Table of Contents
- Part One
- Introduction
- What Is A Symbol Server
- What Is Source Indexing
- How to Set Up A Symbol Server
- How to Index Your Source Files
- What's Happening In The Scripts
- Part Two
- Visual Studio Extension
- Using The Extension
- Writing Your Own Indexer
- Part Three
- Generating Minidumps
- Links
Introduction
A while ago, I had to set up a symbol server, with source indexing and at the time, there wasn’t a lot of information on the subject so I had some trouble getting everything to work the way we wanted. Unfortunately, there is still only that same information around but a lot more people seem aware of it since Microsoft released the source to the .NET Framework and automatically added their symbol server to Visual Studio 2010. Most people who work with the .NET Framework will now be aware that they can get symbol files and source code from Microsoft to debug the framework by using Microsoft’s symbol server, but how many people actually understand what a symbol server is or how Visual Studio gets the source code to the .Net framework? The answers are surprisingly simple and contrary to some peoples' beliefs that this technology has been around for what seems like forever, and it is available for you to use. So this article is here to enlighten you about the wonders of symbol servers and perhaps more importantly, source indexing.
What Is A Symbol Server?
A symbol server is basically just a very simple database using the file system, which is used to store different versions of symbol files. Both WinDbg and Visual Studio can use these databases through the SymSrv DLL that is provided with the Debugging Tools for Windows package to load the matching symbols for the application you are debugging. It’s really less of a database and more of a conveniently structured set of folders and files and as such, you are free top copy and paste your databases to wherever you like, the symbol server will still log transactions though and keep a record of everything that has been added or removed from the database and so you can’t just manually add files so far as I’m aware. An important note about the symbol server is that it doesn’t support multiple transactions at the same time, there’s no locking mechanism to prevent other people updating the database while a transaction is in progress so you may need to be careful that only one person is updating the database at a time.
Using a symbol server means that everyone can have easy access to the symbols for the latest build, and if you need to debug an older version of your application or library, then you won’t need to worry about digging out the symbol files yourself, they will be loaded automatically.
By itself, a symbol server can be a very convenient thing because it will allow you to see the callstack and other useful information when debugging. But say for example, you are debugging a crash that a client has experienced by loading up a minidump, and the source code on your machine no longer matches the source that was used to build that specific version of the application, you may have a difficult time finding exactly what caused the crash; this is where source indexing comes in.
What Is Source Indexing?
Source indexing is the act of embedding commands into the symbol files, which when run will extract the correct version of the source code from your source control system or grab it from some other backup that you may have in place. Your debugger is able to run these commands when it needs to open a file so that it can get the correct source file. So when you load up that minidump that your client sent you in an angry email, you can just load it up in Visual Studio and you’ll see the exact source code used to make that build as well as the error that was encountered with (hopefully) a big arrow pointing at the offending line of code.
How to Set Up a Symbol Server
The prerequisites for a symbol server are that you have some networked location to store the database, and even then if you’re the only user, it can just be a folder on your hard drive. The next step is to tell your debugger where the symbol server is, so that it can check it for symbol files when debugging.
In the more recent versions of Visual Studio, you need to go to Tools->Options->Debugging->Symbols and add the path to the symbol server. If your symbol server is on a network somewhere, then you should also specify a local cache for Visual Studio to copy the symbols to, that way, the next time you need those symbols you won’t need to download them from the network.
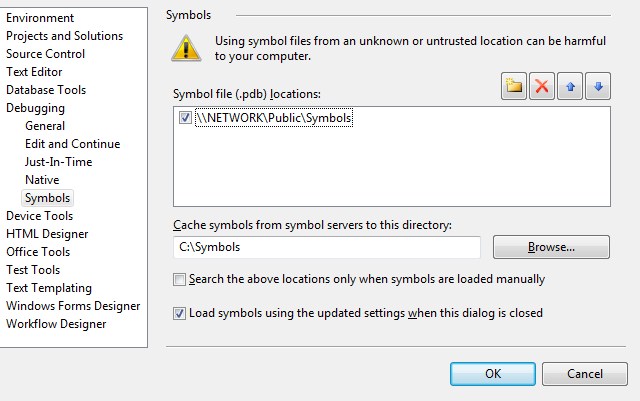
Fig 1. Setting up symbol servers in Visual Studio
In older versions of Visual Studio, it’s not enough to just specify the path to the symbol server you also need to tell it that it is a symbol server. You do that by putting SRV* before the symbol server path.
SRV* is just shorthand for symsrv*symsrv.dll* so if you ever see the full version, it means exactly the same thing. The SRV* syntax has a few variations:
SRV*LocalCache*SymbolServerPath
SRV*LocalCache*NetworkCache*SymbolServerPath
So you can specify different cache locations for each symbol server. And if you are getting your symbols from some offsite location, you can also specify a network cache so that when other users need the symbol files, they only need to download straight from your own network, rather than from the other side of the planet.
If you are using WinDbg, then to add a symbol server, you need to go to File->Symbol File Path and add the symbol server using the SRV* syntax above.

Fig 2. Setting up symbol servers in WinDbg
You can also set an environment variable for your symbol servers so that both Visual Studio and WinDbg (and presumably any other compatible debuggers) will know about your servers without explicitly setting them in each application.
The environment variable you need to create is _NT_SYMBOL_PATH and can be created in as either a User or System variable. It uses the SRV* syntax for each server and if you need to specify multiple servers, then you need to separate each with a semi-colon.
_NT_SYMBOL_PATH= SRV*c:\symbols*\\symbolserver;
SRV*c:\symbols*http://www.someotherplace.co.uk/symbols
At this point, you should have your debugger looking for symbols in your server, which at this point is likely empty. To add symbols to your server, you need to use SymStore.exe that is provided with the Debugging Tools for Windows. A basic command to add a set of symbols to the server would be:
symstore add /f "c:\MyProject\Output\*.*" /s "\\MySymbolServer\Symbols" /t "MyProject"
/v "Build 1234" /c "Example Transaction"
A note on each of the commands:
add tells symstore that we are adding files./f The path to the file (or files in this case) that we want to add, if you specify a path like I have done here, then it will search for any compatible files to add to the server - these include the debug pdb files that Visual Studio generates as well as the binary files themselves. Remember that if you are going to be debugging from minidumps, then you may have to add the binaries to the symbol server as well. I’m not aware of any way to specify multiple paths to add from, so if you wanted only the .PDB and .DLL files (but no executable files) you’d either have to run a separate command for each file or move all of the files you want backed up to the same folder./s The path to the symbol server to add the files to. If it’s just an empty folder, then it will add the necessary files and folders that turn your empty folder into a symbol server./t The name of the transaction, this is a required argument usually you’d just put the name of the project here, or any other identifying string./v The version number of the files you are adding. It’s not required and is only there for your convenience, so if you ever need to find a specific set of symbols manually you can./c A comment for the transaction, again it is not required but just there for the log file and your benefit.
Symstore has a fair few other arguments that allow you to set up your symbol server in a few different ways. I’ll not cover them here because there is a wonderful MSDN page that explains them all, which you can get to from the links at the bottom of the article.
How to Index Your Symbol Files
Before you add your symbol files to the server, you can embed commands in them to extract the current source code from your version control system, or anywhere else for that matter. There are some scripts included with the Debugging Tools for Windows that will index source code from various version control systems into your PDB files. I’ll give a quick example of how to use the scripts and then I’ll go over what is actually happening so that if you ever had the need, you could write your own scripts.
To use the source indexing scripts, you’ll need first to install Perl, as these are in fact Perl scripts. Once you’ve built your project and you’d like to index your PDB files with the additional information, your debugger will need to extract source code from your version control system, you need to go to the srcsrv folder in your Debugging Tools for Windows installation and find the relevant script for your version control, if for example, you are using Subversion, then you will need to be running svnindex.cmd. There are two arguments that you will need to pass to the script so that it can index your files, and they are a semi-colon delimited list of source paths which point to the working directories for your project, and a semi-colon delimited list of folders that your PDB files are in. So your command would look like:
svnindex.cmd /source="c:\SharedModules;C:\MyVeryImportantProject"
/symbols="c:\SharedModules\Release;c:\MyVeryImportantProject\Release"
The script will then insert the commands for each file in listed in the PDB files to extract them from SVN. In the case of SVN, if you need to use a specific user name and password you can also pass in /user=”MyUserName” /pass=”MyPassword” note that these parameters are specific to the svn script, other scripts may not always accept a user name and password and may have their own specific settings. As with most things in the console, you can view the help for each script by passing -? as the argument.
Each of the indexing scripts also supports loading the variables from both environment variables as well a configuration file called srcsrv.ini. When running the scripts, they will use the most local settings, so the command line arguments will override srcsrv.ini, which will override the environment variables. You can also specify a specific configuration file to use when running a script by adding /ini=”Path to ini file”.
What's Happening In The Scripts
Basically, the aim of the indexing scripts are to generate a block of data that looks like this:
SRCSRV: ini ------------------------------------------------
VERSION=1
INDEXVERSION=2
VERCTRL=Test
DATETIME=Mon, 04 October 2010
SRCSRV: variables ------------------------------------------
SRCSRVTRG=%targ%\%var4%\%var2%\%fnfile%(%var1%)
SRCSRVCMD=cmd /c copy "%var1%" "%SRCSRVTRG%"
SRCSRV: source files ---------------------------------------
D:\Documents\SKProjects\AlphaForms\AlphaForms\LayeredWindow.cs*11*_*AlphaForms\AlphaForms
*svn://192.168.1.5/AlphaForms/trunk/AlphaForms/LayeredWindow.cs
SRCSRV: end ------------------------------------------------
Where you have some information at the top about how to build the command, and then the arguments for that command listed for each file below. So if the command was a simple copy, then you may have the command as:
copy "%var1%" "%srcsrvtrg%
var1 refers to the first item in the list of variables which in this case would be D:\Documents\SKProjects\AlphaForms\AlphaForms\LayeredWindow.cs. srcsrvtrg is one of the named variables from the header of our block of data which specifies where the file will be copied. Your debugger will check if the file exists before calling the command, so if you’ve opened this version of the file before, there’s no need to rerun a potentially very slow command. srcsrvtrg is made from a few other named variables. targ is the local cache directory that the file will be put into and fnfile is actually a function that gets the filename from a path specified in the following parenthesis (which in this case is var1, the path to the file).
You may have noticed that everything between two modulus signs are treated as variables and will be replaced by the actual data they represent (if possible), this operation of substituting values is also recursive so like with the srcsrvtrg variable it will be replaced by the string it represents, and then the variables targ and var1 will be filled in.
As it is, inserting this data into the PDB file will be completely useless as it would just copy the file you already have on your system to somewhere else. A more realistic example would be this:
SRCSRV: ini ------------------------------------------------
VERSION=1
INDEXVERSION=2
VERCTRL=Subversion
DATETIME=Mon, 04 October 2010
SRCSRV: variables ------------------------------------------
SRCSRVTRG=%targ%\%var4%\%var2%\%fnfile%(%var1%)
SRCSRVCMD=cmd /c "svn cat "%var5%@%var2% --non-interactive > "%SRCSRVTRG%"
SRCSRV: source files ---------------------------------------
D:\Documents\SKProjects\AlphaForms\AlphaForms\LayeredWindow.cs*11*_*AlphaForms\AlphaForms
*svn://192.168.1.5/AlphaForms/trunk/AlphaForms/LayeredWindow.cs
D:\Documents\SKProjects\AlphaForms\AlphaForms\AlphaForm_WndProc.cs*10*_
*AlphaForms\AlphaForms*svn://192.168.1.5/AlphaForms/trunk/AlphaForms/AlphaForm_WndProc.cs
D:\Documents\SKProjects\AlphaForms\AlphaForms\AlphaForm.cs*10*_
*AlphaForms\AlphaForms*svn://192.168.1.5/AlphaForms/trunk/AlphaForms/AlphaForm.cs
SRCSRV: end ------------------------------------------------
The actual command would then be built from the variables specified in the main section, so for the first file, it would look like this:
cmd /c "svn cat " svn://192.168.1.5/AlphaForms/trunk/AlphaForms/LayeredWindow.cs@11
--non-interactive > "C:\Documents…"
This command would then be executed and hopefully put the desired file in our target directory where the debugger will then attempt to open it.
If you do want to write your own scripts or programs to index your PDB files, then all you need do is produce a block of data that looks like that and then insert it into your PDB files by using pdbstr.exe. The basic steps to indexing your source code yourself would be something like this:
- Gather a list of files in the working directory
- Get list of arguments for each file for the extract command
- Use
srctool to get a list of the files referenced in the PDB - Write the header of the data block to some temporary file
- For each file in the PDB add the arguments to the temp file
- Insert the data into the PDB using
pdbstr
To get a list of files referenced in a PDB, use:
srctool.exe "path to pdb file" –r
which will print out each file in the pdb on a new line. To add the data block to the PDB file, you need to use:
pdbstr –w –p:"path to pdb file" –s:srcsrv –i:"path to temp file"
The -w switch specifies that you are writing to the file, using -r would print the data stream (if it exists) to the console. -s gives the name of the data stream we want to write to which in this case is srcsrv. You can actually insert anything you want into a PDB file using any stream name you like, but Visual Studio will be looking for data in the srcsrv stream. -i gives the path to the input file that will be inserted into the PDB file, which in your case would be the file that you’ve written your data to.
Part Two
Visual Studio Extension
As it happens, I have actually written an extension for Visual Studio so that you can more easily index your symbol files and out them onto a symbol server, the extension works in VS2005 – VS2010 and will automatically install for any versions of Visual Studio that you have installed. All of the indexing code is written in C# (although still using the tools provided by the Debugging Tools for Windows package) so there is no longer any need to install Perl. I also add a couple of features that the standard scripts don’t cater for, although at the moment I only have an implementation for Subversion so the whole extensions usability is somewhat limited at the moment, although I’ve made it as easy as possible to include your own implementations through a simple interface which I’ll go over shortly.
Once you’ve installed the extension, you will see a new set of commands under Tools->Source Indexing. These options are only available when a solution is loaded, the reasons for which are because the settings are solution specific and as such are stored directly within the .sln file, and because the indexer gathers some information from the currently loaded solution.
The main interface that you will have with this extension is the settings dialog, which gives you options for setting the working copy locations that you would like indexed as well as the symbol files (as well as binaries) that you want stored in the symbol server, the location of the symbol server, the version control system plugin that will be used to index your files and finally a mirror of the Tools->Options->Debugging->Symbols page so that you can have more convenient access to the symbol server locations that Visual Studio will be using.
Fig 3. The Source Indexing Settings dialog
One of the features that I have added that the scripts didn’t cover is the option to backup modified or unversioned files to another location and have Visual Studio pull the files from there instead of from under source control. That way, if for example, you have some locally modified code that has gone into a daily build but hasn’t been checked in (maybe you bodged something for the build), then you still have the option to backup these files to use for debugging later. The provided implementation for SVN also has an added benefit over the standard scripts in that it will also pick up on the svn:externals property and index those folders accordingly, whereas the scripts would just ignore those folders because they did not belong to the current working copy.
Using the Extension
Before you can index and store your symbol files, you need to provide some information. The first step is to go to Tools->Source Indexing->Settings->General and add all of the working directory locations that the solution is using. This is not strictly necessary as the indexer will check every file in your solution to make sure it is indexed but relying on that backup feature can be very slow as the information for each file will be gathered individually, rather than all at once. On the same page, you then need to specify at minimum the PDB files that are to be indexed and stored on the symbol server, and you can also add any binaries that are to be backed up as well.
The next step is to specify the symbol server that will be used, this is necessary to index your files the indexer will not run without it. You can set this option on the Servers page, this page also gives you the option to backup any modified or unversioned files to some external location, if you want to use this option, you need to specify a location that the files will be backed up to, this can be any local or network path.
The final requirement is to choose the version control plugin that you want to use to index your files, this can be done on the Version Control page. If you require authentication for your version control system, then you can specify it here, be warned that this username and password will be stored in plain text in the .sln file. The alternative is to leave the username and password fields blank, you will then be asked for them when you index your solution, be warned again that these credentials will be embedded (in plain text) inside the PDB files to be indexed.
Once you’ve set all of the required fields, you can index and backup your solution by clicking Tools->Source Indexing->Index Solution, you will then be presented with a dialog asking for information about the current transaction for the symbol server. The only required field is the Product Name which already has a default, once you’ve set what you want, simply click OK and your symbols will be backed up.
Fig 4. Symstore Transaction dialog
Writing Your Own Indexer
If you want to write your own indexer for a different version control system (only Subversion is supported at the moment), then all you need to do is implement a very simple interface provided in SourceIndexingInterface.dll and create a DLL which you can put in the Modules folder of the source indexing installation folder. The interface looks like this:
namespace SourceIndexing.Interface
{
public interface ISourceIndexer
{
IIndexerHost Host { set; }
string Name { get; }
void IndexFolder(string FolderPath, bool recursive);
FileStatus GetFileInfo(string FilePath, ref ICommandArgs Args);
void SetCredentials(string userName, string password);
string[] GetCommandArgs();
string GetExtractCommand();
}
public interface ICommandArgs
{
string this[string key] { get; set; }
}
public interface IIndexerHost
{
void AddFile(string filePath, FileStatus status, ICommandArgs Args);
ICommandArgs CreateCommandArgs();
void OutputInfo(string text);
}
[AttributeUsage(AttributeTargets.Class, Inherited = false)]
public class CustomIndexer : Attribute
{
public string Name { get; set; }
public CustomIndexer(string Name)
{
this.Name = Name;
}
}
public enum FileStatus
{
Modified,
Unversioned,
CheckedIn
}
}
The interface you need to implement is ISourceIndexer - you can have as many indexers in a single DLL as you like as long as each is marked with the CustomIndexer attribute; the name you provide to this attribute is the name that will be displayed in the settings dialog.
IIndexerHost is the generic indexer that will call the methods of the actual indexer and will be set when your implementation of ISourceIndexer is first loaded. If credentials are also required, they will be set via the SetCredentials method and you will be expected to use them when interacting with the source control system.
The most important function here is IndexFolder, from this function, you are expected to gather any necessary information from each of the files in the specified folder and call AddFile on your IIndexerHost for each file you gather information for. If the recursive flag is set, then you are expected to gather information for all subdirectories as well. When implementing these functions, remember that you can never provide information on too many files as only the files listed in the final PDB will be included. If however you miss any files from the solution, then GetFileInfo will be called for each file, you should not call AddFile from here, only fill in the ICommandArgs structure (if you can) and return the state of the file either CheckedIn for files that are checked in and up to date, Modified for files that are under version control but have local changes or Unversioned for files that are not under source control. If you specify Unversioned for the file status, then you do not need to fill out the ICommandArgs structure.
Before I continue, I will explain the GetCommandArgs method and the ICommandArgs structure. Remember earlier on when I was discussing the format of the data that is inserted into the PDB file, well each of the variables that are listed in the main section of the data are represented by the ICommandArgs structure. To give my implementation a little more structure, you are required to name each of the variables that you are going to insert into the PDB file, these variables are limited to those that you return from the GetCommandArgs method. A common argument that you will need to add is the path or address to the repository where you source code was. The implementation for the SVN plugin looks like this:
public string[] GetCommandArgs()
{
string[] myArgs = {"Url"};
return myArgs;
}
As noted in the comment there, Filepath and Revision are always included in the command args as they are necessary for the indexer to function properly. The Filepath argument must always contain the full path to the file that you are gathering information on, and that is the path on the file system, not in your repository. Any other arguments you need must be specified here, when you call CreateCommandArgs on your indexer host it will create an instance of a structure that you can use, but it will only allow you to use the arguments that you have already specified.
To set variables in an ICommandArgs structure, you just use it like a dictionary (although you can’t add any new keys to it, or query to see if a key exists, or remove keys. I suppose it’s a poor example really):
ICommandArgs args = m_host.CreateCommandArgs();
Args["Url"] = "repository path to file";
Args["Filepath"] = "path to file";
Args["Revision"] = "56";
All variables are strings, you cannot put ints or other data types directly into the ICommandArgs structure.
The final function you need to implement is GetExtractCommand where you return a command, which when built with the arguments you have specified will extract the source from some repository or other location and copy to the local hard drive.
For SVN, the command is this (when not using credentials):
"svn cat \"%Url%@%Revision%\" --non-interactive > \"%SRCSRVTRG%\""
Where we have specified Url as the path to the file in the repository and we have put the revision number of the file in the Revision field. Remember that all variables must be wrapped with the modulus symbol, and that you must copy files to SRCSRVTRG which will be a path to the output file.
You can, of course, refer to the source code in the SI_Subversion project for an implementation of this interface (The project is with the VSSourceIndexing source code.)
Part Three
Generating Minidumps
What’s the point of all these servers and all of that indexing if your just going to debug the latest version of your application based off of some vague bug reports? You can have an application attempt to write its own minidump on an unhandled exception by using the MiniDumpWriteDump function in the DbgHelp DLL found in the Debugging Tools for Windows. This applies to both native C++ applications as well as managed .NET applications. VS2010 provides much better support for mixed mode debugging of minidumps, which means you can use minidumps of manages applications without any extra effort. Unfortunately, I can’t go into too much detail of debugging managed minidumps as I don’t have a very large amount of experience with it. I can however tell you how to catch unhandled exceptions and create a usable minidump.
This next part applies to both Native and Managed code, the main function we are going to use to catch unhandled exceptions is SetUnhandledExceptionFilter which takes a pointer to a function that looks like this:
LONG WINAPI UnhandledExceptionFilter(__in struct _EXCEPTION_POINTERS *ExceptionInfo);
int UnhandledExceptionFilter(IntPtr exception_pointers);
When it is found that an unhandled exception has occurred, after searching for any explicit handlers, this function will be called and will be passed information about the exception. It’s this information that we need to generate a usable minidump. When setting your handler using SetUnhandledExceptionFilter, it returns a pointer to the previously set handler, if this pointer is not null, you are expected to invoke this function at the end of your handler. Windows only ever holds on to one handler and builds a chain of handlers by expecting each handler to call the previous.
The .NET Framework provides its own callbacks for unhandled exceptions, unfortunately sometimes when these are called. we still do not have the EXCEPTION_POINTERS structure usually because something threw a purely managed exception (via throw new NotImplementedException for example). Another drawback to these callbacks is that they will not be used for any access violation exceptions or any other potentially fatal errors. So we need to make sure that our UnhandledExceptionFilter is called instead. In the case of console applications, there is no problem, but for winforms applications, you will need to set the unhandled exception mode to this:
Application.SetUnhandledExceptionMode(UnhandledExceptionMode.ThrowException);
This will bypass the standard winforms exception handler (the one that throws the dialog which gives you the choice to try and continue or quit the application) and allow us to reach the native Win32 error handlers, which should call our exception handler and give us the EXCEPTION_POINTERS structure that we need for the minidump.
I would like to point out that this unhandled exception filter will be called AFTER the new “Application has crashed…” dialog that has been around since Vista, and that it will never be called for a Stack Overflow (it can’t, there is no stack left and the function needs to be called within the context of the thread that threw the exception), it will also not be called for some heap corruption errors. In both instances, the application will just close (unless there is a debugger attached of course).
Making the actual dump is simple:
[DllImport("kernel32.dll")]
static extern uint GetCurrentThreadId();
[DllImport("dbghelp.dll")]
public static extern bool MiniDumpWriteDump(IntPtr hProcess, uint ProcessId,
IntPtr hFile, MINIDUMP_TYPE DumpType,
IntPtr ExceptionParam, IntPtr UserStreamParam,
IntPtr CallbackParam);
FileStream fs = File.Create(@"D:\Minidump.dmp");
excInfo.ClientPointers = false;
excInfo.ThreadId = GetCurrentThreadId();
excInfo.ExceptionPointers = exception_pointers;
int size = Marshal.SizeOf(excInfo);
IntPtr exc = Marshal.AllocHGlobal(size);
Marshal.StructureToPtr(excInfo, exc, false);
MiniDumpWriteDump(Process.GetCurrentProcess().Handle, Process.GetCurrentProcess().Id,
fs.SafeFileHandle.DangerousGetHandle(), MINIDUMP_TYPE.MiniDumpNormal,
(excInfo.ExceptionPointers == IntPtr.Zero) ? IntPtr.Zero : exc, IntPtr.Zero, IntPtr.Zero);
fs.Close();
Marshal.FreeHGlobal(exc);
You may then want to start a new process to show a dialog to the user giving them options to Email or upload the minidump, it would be unwise to start opening new dialogs in the application without any knowledge of the error that has just occurred, even writing out the minidump may be taking a risk.
You can see an example of writing out a minidump in .NET by downloading the BrokenApplication project.
Links
Note: You will need the Visual Studio SDK to modify the Visual Studio extension itself, but not the plugins it uses.
Reference Material, some of these articles may expand on subjects I covered here:
Final Word
Well, I think that’s about everything I know on the subject. If you could leave any comments or suggestions so I can make any improvements, then I would greatly appreciate it.
I would also appreciate any contributions of other implementations for version control systems as I’ve only ever been exposed to SVN and don’t have any other version control systems installed.
History
- 04-10-2010: Article uploaded

