Introduction
Database creation and migration in Entity Framework can be a fairly simple task with a clean and well managed code-first implementation. Seeding the database with lookup and/or sample values, however, is usually as much a part of database stand-up and migration as is the creation of database objects. Entity Framework does not yet provide native tools for automating this important task. The simple solution offered here implements a model/service data access layer (DAL) and C# reflection to initialize a code-first-generated database with values from a JSON file. The same approach could be applied to other source formats; JSON is used for convenience and the availability of the excellent JSON.NET library from Newtonsoft.
Background
There are a few possible methods to follow when implementing the code-first approach in Entity Framework. Splitting code on the basis of model versus logic, such that entity classes are entirely separated from service classes, is a common practice. Many developers carry this practice further by implementing a repository pattern, thus removing any reference to the database from service classes.
While the approach presented here does make use of generic types and inheritance of both entities and services from abstract classes, it is not an implementation of the repository pattern. For most projects in Entity Framework, the repository pattern is at least partially redundant, because the Framework-provided DbContext class already gives us a separately-managed layer for directly connecting to and interacting with the database.
What's missing from the code-first approach in Entity Framework is an automatic way to reflect our model/entity classes from an external, static data source, such as JSON. The absence of such a utility can be particularly frustrating when trying to seed a database with values for lookup tables (especially with the practice of centralizing lookup values into a single table being increasingly frowned upon). Lookup tables comprise a major part of OLTP databases, and it is important to be able to port known values into those tables during development, and deploying migrations into production. This ability is crucial in a code-first scenario when, during development, it's not uncommon to tear-down and rebuild the database multiple times.
One quick-and-dirty solution is, of course, to separately iterate through each entity known to require seed values, and feed that entity values from either a known source, or directly hard-coded into a separate seed class. Personally, I find such a solution to be almost intolerable, due to its inflexibility, and the need to change code in (at least) two different places when changes are made to the model. For that reason I set about creating a solution to do the exact opposite: an automated initializer that would examine the contents of some source data, and instantiate entities in the model code base, from the corresponding structure of the data itself.
Using the code
There are a number of components involved in this example, but all are contained within a single Visual Studio solution. I'll show each of these files in relationship to a Visual Studio project, but first:
The JSON Source Data
Let's take a look at the foundation of the example, the source data as defined in the contents of a JSON-formatted file.
{
"EmployeeType": [
{
"Code": "EXEC",
"Name": "Executive",
"Description": "Members of the executive office (e.g. president, vice presidents)",
"Order": 1,
"SubordinateEmployeeTypes": [
{
"Code": "EXAT",
"Name": "Executive Assistant",
"Description": "Administrative specialists for executive staff",
"Order": 1
},
{
"Code": "DMNG",
"Name": "Departmental Manager",
"Description": "Top-level managers of departments",
"Order": 2,
"SubordinateEmployeeTypes": [
{
"Code": "MNGA",
"Name": "Managerial Assistant",
"Description": "Administrative specialists for departmental managers",
"Order": 1
},
{
"Code": "TMNG",
"Name": "Team Manager",
"Description": "Managers of personnel teams",
"Order": 2,
"SubordinateEmployeeTypes": [
{
"Code": "STLD",
"Name": "Staff Lead",
"Description": "Coordinators of smaller groups",
"Order": 1,
"SubordinateEmployeeTypes": [
{
"Code": "RSTF",
"Name": "Regular Staff",
"Description": "Regular staff positions",
"Order": 1
}
]
},
{
"Code": "TSPC",
"Name": "Team Specialist",
"Description": "Team-level technical specialist",
"Order": 2
}
]
},
{
"Code": "DSPC",
"Name": "Departmental Specialist",
"Description": "Departmental-level technical specialist who does not report to a team manager",
"Order": 3
}
]
}
]
}
],
"DivisionType": [
{
"Code": "DEPT",
"Name": "Department",
"Description": "The largest administrative unit within the organization, and basic unit of organization",
"Order": 1,
"ChildDivisionTypes": [
{
"Code": "UNIT",
"Name": "Unit",
"Description": "Smaller divisions within departments with large scope",
"Order": 1
},
{
"Code": "PROG",
"Name": "Program",
"Description": "Project-specific divisions set-up to achieve a particular goal",
"Order": 2
}
]
},
{
"Code": "OFFC",
"Name": "Office",
"Description": "Functionally-specific administrative offices",
"Order": 2
},
{
"Code": "SPRG",
"Name": "Special Program",
"Description": "Very high-level, special-purpose division",
"Order": 3
}
],
"Division": [
{
"Name": "Executive Office",
"Type_Id": { "Lookup": { "Service": "DivisionType", "Term": "OFFC" } }
},
{
"Name": "Accounting Office",
"Type_Id": { "Lookup": { "Service": "DivisionType", "Term": "OFFC" } }
},
{
"Name": "Widgets Department",
"Type_Id": { "Lookup": { "Service": "DivisionType", "Term": "DEPT" } },
"ChildDivisions": [
{
"Name": "Widget Production Unit",
"Type_Id": { "Lookup": { "Service": "DivisionType", "Term": "UNIT" } }
},
{
"Name": "Widget Quality Control Unit",
"Type_Id": { "Lookup": { "Service": "DivisionType", "Term": "UNIT" } }
},
{
"Name": "Widget Product Development Program",
"Type_Id": { "Lookup": { "Service": "DivisionType", "Term": "PROG" } }
}
]
},
{
"Name": "Special Research & Development Program",
"Type_Id": { "Lookup": { "Service": "DivisionType", "Term": "SPRG" } }
}
]
}
Take a close look at a couple key points within the file and notice:
It contains hierarchical data. The EmployeeType node, for example, is self-referencing, with a classic parent-child relationship, such that there is really only one root-level EmployeeType node in the whole file.
More importantly, there are special values for foreign key relationships. These special values appear where we want to reference an existing, already added value from another table (i.e., without adding a new value to that table), and we don't know the primary key value, and thus need to look it up. The special value looks like this:
"Type_Id": { "Lookup": { "Service": "DivisionType", "Term": "PROG" } }
This is merely made-up syntax, of course, but it's important, and will come into play later on, as we are reading the JSON data. All it says is that for the property Type_Id, we want to use the service class associated with the DivisionType entity, and lookup a primary key using the term PROG. This term should be a candidate or alternate key for the entity.
In my Visual Studio project, I've saved the JSON data file as a resource, under properties, and labeled it "Seed." The file could be referenced from anywhere, but storing it with the project is helpful. If you don't know how to do this: in your VS project Properties, select the Resources tab (if you don't already have a Resources.resx file in your project, you'll have the option to create one). Set the type selector to "File" and then add your JSON file. Once added, I recommend setting the file type to text rather than binary (which is the default). This example, as implemented, requires that it be set as text.
The Visual Studio Project
Speaking of the VS Project, let's take a quick look at its structure. You may, of course, implement the overall solution however desired, but some explanation here as to how my project is organized may be helpful. As mentioned, I use a simple model/service architecture for the data access layer (DAL) of my solution. I contain all elements of the DAL in a separate, stand-alone project, which I call API. In this project I have my entity classes, and their associated business logic (service) classes, separated into folders. I also have a Migrations folder, to contain the automatically-generated migration instance class files, and a Resources folder, which in this project contains the Seed.json file and nothing else. Additionally, my migration configuration file and database context files reside directly under the project. The whole thing looks like this in Solution Explorer:
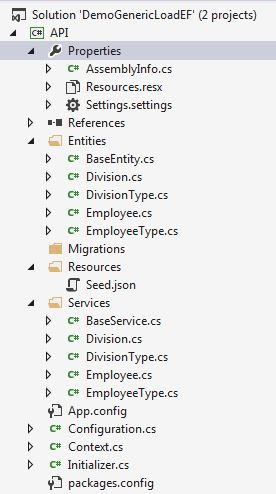
A quick word here on naming conventions -- yes, I give my model and related service entities the exact same name, but place them in different namespaces. I've gotten used to this convention and like it. To me it makes things more clear, rather than less so. This aspect of the model can obviously be changed to suit taste. One reason I like it this way, particularly for the example presented in this article, I don't have to worry about mapping names from my seed data source to my service versus entity classes. It's all automatic, because the names are always identical across the database, datasets, entity classes, and service classes. These all exist in their own, independent namespaces, so it's all fine.
Resources & Settings
It's important to note that my project contains resources and settings files. As already mentioned, I like to save the JSON source data as a resource file. Additionally, there are a few constant values that I like to hold as either resource values or settings, also. It's not necessary to do it this way. I'm the sort of developer that will go to great lengths, however, to avoid compiling real-world values into my codebase. Thus, I have resources defined like this:

And settings like this:
Entities
Next, let's have a look at the entities. I've created four, here, for the sake of simplicity and clarity, showing a simple employee/organization structure: Employee.cs, EmployeeType.cs, Division.cs, and DivisionType.cs. In a separate BaseEntity.cs file, I've created an interface and a couple abstract classes for these to inherit from. Let's look first at Entities.BaseEntity.cs:
namespace API.Entities
{
public interface IEntity
{
int Id { get; set; }
}
public abstract class BaseEntity
{
public int Id { get; set; }
}
public abstract class TypeEntity : BaseEntity
{
public string Code { get; set; }
public string Name { get; set; }
public string Description { get; set; }
public int? Order { get; set; }
}
}
Obviously very straight-forward, for this particular example. There is a single interface which requires that all entities implement an Id property, a base entity which provides that implementation, and a "type" entity which extends base entity. Now let's look at one of our type entities, Entities.DivisionType.cs:
using System.Collections.Generic;
using System.ComponentModel.DataAnnotations.Schema;
namespace API.Entities
{
public class DivisionType : TypeEntity
{
public int? ParentDivisionType_Id { get; set; }
[ForeignKey("ParentDivisionType_Id")]
public virtual DivisionType ParentDivisionType { get; set; }
public virtual ICollection<DivisionType> ChildDivisionTypes { get; set; }
}
}
DivisionType is an instance of the abstract TypeEntity, and adds-on a hierarchical structure for parent-child relationships.
And here is the associated entity Entities.Division.cs:
using System;
using System.Collections.Generic;
using System.ComponentModel.DataAnnotations.Schema;
namespace API.Entities
{
public class Division : BaseEntity
{
public string Name { get; set; }
public DateTime? InceptionDate { get; set; }
public int? Type_Id { get; set; }
[ForeignKey("Type_Id")]
public virtual DivisionType Type { get; set; }
public int? ParentDivision_Id { get; set; }
[ForeignKey("ParentDivision_Id")]
public virtual Division ParentDivision { get; set; }
public virtual ICollection<Division> ChildDivisions { get; set; }
public int? Manager_Id { get; set; }
[ForeignKey("Manager_Id")]
public virtual Employee Manager { get; set; }
public virtual ICollection<Employee> Employees { get; set; }
}
}
Now let's turn our attention to the service classes, which contain the logic for operating on these model/entity classes, to ultimately make our transactions against the database.
Services
First, we have Services.BaseService.cs:
using Newtonsoft.Json.Linq;
using System;
using System.Collections.Generic;
using System.Data.Entity;
using System.Linq;
namespace API.Services
{
public static class Service
{
public static dynamic InstanceOf(string Name)
{
Type TypeOfInstance = Type.GetType(typeof(Service).Namespace + "." + Name);
return TypeOfInstance != null ? Activator.CreateInstance(TypeOfInstance) : null;
}
}
public interface IService<T>
where T : Entities.BaseEntity, new()
{
T Fetch(int Id);
void Create(T Item);
IEnumerable<T> All();
}
public abstract class BaseService<T> : IService<T>
where T : Entities.BaseEntity, new()
{
public T Fetch(int Id)
{
using (var Db = new Context())
{
return Db.Set<T>().Find(Id);
}
}
public void Create(T Item)
{
if (Item != null)
{
using (var Db = new Context())
{
DbSet Entity = Db.Set<T>();
Entity.Add(Item);
Db.SaveChanges();
}
}
}
public void Create(JToken Item)
{
Create(Item.ToObject<T>());
}
public IEnumerable<T> All()
{
using (var Db = new Context())
{
return (IEnumerable<T>)Db.Set<T>().ToList();
}
}
}
public abstract class TypeService<T> : BaseService<T>
where T : Entities.TypeEntity, new()
{
public int? Lookup(string Term)
{
if (String.IsNullOrEmpty(Term))
{
return null;
}
using (var Db = new Context())
{
return Db.Set<T>().Where(t =>
t.Code == Term ||
t.Name == Term ||
t.Description == Term
)
.Select(t => t.Id)
.FirstOrDefault();
}
}
}
}
Note, firstly, that this class implements generic type parameters, and these refer back to the BaseEntity. So, for each instantiation of a service class, we'll automatically have the correct, corresponding entity to work with.
A couple other things to note:
The Create method is overloaded, such that one version accepts a parameter of JToken, which is a type included in the JSON.NET library (which needs to be added to your project via NuGet). Additionally, the Item argument of the Create method may, of course, be a complex object graph. Entity Framework's DbContext takes care of these graphs automatically, conveniently adding dependent entities in branches of the object hierarchy. This is, specifically, why we can't add our lookup values by defining the entity we want at each foreign key node in the source data. If we did that, we'd get duplicate records.
Services which inherit from TypeService are given a method called Lookup, which returns the primary key (Id) of an entity instance, given a search term as parameter. This is how we can manage to seed the database in one shot, from a single file, without knowing the primary keys of our types, in advance. The only stipulation here, of course, is that values being looked-up have already been created (added to the database). The order of elements in the JSON file, therefore, is obviously of significant importantance. (Side note: it should be possible, of course, to modify the example, here, such that dependencies were found first, and the data properly ordered. For the sake of simplicity, however, we are relying on the JSON file being properly ordered.)
Finally, note that there is a static class, Service, which simply dispatches an instance of a given service, using reflection, by name (string). This same task could be accomplished in calling code, but it's convenient and tidy to have it in the BaseService.cs file.
In this example, the individual service classes are empty. Here's Services.EmployeeType.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace API.Services
{
public class EmployeeType : TypeService<Entities.EmployeeType>
{
}
}
Our EmployeeType service doesn't need to do anything beyond what the abstract TypeService defines. It exists in this case merely to pass-in Entities.EmployeeType as the type parameter.
Now let's take a look at our DbContext.
The Database Context (DbContext)
I have my database context for the project in a file called Context.cs. It includes an OnModelCreating method, and also a method called Initialize. The Initialize method is there to get an instance of the Initializer class, and call its Load method. (Side note, I passionately dislike the appearance of a switch block here, but for the sake of simplicity it makes sense. In this case it really does nothing, because we only have one supported source for seed data: JSON. The switch block is there to accommodate future expansion.)
using API.Entities;
using Newtonsoft.Json.Linq;
using System;
using System.Data.Entity;
using System.Data.Entity.ModelConfiguration.Conventions;
using System.Linq;
namespace API
{
public class Context : DbContext
{
DbSet<Division> Division { get; set; }
DbSet<DivisionType> DivisionType { get; set; }
DbSet<Employee> Employee { get; set; }
DbSet<EmployeeType> EmployeeType { get; set; }
protected override void OnModelCreating(DbModelBuilder Builder)
{
Builder.Conventions.Remove<PluralizingTableNameConvention>();
base.OnModelCreating(Builder);
}
public void Initialize(string SeedMethod = null)
{
if (String.IsNullOrEmpty(SeedMethod))
{
SeedMethod = Properties.Settings.Default.SeedMethod;
}
Initializer Initializer = null;
if (Initializer.MethodsAvailable.Contains(SeedMethod))
{
switch (SeedMethod)
{
case Initializer.SEED_METHOD_JSON:
Initializer = new Initializer(JObject.Parse(Properties.Resources.SeedData));
break;
}
}
if (Initializer != null)
{
Initializer.Load();
}
}
}
}
The Initialize method is automatically called through the Seed method of the configuration class, when database migrations occur. It can also be called on demand, however, by other code. (For testing and other purposes, I find it handy to create a console application project within the same solution, which can be used to manually call-up various functions.)
From there, we have some classes in an Initializer.cs file:
using Newtonsoft.Json.Linq;
using System.Collections.Generic;
using System.Linq;
namespace API
{
public interface IInitializer
{
void Load();
}
public class Initializer
{
private IInitializer Instance;
public const string SEED_METHOD_JSON = "JSON";
public static readonly string[] MethodsAvailable = {
SEED_METHOD_JSON
};
public Initializer(JObject Source)
{
Instance = new JsonInitializer(Source);
}
public void Load()
{
Instance.Load();
}
}
internal class JsonInitializer : IInitializer
{
private JObject Source;
internal JsonInitializer(JObject Source)
{
this.Source = Source;
}
public void Load()
{
foreach (var JsonEntity in Source)
{
JObject EntityJObject = JObject.FromObject(JsonEntity);
List<JToken> Lookups = EntityJObject.SelectTokens(
Properties.Resources.JsonSeedLookupSelector
).ToList();
foreach (var LookupItem in Lookups)
{
dynamic LookupService = Services.Service.InstanceOf(
LookupItem[Properties.Resources.JsonSeedLookupKeyService].ToString()
);
if (LookupService != null)
{
LookupItem.Parent.Parent.Replace(
JToken.FromObject(
LookupService.Lookup(
LookupItem[Properties.Resources.JsonSeedLookupKeyTerm].ToString()
)
)
);
}
}
dynamic EntityService = Services.Service.InstanceOf(JsonEntity.Key.ToString());
foreach (var EntityData in EntityJObject)
{
foreach (var Item in EntityData.Value)
{
EntityService.Create(Item);
}
}
}
}
}
}
In Action
The Load method embarks on a loop, adding entity instances to the databse, as they are found in the source. The key point to zero-in on, in terms of how the JSON nodes are used to create instances of the service classes is this line:
dynamic EntityService = Services.Service.InstanceOf(JsonEntity.Key.ToString());
Here we use the InstanceOf method in the static Service class to return a specific instance of a service object to the dynamic variable EntityService. The instance is obtained via reflection, in the InstanceOf method using Activator:
Type TypeOfInstance = Type.GetType(typeof(Service).Namespace + "." + Name);
return TypeOfInstance != null ? Activator.CreateInstance(TypeOfInstance) : null;
By instantiating a specific service class, we also have the type of the associated entity, because each specific service class uses a generic type parameter.
From there, it would be a simple enough matter to pass each JToken item off to the Create method of the service object, for serialization to an entity object and, ultimately, adding to the database. To accomplish the task of looking-up foreign keys, however, we have to do some minimal manipulation of the JSON data -- and this is where the made-up syntax, mentioned earlier, comes into play. For each of the main JToken entities in the file, we perform a select for other tokens labeled "Lookup." Each of these tokens, in turn, contains yet another token holding the name of the service entity to instantiate, and the term to be used for looking up the desired key. The lookup token is then replaced with the resultant value, before the grandparent level token is then passed on for adding to the database.
Making It Automatic
As briefly mentioned earlier, the Initialize method can be called automatically when the database is created or updated by Entity Framework migrations. This is done by setting-up the Configuration.cs file as follows:
using System.Data.Entity.Migrations;
namespace API
{
public class DemoConfiguration : DbMigrationsConfiguration<DemoContext>
{
public DemoConfiguration()
{
AutomaticMigrationsEnabled = false;
MigrationsDirectory = @"Migrations";
}
protected override void Seed(DemoContext context)
{
base.Seed(context);
context.Initialize();
}
}
}
We simply override the Seed method of the EF-native DBMigrationsConfiguration class, such that it calls our Initialize method.
Points of Interest
Suffice it to say that I arrived at this particular solution through a rather difficult and frustrating path taken to come-up with a data access layer model that accomplished two goals:
- Gave me sufficient abstraction and generalization, in a tidy and readily understandable structure, without having to realize a full implementation of the repository pattern.
- Allowed me to quickly and easily load my database with initialization values from an external source without having to touch any other code, after model changes.
That second point was that of greatest interest to me, for a number of reasons. I had been working on a project, for which I need to be able to iteratively stand-up and tear-down development versions of the database, including a large set of initial values for dozens of lookup tables. I wanted the flexibility to be able to modify my model without having to make huge changes to the source for the lookup tables, and without having to touch any intermediate code. The solution I've presented here allows that to happen. The source data and the DAL classes are loosely coupled, such that those are the only two components that need to be modified in order for the structure to work. There's nothing else "in between" that needs altering.
It's likely that one could take the approach a step further, implementing a system whereby there isn't necessarily a one-to-one relationship between top-level nodes in the JSON source, and service/entity classes in the DAL. I.e., there could be some sort of interface schema between the JSON source and the DAL, which would inform the DAL how to handle data from the source. So, for instance, if you decided that employee types belonged to two different entities, rather than one, you could change that in the DAL and the schema, without touching the JSON source.
Regarding my methods for performing the lookup/replace functionality for the JSON data, I'm sure that there are likely JSON.NET wizards out there who could accomplish the same task more efficiently, with less overall code.
History
This is the second, long version of the article. I've broken-out Initializer into it's own class, separate from the Context class.

