml()
{
XmlSerializer sr;
StringBuilder sb;
XmlTextWriter tr;
xDoc = new XmlDocument[messageArray.Length];
try {
for(Int32 i = 0; i < messageArray.Length; i++)
{
System.Type type = messageArray[i].GetType();
sr = new XmlSerializer(type);
sb = new StringBuilder();
tr = new XmlTextWriter(new
StringWriterWithEncoding(sb,
System.Text.Encoding.UTF8));
sr.Serialize(tr, messageArray[i]);
tr.Close();
xDoc[i] = new XmlDocument();
xDoc[i].LoadXml(sb.ToString());
}
return xDoc;
}
catch(Exception ex)
{
Console.WriteLine(string.Format("Exception: " +
"{0}. InnerException: {1}.",
ex.Message, ex.InnerException));
return null;
}
finally
{
sr = null;
sb = null;
tr = null;
}
}
SerializeToXml() leverages the XmlSerializer class to convert the message objects to XML. Looping through all the messages returned by GetMessages(), SerializeToXml() first gets the type of the IMessage-derived message object. Next it instantiates an XmlSerializer object, passing in the message object's type and the actual message object to the constructor. An XmlTextWriter object is then constructed to write with, accepting in a StringBuilder object to write to. Finally, a call to the XmlSerializer's Serialize() method converts the message object to XML. The result is written to the StringBuilder object which then is used in the XmlDocument's LoadXml() method. Lastly, the array of XmlDocument are handed back to the caller.
Now the question becomes, what do you want to do with possibly many XmlDocuments in the xDoc array.
XML to Whatever You Want
EdiMessage contains three more interesting methods to work with:
SerializeToFile(string filename)TransformToFile(string XslFilename, string filename)Transform(string transformFile, ref XmlDocument[] transformedXml)
SerializeToFile() does just what it says, it writes out each XmlDocument in xDoc to disk. The files written here are mirror reflections of the message objects, only XML, not binary or EDIFACT.
TransformToFile() accepts an XSL/XSLT file name as input, uses it to conduct a transformation for each XmlDocument object, as well as a string that is used to specify the filename each transformed file will be called.
Transform accepts the name of XSL/XSLT file that is used to conduct a transformation for each XmlDocument object in xDoc. It also takes as a reference the variable name of an array of XmlDocument objects. This array will become the result of the transformation. The passed in array need not be initialized, as it will be done as necessary inside the method.
It is also important to note the AnalyseFileName() function. Although a private method, this function accepts what is generally the filename submitted to SerializeToFile() and TransformToFile(). AnalyseFileName() takes a string with embedded delimiter macros that assist in renaming the file to something more meaningful. This is useful for a couple of different reasons. For starters, it assists in creating unique names for the filename output. This is extremely handy when there is more than one XmlDocument object in xDoc. What happens if you just supply a simple string, such as "MyFile.xml”, to save the file as when there is more than one object in xDoc? Simple, each one overwrites the last until the final object is written. This leaves just one file on the disk for what should have been many. However, leveraging delimited macros, such as %ID%, helps create unique names for each object.
Using %ID% in a filename, such as MyFile_%ID%.xml, would output several uniquely named files to disk. Each file name would begin with "MyFile_", contain a GUID value, and end with a ".xml" extension. For example, "MyFile_ 400E0E5A-A319-4795-A9AE-79105EE834F1.xml".
AnalyseFileName() can handle several delimited macros. They can be used individually as shown above, or combined to generate something even more meaningful.
| Table 1 File Name Macros
| |
| %D% | Current Date |
| %ID% | GUID |
| %I% | Increment |
| %MR% | Message Reference Number |
| %MT% | Message Type (ORDERS, INVOIC, DESADV, etc.) |
| %T% | Current Time |
Most of the macros are self-explanatory, but let's take a second to expand on Increment. By default, Increment is zero-based; meaning the counter starts at 0. However, EdiMessage has two properties to adjust the initial value and step multiplier.
IncrementSeed sets the initial value of Increment, while IncrementStep determines the multiplier used when incrementing subsequent calls. If the default values are used in a specified file name, Increment will first return 0, then 1, then 2, and so on. If the initial value is changed by setting IncrementSeed to 5, and IncrementStep to 5, using Increment in the filename will first return 5, then 10, then 15, and so forth. Play with all the macros to see how they work. Add new ones to generate even more interesting naming schemes.
Conclusion
The concepts presented in this article demonstrate at least one way to handle the chore of working with EDIFACT messages. This article has covered the basics of what EDIFACT messages are, presented how they are defined in contrast to how they are implemented, as well as provides a means for consuming such demons and taming their worth. Far from a complete framework, the concepts and approach presented here may be beneficial to those looking for a way to create a general EDI to XML implementation. The project can also be customized and applied in a custom Biztalk pipeline solution. No matter where it is used, I hope you find it useful for converting EDIFACT messages into XML, and ultimately anything you want.
Using the Files
Demo project includes:
| WINEDIX.exe | GUI application for testing EDI to XML conversions. |
| EDIX.exe | Console application for testing EDI to XML conversions. |
| EDIFACT.dll | Contains EdiMessage class and all relevant functionality to conduct conversions. |
| AxInterop.SHDocVw.dll | Interop assembly for using browser control. |
| Interop.SHDocVw.dll | Interop assembly for using browser control. |
| Six EDI test files | D93A ORDERS, ORDRSP, INVOIC, DESADV, PRICAT. D96A ORDERS. |
| Four XSLT files | XAL_ORDERS_D93A, EAN_ORDERS_D93A, XAL_ORDERS_D96A, EAN_ORDERS_D96A. |
Source project includes:
| ConsoleEDIX | A console application for testing EDI to XML conversions. |
| EDIFACT | All C# source necessary to build EDIFACT dll. |
| WINEDIX | GUI application for testing XML to EDI conversions. |
Using WINEDIX, open an EDI file and click Convert. The EDI converted XML displays in the browser control.
Using one of the ORDERS' EDI files, select the corresponding XSLT file and click Convert.
ORDERS_D93A.edi goes with EAN_ORDERS_D93A.xslt or XAL_ORDERS_D93A.xslt.
ORDERS_D96A.edi goes with EAN_ORDERS_D96A.xslt or XAL_ORDERS_D96A.xslt.
Create your own XSLT files to convert the EDI XML into whatever format you want. Make sure to mind the namespaces: http://www.default.com/D93A/orders, http://www.default.com/D96A/orders".
History
License
This article has no explicit license attached to it, but may contain usage terms in the article text or the download files themselves. If in doubt, please contact the author via the discussion board below.
A list of licenses authors might use can be found here.

