Introduction
Every professional C++ programmer knows about the complexity levels of C++ programs, about the deeply buried bugs in code and difficult approach to find and resolve them. Even after compiling the code with highest warning levels, few bugs remain persistent in code. Thus, the need for a tool that can analyze the code in heuristic manner, i.e. by intelligently looking at surrounding code to find potential bugs, becomes indispensable.
While there are umpteen numbers of free and paid tools available for the Code Analysis, for different platforms and compilers, I would elucidate the Code Analysis feature that is available with Visual Studio 2005/2008/2010. Unfortunately, this feature is only available on Team System, and ultimate versions of Visual Studio.
This article is broadly divided into three logical categories, as listed below.
Sample code and few screen shots would be given as we move further, thus reader must understand the code carefully. The following Visual Studio versions have been used, there are some inconsistencies between them, that I would list as they come into discussion.
- Visual Studio 2005 SP1 - Team Suite, with Vista Update.
- Visual Studio 2008 - Team System, RTM
- Visual Studio 2010 Ultimate
Let's have a slightly buggy code that can be easily detected by human, the standard compiler (hence forth, only compiler), and by the Code Analysis tool.
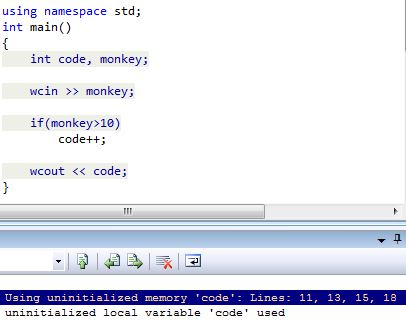
using namespace std;
int main()
{
int code, monkey;
wcin >> monkey;
if(monkey>10)
code++;
wcout << code;
}
Yes, the variable 'code' which can remain uninitialized. The compiler would emit C4700 for this. It is easy and can be corrected easily.
Before I give some good example, that cannot be detected by compiler, let me compile the same code with Code Analysis enabled. For this you need to supply /analyze option to the compiler in Command Line. But wait, there is easy approach to do the same. In your project properties, find a node named Code Analysis, locate General, and enable Enable Code Analysis for C/C+ +. Doing this will put /analyze switch in compiler options.
Now, when you compile the same code, it will show warning C6001, along with standard C4700:
warning C6001: Using uninitialized memory 'code': Lines: 11, 13, 15, 18
All Code Analysis warning would be in range C6001 and C6999. If you have noticed, the CA warning also shows up set of line numbers, showing you the possible bug area. Since this one is simple, you may not quite appreciate it, but it becomes really useful with other set of CA warnings.
Interestingly, when you double click the warning, the IDE would show your code stuff like this:
Notice that the relevant code is grayed out. These are the same line numbers shown in warning.
Let's have another example where you would start appreciating CA. See this code:
int a=10, b=33;
int sum;
sum = a+b;
printf("Addition of %d, %d is %d", a,b);
The compiler will not show any warning, but when you enable CA, it would raise following warning:
warning C6064: Missing integer argument to 'printf' that corresponds
to conversion specifier '3'
These two code examples were just for introduction. Code Analysis can detect more potential coding mistakes. These include, buffer overruns, not meeting with function's in/out requirement, pointer arithmetic mistakes, improper usage of operators and other potential bugs. Therefore, I classify them into following groups:
One last category of Code Analysis warning is with Code Analysis construct itself, which I would explore later in this article.
This section will now list out all possible bugs that can be detected by Code Analysis tool of Visual C++. The order of grouping (as shown above), is not constrained with less error-prone or more-error prone. I am ordering them in my own way, which is for reader's convenience.
These type of mistakes can be very easy to find, and can be extremely difficult to locate. Also, the impact of these mistakes may not affect the software system at all, or may put the entire software system down, may cause random/frequent crashes. More importantly, these mistakes would do something else, other than the programmer intended it - thus creating a hard to find Logical Bug in the system! Thus, in my opinion, these type of coding errors must be sorted out as soon as possible.
Let's get started with first example:
#define DIRECTORY 1
#define READONLY 2
#define SHARED 4
void FileOperation(int nFileFlag)
{
if (nFileFlag || SHARED)
{
printf("Shared file");
}
}
Which clearly is a potential bug, since the code above doesn't correctly check the file mask. The file-flag must be compared with bitwise AND operator. This code, along with other standard warnings, produces following CA warning:
warning C6236: (<expression> || <non-zero constant>) is always a non-zero constant
Since it is also followed by warning:
warning C4127: conditional expression is constant
You can quickly find and correct it - even before commencing a CA compilation! Thus you change it as:
if (nFileFlag & SHARED )
And, if you mistakenly typed:
if (nFileFlag & SHARED != 0)
Which is a potential bug, since it compares SHARED with zero, which would be true (1). Thus, nFileFlag would always be bitwise AND compared to 1. This buggy code produces following warnings:
warning C4554: '&' : check operator precedence for possible error;
use parentheses to clarify precedence
warning C6281: Incorrect order of operations:
relational operators have higher precedence than bitwise operators
warning C6326: Potential comparison of a constant with another constant
The correction would just need parenthesis at correct place:
if ( (nFileFlag & SHARED) != 0)
You see that there are set of warnings related to comparison with constants. The constant in an expression may be on left, on right or on both sides. Following are set of examples, and different warnings that occur with constants.
void Check(int nValue)
{
if (nValue=55)
{
printf("It is 55!");
}
}
Which produces CA warning:
warning C6282: Incorrect operator: assignment of constant in Boolean context.
Consider using '==' instead
Following code produces warnings as commented:
if ( 10 && nValue>20 ) {}
if ( 10 || nValue>20 ) {}
And there are other similar warnings in same arena. Few other warnings I found interesting, which are expressed below.
if (nValue == 10 && nValue == 20)
if (nValue != 10 || nValue != 20)
For above type of warnings you need to carefully understand the requirement, and change the conditional expression appropriately.
Few of the warnings may also result due to precedence of operators, and programmer must carefully specify the intent using parenthesis. Examples are:
Pointers! One of the most dangerous yet powerful construct in the language. Even with careful coding some bugs may peep in when you use pointers in C/C++. Let's start with a very simply code that would lead to crash:
int *pDangling = NULL;
int n;
cin>>n;
if(n>0)
pDangling = new int[n];
*pDangling = n;
I won't insult your intelligence by explaining what the code does, and why it may crash. The compiler will not give you any warning for this code, since the variable pDangling is initialized, before it is used. The CA would however report warning C6011:
warning C6011: Dereferencing NULL pointer 'pDangling': Lines: 148, 149, 151, 153, 156
When you double click this warning, it will shade the code path that leads to this warning. Since this is very simple code, it is trivial to understand and fix. To fix this type of warning, you either need to check if pointer is null before accessing, or do return (or change code execution path). Changing the code path may not always avoid the warning, depending on the compilation, code analysis and code optimizations performed.
The same warning may also occur when you use memory allocation functions. For example if you allocate memory using malloc:
pDangling = (int*)malloc(10);
Since, malloc may return null if it fails to allocate memory, and you might use a bad pointer. By C++ standard the operator new will not return null, but would throw exception if it fails to allocate memory. Further, other memory allocation routines like HeapAlloc will not give this warning. The malloc and related functions are prototyped such a way, so that you can see these warnings. We will look how it is done, when I would elaborate on "Making your code Analyzable", later.
Another bug in this category would be using ++ or -- operator with a pointer's pointed content. For example:
void test(const char* pBuffer, char x)
{
if(isalnum(x))
*pBuffer++;
}
Here, it should be clarified if the buffer movement (i.e. pointer increment) is required or incrementing what is being pointed. The code above produces following warning:
warning C6269: Possibly incorrect order of operations: dereference ignored
The compiler has ignored the dereference (
*pBuffer). If this is the intent, the code should be changed as:
pBuffer++;
If the
++ operator is to be applied to what is pointed, the code should be:
(*pBuffer)++;
With memory allocation using
new and releasing with
delete, the following bug may creep in:
char*pBuffer= new char[10];
delete pBuffer;
float *pFloat = new float;
delete []pFloat;
Which is reported by CA compiler as:
warning C6279: 'pFloat' is allocated with scalar new, but deleted with array delete []
warning C6283: 'pBuffer' is allocated with array new [], but deleted with scalar delete
And I obviously need not to tell you what is to be done!
If array allocation is done for a class/struct, and deleted with scalar delete, the warning is somewhat different:
class T {};
T* pT = new T[10];
delete pT;
'pT' is allocated with array new [], but deleted with scalar delete.
Destructors will not be called: Lines: 159, 160
On similar lines, the following code would produce warning C6280, since allocation and deallocation routines differ. It is important to note that new/delete, malloc/calloc etc, Windows heap functions; all use different heaps and asking other heap manager to deallocate memory would definitely do something fatal.
void* pMemory1 = new char[100];
free(pMemory1);
void* pMemory2 = new char[100];
LocalFree(pMemory2);
void* pMemory3 = malloc(100);
delete pMemory3;
void* pMemory4 = malloc(100);
LocalFree(pMemory4);
void* pMemory5 = LocalAlloc(0, 100);
free(pMemory5);
And the reported warnings are:
warning C6280: 'pMemory1' is allocated with 'new []', but deleted with 'free'
warning C6280: 'pMemory2' is allocated with 'new []', but deleted with 'LocalFree'
warning C6280: 'pMemory3' is allocated with 'malloc', but deleted with 'delete'
warning C6280: 'pMemory4' is allocated with 'malloc', but deleted with 'LocalFree'
warning C6280: 'pMemory5' is allocated with 'LocalAlloc', but deleted with 'free'
Lastly, I list few potential bug areas related to pointer arithmetic. Let's have a structure:
struct Packet
{
short Age;
char Name[32];
};
This object arrives on network, packed in series of bytes (
char* or
BYTE*) - the first four bytes are the length of packet, and then the packet (
Packet). You attempt to typecast to that packet adding four bytes. The code would help understand:
void process(const char* pNetworkPacket)
{
int nLen;
nLen = *(int*)pNetworkPacket;
Packet* packet;
packet = (Packet*)pNetworkPacket + sizeof(int);
}
Here, from pNetworkPacket, which is just a byte-buffer, an attempt is made to read actual packet shifting four bytes from base. Since the size of Packet is 34 bytes, the expression on last line is actually asking for fifth Packet from a presumably wrong Packet-array! Thus, the expression would attempt to read from 137th byte, instead of 5th byte!
On compiling above code with CA enabled, the compiler produces warning C6305:
Potential mismatch between sizeof and countof quantities: Lines: 76, 77, 80, 81
And the simple and correct solution is to make expression as below:
packet = (Packet*)(pNetworkPacket + sizeof(int));
Similarly, in an inverse mode, the network packet itself arrives in some structure. And multiple packets may arrive, thus you may need to typecast something like:
struct NetPacket
{
int Length;
char Buffer[100];
};
void func4(const void* packet)
{
int* pnLen;
pnLen = (int*)(NetPacket*)packet+4;
}
Where you actually attempt to get length from fifth packet, but wrongly reading 5th byte! The last line, would cause following warning:
warning C6268: Incorrect order of operations: (<TYPE1>)(<TYPE2>)x + y. Parentheses in
(<TYPE1>)((<TYPE2>)x + y) might be missing
And this can be corrected by placing parenthesis at proper locations:
nLen = (int*) ( (NetPacket*)packet+4 );
For generating strings, there exists a set of classes, with overloaded operators, and related techniques; nevertheless, printf-functions like sprintf, CString::Format etc are widely used for their simplicity and consistency among functions. With secure versions like sprintf_s, you can avert most of potential bugs. Let me not debate over string-formatting, and other templatized string generation; but list out issues with it. This subsection is about the format-string only, but the same set of functions can have following concerns:
- Secure versions suffixed with
_s should be used to avoid Buffer Overruns. Other than runtime checking, which is available always, and their ASSERTive nature in Debug builds; the CA tool can also list out mismatch between buffer-size and buffer specified. Buffer overrun issues are pointed out in next subsection. - Incorrect specification of argument-specifier, missing or extra arguments can have adverse effects and can crash the program. Code Analysis can point them out. This subsection enlightens this.
- Since Format-string construct is consistent, it applies to all functions that take format-strings. Thus, you may also prototype your own functions, that take format-string and variable number arguments, to be analyzable by Code Analysis tool. We will lookup into next section.
Let's start with an example.
int a=10, b=20;
printf("Sum of %d and %d is: %d", a,b);
Here you ask printf to print three numeric values using %d specifiers. But you miss to pass third argument. It compiles well even with highest warning level, but may crash at runtime! A CA compilation would help you detect this bug:
C6064: Missing integer argument to 'printf' that corresponds to conversion specifier '3'
And you can straightway remove this bug. On the similar line, following code would also produce CA warning C6064:
char sBuffer[100];
sprintf(sBuffer, "A is %d, B is %d", a);
It should be understood that the program may not crash, but would give unpredictable results. And the results shown/produced by printX functions depends on what is on call stack. It could be nearby local variable or same or another type, the address of function of call-stack or anything else. Compiler optimizations can also make things worse. Thus, it is better to enable CA, remove all warnings, before giving the Release Build.
Let's have few more examples.
char name[]="CodeProject";
printf("First letter is %c",name);
Which asks to print first character of name array, fails to pass it properly. This, CA would raise warning:
warning C6274: Non-character passed as parameter '2' when character is
required in call to 'printf'
Which would possibly won't cause any serious effect or program crash. But the following can do!
int nLen = strlen(name);
printf("%s (%d)", nLen, name);
And this mistyped code would produce following CA warnings:
warning C6067: Parameter '2' in call to 'printf' must be the address
of the string
warning C6273: Non-integer passed as parameter '3' when integer is required in call
to 'printf': if a pointer value is being passed, %p should be used
When you use CString::Format function, which is designed for Code Analysis, only VS2008 (Team System) has omitted warnings for all cases that would arrive for printX functions. I could not figure out why it does not give warnings in VS2005 and VS2008. Code example:
CString s;
s.Format("%d, %d", 100);
Which gives (only in VS2008):
warning C6064: Missing integer argument to 'ATL::CStringT<..><char,... />::Format'
that corresponds to conversion specifier '2'</char,... />
For C/C++ programs and programmers, buffer overflow is one of the most disastrous bug. It takes lot of time, effort and thorough understanding of data structures used, to locate and correct the bug. But it takes more than that to actually find potentially fatal bug, before it appears. And the appearance of bug could be random/regular crashes of program, incorrect storage and retrieval of data, cascaded logical bugs, and allowing external programs to easily attack your system through those holes.
Unfortunately, locating and fixing buffer overrun using free tools isn't productive, especially for medium or large program. The paid tools are too costly. Nevertheless, they need some time to get used to these tools (free or not). The Code Analysis feature of Visual C++ is not very effective tool to find the buffer overrun bugs, but it can greatly help to find the bugs.
As I already mentioned in previous section that secure versions of functions suffixed with _s should be used to avoid Buffer Overruns. The secure versions help you to find potential bugs at runtime through infamous "Debug Assertion Failed" dialog box in Debug build, if you pass more element/byte count for a buffer/string which is actually lesser than that count.
First let me exemplify the buffer-overrun issues with normal code and non-secure functions.
A naive bug:
int Array[4];
Array[4]=10;
Which produces following CA warnings:
warning C6201: Index '4' is out of valid index range '0' to '3' for possibly stack
allocated buffer 'Array'
warning C6386: Buffer overrun: accessing 'Array', the writable size is '16' bytes,
but '20' bytes might be written: Lines: 234, 236
And most commonly, it may arrive along with for-loop:
for(int nIndex = 0; nIndex <= 4; ++nIndex)
Array[nIndex] = nIndex * 10;
And it requires minimal change, you know that! As long as index itself is a compile-time constant, or can be deduced from a constant, the CA would help you. Thus, if you change above' code as:
const int ARRSIZE = 4;
int Array[ARRSIZE];
for(int nIndex = 0; nIndex <= ARRSIZE; ++nIndex)
Array[nIndex] = nIndex * 10;
Array[ARRSIZE] = 10;
And the code above would producesame set of warnings. Unfortunately, following won't:
int nIndex = 4;
Array[nIndex] = 100;
Though the compiler knows the value of nIndex, on second line, and compiler might optimize it and put constant 4 instead of variable, eliminating variable itself. The CA would not tell you of this bug!
If the array is declared static or global, the warning C6200 is produced instead, which is similar to C6201:
void BufferOverrun()
{
static int Array[4];
Array[4] = 100;
}
warning C6200: Index '4' is out of valid index range '0' to '3' for non-stack buffer
'int * Array'
When you allocate an array dynamically, the CA would also help you. Example code:
char* pBuffer = new char[15];
pBuffer[20]='#';
int* pArray = new int[10];
pArray[12]=144;
Which is clearly a buffer-overrun bug, would produce following set of warnings:
warning C6386: Buffer overrun: accessing 'pBuffer', the writable size is '15*1' bytes,
but '21' bytes might be written: Lines: 55, 56
warning C6211: Leaking memory 'pBuffer' due to an exception.
Consider using a local catch block to clean up memory: Lines:
warning C6386: Buffer overrun: accessing 'pArray', the writable size is '10*4' bytes,
but '52' bytes might be written: Lines:58, 59
And you can see the smart CA shows valuable warning messages. I would briefly cover the second warning (C6211).
Similarly, if you had used malloc, or other CRT memory allocation function:
int* pArray = (int*)malloc(16);
pArray[4] = 16;
pArray[16] = 256;
Following useful set of warnings would emit (do I need to tell why?):
warning C6200: Index '4' is out of valid index range '0' to '3' for non-stack buffer 'pArray'
warning C6200: Index '16' is out of valid index range '0' to '3' for non-stack buffer 'pArray'
warning C6386: Buffer overrun: accessing 'pArray', the writable size is '16' bytes,
but '20' bytes might be written: Lines: 58, 59
warning C6011: Dereferencing NULL pointer 'pArray': Lines: 58, 59
For now, first three warnings are important. As you can see the CA tools reports you the correct byte/element count even for a function. Even if you use other memory allocation function like HeapAlloc, LocalAlloc:
int* pArray = (int*)HeapAlloc(GetProcessHeap(), 0, 16);
pArray[4] = 16;
int* pArray = (int*)LocalAlloc(LMEM_MOVEABLE, 10);
pArray[4] = 16;
The warning depends on how these different functions are prototyped for CA, which I would explain in next section. But the idea is same: to tell you the potential buffer overflow bugs.
Other than direct usage of buffers, Code Analysis can also assist you in finding bugs when you pass those buffers to functions. For example:
BYTE Buffer[100];
memset(Buffer,0, 120);
Which would produce following CA result:
warning C6202: Buffer overrun for 'Buffer', which is possibly stack allocated,
in call to 'memset': length '120' exceeds buffer size '100'
Even if array is allocated on heap, Code Analysis would also produce warning. For example, in following code, programmer has mistakenly passed incorrect parameters to memset, which is detected by CA:
int* pBuffer = new int[100];
memset(pBuffer, 100, 1000);
Let's do some memory copying:
char src[8], dest[10];
memcpy(dest, src, 20);
And this code raises following warnings:
warning C6202: Buffer overrun for 'dest', which is possibly stack allocated,
in call to 'memcpy': length '20' exceeds buffer size '10'
warning C6202: Buffer overrun for 'src', which is possibly stack allocated,
in call to 'memcpy': length '20' exceeds buffer size '8'
Which clearly says that element size is checked for both buffers. When 20 is changed to 10, to specify the number of actual bytes to copy to destination buffer, the source buffer is still insufficient to satisfy the need. Two incorrect bytes might be written to destination. Thus, second warning would remain (which complains about 8 bytes).
Even if you use memset_s, you must specify size of buffer which is smaller amongst source and destination, or make sure both are sufficient enough for reading/writing.
Similar to warnings on memset, for dynamically allocated buffers, CA compilation would also point out warnings for memcpy:
int *src, *dest;
src = new int[10];
dest = new int[8];
memcpy(dest, src, 100);
In different cases, the actual warning are somewhat different, by they all convey the same meaning.
Every C and C++ programmer know what a C string is: A set of characters followed by a null character. And the null character is nothing but a value zero, often represented by NULL macro. Well, I am not here to advocate about C strings, where classes like std::string, CString, and other classes from different libraries exist. The native C strings do play important role in C/C++ programs, and they do exist in code where performance is important. Okay, you win, C strings are evil and do not use them! But I must cover this course of discussion.
Now the problem! As you are aware of it: What if the string is not properly null terminated? Well, probably, you know the answer also: The function will attempt to read the string till the value zero is encountered, and would read incorrect data. The read attempt may go beyond the call-stack, and probably corrupt the stack, and may shut down the process abruptly - if the string is on stack. If the string is stored on heap, the null-termination search may corrupt/over-read the relevant heap.
With functions like strcpy, if source string is invalid, or its content is larger than destination string, it would corrupt the stack/heap - and you know why! To overcome these fatal activities, it is recommended that you use secure versions that are, normally, suffixed with _s. In this course of discussion, I would cover both versions of string functions.
Let's start with examples.
char str[10];
strncpy(str, "AB",2);
int nLen = strlen(str);
Remember that strncpy will not put the null character at end, if number of characters specified is not more than source string. Therefore, the prototype of strncpy is such that it says it will not return null terminated string. In next section, I would explicate what this prototyping. The code above' would produce following CA warning, along with other standard warnings:
warning C6053: Call to 'strncpy' might not zero-terminate string 'str': Lines: ...
To avoid this warning and the potential bug, you can put null terminated character at desired location as:
strncpy(str, "AB",2);
str[2]=0;
Or as:
char* pLoc;
pLoc = strncpy(str, "AB",2);
str[pLoc-str]=0;
And I recommend using secure version:
strncpy_s(str, 10,"AB",2);
strncpy is mostly used to control how many characters should be copied, and it used over strcpy. The string is zero-filled before using it, or is null terminated explicitly after copy operation. Most of the time, you can ingore all this, and striaghtaway use strcpy_s, which would read/write only upto specified character count.
strcpy_s(str, 10,"AB");
In my opinion these kinds of bugs are rare, and would happen if you are coding in haste; may be when your brainbox isn't responding for a good logic, or your boss is over your shoulder and you are required to complete it ASAP. This category doesn't need more of discussion, only few of code examples would suffice.
Example:
for(int nIndex=10; nIndex<0; nIndex--)
{}
For sure, you can find the bug that quick when you look at this code, but not when it is emdedded somewhere. The CA would help you out:
warning C6294: Ill-defined for-loop: initial condition does not satisfy test.
Loop body not executed
And you just need a one character change:
for(int nIndex=10; nIndex > 0; nIndex--)
{}
Similar kind of bug:
char szName[] = "CodeProject";
for(int nIndex= strlen(szName) - 1;
nIndex >= 0; nIndex++)
{
printf("%c", szName[nIndex]);
}
And this code raises two warnings, first one is for Ill-defined loop, and other is already discussed.
warning C6292: Ill-defined for-loop: counts up from maximum
warning C6201: Index '2147483647' is out of valid index range '0' to '11'
for possibly stack allocated buffer 'szName'
This requires only minimal change: nIndex--.
There is similar warning C6293, which is just inverse of warning C6292 illustrated above. Following code enlightens this:
for(BYTE nIndex = 'A'; nIndex <= 'Z'; nIndex--)
{
printf("%c\n", nIndex);
}
It will display set of characters like below, instead of displaying A to Z.
A
@
?
>
=
<
;
:
9
8
7
6
5
And I heard a beep also! The code above' would produce following warning:
warning C6293: Ill-defined for-loop: counts down from minimum
I shouldn't insult you by telling what change is required to correct this bug!
If the loop control variable is of unsigned type, the following warning would be raised:
warning C6296: Ill-defined for-loop. Loop body only executed once
The code responsible for producing the said warning, for example, can be as pasted below.
unsigned int nLoopIndex;
for (nLoopIndex= 0; nLoopIndex < 100; nLoopIndex--)
{}
Note that, if nLoopIndex were of type int, instead of unsigned int, the warning C6293 would be raised.
And here is fifth warning initiator code in same line:
BYTE nLoopIndex;
for (nLoopIndex= 100; nLoopIndex >= 0; nLoopIndex++)
{}
Which would cause and infinine loop, since it starts from 100, goes till 0 (a wrong assumption). When it reaches 0, which is true condition, it would reach to 255, and therefore a never ending loop. Even when the loop index is decremented, instead of being incremented, the warning loop-construct would be same (infinite).
This code, which uses BYTE, which is just unsigned char, having range from 0 to 255, would cause following warning:
warning C6295: Ill-defined for-loop: 'unsigned char' values are always of range
'0' to '255'. Loop executes infinitely
If loop control variable is of another type (unsigned integral), the range '0' to 'max' would be shown. For example, with an unsigned int loop-control varaible, the warning would be:
... values are always of range '0' to '4294967295'. Loop executes infinitely.
This subsection will now list set of warnings that I could not fit into a category. But, this sub-section must not be ignored as it covers few of most important bugs that may creep into your code. Since I cover all of remaining uncategorized CA warnings, few of them may not please you as such.
Let's start!
We use atol and other variants to get integral out of a string. Without any fuss on this, here is the bug:
int nNumber;
atol("1234");
Of course, the value should be assigned to variable nNumber, but you have forgotten. For this code, you would see other warnings that variable is not used, variable used without assigning, which might not appear if you do assign (with zero, for instance) and use it. The bug would remain with code. A CA compilation would reveal it:
warning C6031: Return value ignored: 'atol'
The prototype of atol is such that it causes CA compilation to emit this warning, if return value is ignored by caller. As said earlier couple of times, I would discuss how to "prototype" your function so that Code Analysis would work for your function when called by user-code, in the next section.
This warning would also appear with other functions like fopen, where FILE* is returned and must be put into variable (or at least checked). Unfortunately, only C runtime functions are only prototyped this way (most of), not the Windows API functions, like HeapAlloc. That means, the Code Analysis will not give any warning with following code:
HeapAlloc(GetProcessHeap(), 0, 1024);
Another common bug that may find its place in your codebase:
int nIndex;
for(int nIndex=0; nIndex<10; nIndex++)
{
}
if( nIndex<10 )
{
}
The loop-control variable nIndex, which is being used inside the loop overrides the definition of first declaration. Thus, the value of nIndex after the loop would remain undefined (or would remain whatever it was set, since it is different variable). The code above produces following warning:
warning C6246: Local declaration of 'nIndex' hides declaration of the same name in
outer scope. For additional information, see previous declaration at line
'348' of 'e:\code\codeanalysis\codeanalysis\codeanalysis.cpp': Lines: 348
The variable should not be re-declared within same scope - And this isn't just about eliminating the warning, but avoiding any potential bug. Sometimes, programmers use STL's iterator variables in multiple loops with same names, which should not be given same name, even if their purpose is very different.
If the first declaration of variable is not local, but global, similar warning, with different code (C6264) would be emitted. This warning and previous warning doesn't care about data types being same or different.
char Buffer[512];
void Foo()
{
void* Buffer = new BYTE[1024*10];
}
The warning message would be:
warning C6244: Local declaration of 'Buffer' hides previous declaration at line '343'...
Though, in this case, it is possible to access global variable using scope resolution operator (::Buffer), giving same name to multiple variables is not recommended.
Unfortunately, this kind of warning will not be thrown if a variable exist in a class, and another variable is declared in class' method. The following code will not produce any warning:
class T2
{
int Age;
public:
void bar()
{
short Age;
Age=0;
}
};
(More to go)
By now you have seen few functions that demand their return value should be checked, the arguments must not be null, the buffer size should match with some constant or argument and so on. Now, you must be wondering how you can do that with your code (say, for a DLL you expose).
For instance, let's say you have written a compression library, which is hosted inside a DLL. Few functions are exported (native C, no C++). Like Windows handles, you expose the compression interface through a handle, which is declared as:
DECLARE_HANDLE(COMPRESSION_HANDLE);
And first of the few functions is:
int InitializeCompressor(COMPRESSION_HANDLE*);
Which initializes a new compression object, and sets the handle for further use. Please don't bother about handle, it's just opaque interface for DLL clients. The DLL client would initialize it as:
COMPRESSION_HANDLE hCompHandle;
InitializeCompressor(&hCompHandle);
You also export two functions to compress and uncompress the data:
int CompressData(COMPRESSION_HANDLE hCompHandle,
const void* pInput, int nInputLen,
void* pOutput, int* pnOutLen);
int UncompressData(COMPRESSION_HANDLE hCompHandle,
const void* pInput, int nInputLen,
void* pOutput, int* pnOutLen);
The client application would typically utilize your compression library as:
COMPRESSION_HANDLE hCompHandle;
InitializeCompressor(&hCompHandle);
char SourceData[512] = "This is the data to compress";
char Compressed[512];
int nCompressedLen=512;
CompressData(hCompHandle, SourceData, 512, Compressed, &nCompressedLen);
And the application can uncompress data in similar fashion.
Now, you would like to prototype the exported functions so that:
- The client should check return value of
InitializeCompressor, and not blindly use the handle directly. - Client application should pass input buffers and their sizes appropriately. What if source data is of
100 bytes (stack or heap), and 200 is passed as source-length? - The same rule applies for output data, where size of data is passed an input-output argument. The pointer's pointed value must refer a correct buffer size.
- Few more, as we will see.
While this needs some discussion (or say a lot, if we want to get into deep of Code Analysis), let me prototype the first function, InitializeCompressor.
__checkReturn int InitializeCompressor(COMPRESSION_HANDLE*);
The symbol __checkReturn, causes the CA compiler, at client's end, to raise following warning (for the code pasted above):
warning C6031: Return value ignored: 'InitializeCompressor'
If you have noticed, curiously, or unintentionally, the prototype of function atol, which is somewhat bizarre:
_CRTIMP __checkReturn long __cdecl atol(__in_z const char *_Str);
Where:
_CRTIMP is nothing but #define for __declspec(dllimport). And I do assume you very well know what does it mean. __cdecl specifies the calling convention, which is C calling convention. __checkReturn specifies that return value should be checked. This is one of the functions whose return value must be put into variable, or at least checked. Thus, this symbol is very meaningful for this function. __in_z expresses that the string passed is C string, which should be null terminated. More on this soon.
I can read your mind having obvious question, "What the hell is __checkReturn and __in_z?".
Well, these symbols are annotations for Code Analysis tool, and they belong to Source Annotation Language (SAL). No, you don't need to learn a new programming language! These are meaningful only for Code Analysis (i.e. when code is compiled with /analyze switch). The SAL is Microsoft specific, and therefore, SAL annotated headers may not compile with other compilers. From MSDN:
The set of annotations describes how a function uses its parameters—the assumptions it makes about them, and the guarantees it makes upon finishing. The header file <sal.h> defines the annotations.
For now, do not bother about what exactly those symbols are - different versions of Visual Studio have different meanings (and different symbol names too). I am deliberately avoiding the complexities in discussion, at least for now. Think of them as macros, and those macros are defined to nothing (like afx_msg), when not compiling with Code Analysis. Otherwise, they have different meaning and CA would understand that, and would produce intelligent warnings.
Let us move further. A buffer (including strings) can be input buffer or output buffer or both. The function strlen, for instance, takes input buffer. Functions, strcpy and memcpy, both take first argument as output buffer and second as input buffer. The functions strupr and memset take input-output buffer. C style strings are actually null-terminated strings, special kind of buffers, and they implicitly specify their size with the null-character embedded within (ignore secure functions for now). For normal buffers, the size of buffer must be specified within function's argument. That's why strcpy takes two, wherease memcpy needs three arguments.
Furthermore, the size of buffer can be represented in bytes, or in elements - i.e. byte-count or element-count. Function memcpy, for example, takes number of bytes are buffer size; wcsncpy (Wide-character version of strncpy) takes element count.
One more thing, which is most basic in case of buffer arguments (or say, pointer arguments) - does the function always take a valid pointer, or can it be null?
Let's start with annotating function which doesn't allow null buffer to be passed. For this, I am adding one more function to our compression library, SetPassword, which sets password for compression/de-compression:
bool SetPassword(__in const char* sPassword);
Where __in annotation specifies that this parameter is input parameter, and thus following code would give the warning as outlined after code.
SetPassword(hCompHandle, NULL);
Unfortunately, none of these warnings are shown in Visual C++ 2005, and I am unaware of the reason. Under VS2008 and VS2010, both warnings are shown.
Well, I believe this is the point where I give the hint about differences in VS2005 and later versions of Visual C++ for Code Analysis compilation. Though, more on this later, annotation __in and __checkReturn, two of the many annotations yet to be explored, are from VS2005. Starting from VS2008, __in is replaced with _In_, and __checkReturn is superseded by _Check_return_ annotation. The difference in these names are mainly the two underscores in former, and one underscore in latter. Higher versions still support older annotations. The Windows headers, however, use the newer versions on VS2008 and VS2010.
Continiuing with original discussion. The CA tool is smart enough to detect potential case where the argument can be null:
char* pPassword = (char*)malloc(200);
SetPassword(hCompHandle, pPassword);
Function malloc is used just for illustration, as it may return NULL, and thus gives CA compiler to do some work. operator new won't return null (it throws exception), thus no warning wont be displayed. Other than this case, the CA also detects possible cases in code-flow to find null-case. The code above gives warning C6387.
And that's the half of story. You know that password is actually a string, a null-terminated string. For this, we need to append _z annotation to __in (or add z_ to _In_). There is well defined symbol for this, which is in <sal.h> and it is: __in_z (or _In_z for higher VS). Thus, we change the prototype as:
bool SetPassword(__in_z const char* sPassword);
Which essentially means that this is input buffer, which is zero-terminated. What's the benefit you might ask. Well, it ensures that string passed to this function is actually null-terminated, and not formed with functions that doesn't write up null-terminated character (like strncpy). When annotated this way, the following code would generate the mentioned warning:
char szPassword[12];
strncpy(szPassword, "CP@1234", 7);
SetPassword(hCompHandle, szPassword);
And that is why strlen function is annotated as:
__checkReturn size_t __cdecl strlen(__in_z const char * _Str);
_Check_return_ size_t __cdecl strlen(_In_z_ const char * _Str);
As you see, the buffer size for null-terminated strings is implicitly passed with the buffer itself. The Code Analysis attempts to find possible flaws around the function call to see if string passed is actually terminated. Therefore, the warnings emitted by CA may not always be correct - it may generate warnings when there is no bug (i.e. it is sure that string is null-terminated), or it may not issue warning if there can be bug with string not being properly terminated. Thus, it is preferable to use secure functions, that end with _s, as they take extra argument(s) for the input and/or output string-buffer sizes.
So, how to you annotate the function for buffer size? Repeating again, the buffer can be combination of:
- The Input and/or Output buffer.
- The buffer size can be in bytes or in element counts.
- If the buffer can be null (i.e. optional).
- The buffer size is specified by a constant (like
MAX_PATH or any constant), or is specified by another argument, or by other mechanisms. - For multiple level pointer (pointer-to-pointer, like
BYTE**), what exactly specifies the buffer, the pointer or the pointed-pointer? - Similarly, for in/out buffer size (like
size_t*) the size of buffer can be specified by the pointed-value.
I do believe not all points mentioned can be absorbed by you instantly, and you can come back again! I will elaborate all points with good and meaningful examples, so that everything is crystal clear.
For ongoing discussion, let me modify SetPassword which would take a password string exactly of 8 characters (bytes), and there wont be any null-character involved. The modified function will look like:
bool SetPassword(COMPRESSION_HANDLE, __in_bcount(8) const char* sPassword);
The buffer is input, thus __in annotatoin. Annotation _bcount specifies the buffer-size in bytes. The complete symbol is defined via header sal.h. Since this is one of the meaningful annotation it is explicitly defined (like LPCTSTR, which is combination of multiple constructs). Nevertheless, you can also separate them out and use "__in __bcount(8)" which would almost mean the same.
Now, we call this function with exactly 8 character password:
SetPassword(hCompHandle, "1234ABCD");
And there wont be any warning. If you specify a string of 20 characters, no warning would occur since SetPassword has specified that it would read only 8 bytes. What if you call it as:
SetPassword(hCompHandle, "XYZ");
And this would cause following warning to have its footprint on Build-output:
warning C6385: Invalid data: accessing 'argument 2', the readable size is '4' bytes,
but '8' bytes might be read: Lines: 383, 384, 390
VC2008 and VC2010 would produce the following warning also:
warning C6203: Buffer overrun for non-stack buffer '"XYZ"' in call to 'SetPassword':
length '8' exceeds buffer size '4'
Four bytes? You passed only 3 bytes, right? Wrong! A C-string is always null terminated, and when you hardcode it, the compiler puts null-character at end. Even if you type-cast it to something else, "XYZ" string would still occupy 4-bytes. Thus, in first call to SetPassword above, the string "ABCD1234" is actually 9-byte string, but function will read only eight bytes (as annotated).
Since, this is just for example, you generally dont pass a hardcoded string. More generally you do allocate a char buffer (stack or heap), explicitly initialize the elements of it and pass to a function - A function that takes char-array, but doesn't treat it as string, but a sequence of bytes.
Few functions, like GetTempFileName, specify constant (MAX_PATH) as the buffer-size. But, most other functions do specify the buffer-size with another argument, like GetWindowsDirectory. Now, I will show you how to specify buffer-size with another argument to a function, and this is pretty straightforward:
bool SetPassword(COMPRESSION_HANDLE,
__in_bcount(nPasswordLen) const char* sPassword,
int nPasswordLen);
Though, you should use size_t to specify buffer size, but I used int for simplicity. The meaning of annotation is self explanatory. Interestingly, the SAL also supports to specify expression for buffer size, therefore, following is also good:
__in_bcount(nPasswordLen - 1) const char* sPassword,
And it may properly fit with SetPassword! Anyway, I am using non-expression version for this discussion. The client may make a call to this function as:
SetPassword(hCompHandle, "ABCD1234", 8);
The following code, which passes an invalid size (or an invalid buffer),
char szPwd[]="ABCD";
SetPassword(hCompHandle, szPwd, 8);
would trigger CA tool to produce following warning(s):
warning C6202: Buffer overrun for 'szPwd', which is possibly stack allocated, in call to
'SetPassword': length '8' exceeds buffer size '5'
warning C6385: Invalid data: accessing 'argument 2', the readable size is '5' bytes,
but '8' bytes might be read: Lines: 383, 384, 391, 392
And you know how to rectify this bug/warning.
Allow me add two more things to SetPassword:
- What about Unicode/Wide-char strings?
- What if you want to pass password as null-terminated string, and the buffer size is just specification for maximum (like in secure functions) ?
For point 2, you can simply do:
bool SetPassword(COMPRESSION_HANDLE,
__in_bcount_z(nPasswordLen) const char* sPassword,
int nPasswordLen);
The annotation __in_bcount_z, would mean:
- The buffer is not optional, and cannot be null (
__in) - The size of buffer is as specified in parenthesis (
_bcount) - And the buffer should be a properly null-terminated string (
_z)
For the modified annotation for function SetPassword, the following code would emit set of relevant warnings (not shown):
char szPwd[10];
strncpy(szPwd,"ABCD",4);
SetPassword(hCompHandle, szPwd, 20);
For point 2, we need to use element-count as buffer-size specification instead of byte-count. First let me show you one more method, which is not-recommended:
bool SetPassword(COMPRESSION_HANDLE,
__in_bcount_z(nPwdLen * sizeof(WCHAR)) const WCHAR* sPassword,
int nPwdLen);
This essentialy takes buffer size in byte-count and caller must pass actual number of bytes as the buffer length. For sure, followiing is also possible, that makes it compilable to both Unicode and ANSI:
bool SetPassword(COMPRESSION_HANDLE,
__in_bcount_z(nPwdLen * sizeof(TCHAR)) const TCHAR* sPassword,
int nPwdLen);
Still, it demands the byte-count and not element count, and may confuse the caller. The client must call it like:
TCHAR szPwd[10];
_tcscpy(szPwd, _T("ABCD") );
SetPassword(hCompHandle, szPwd, _tcslen(szPwd) * sizeof(TCHAR));
Which is definitely inappropriate and hard to understand. Though, this would compile and show warnings in both ANSI and Unicode builds, but coding like this would be more bug prone. (Read this article to know about TCHAR stuff)
NOTE: Please ignore your concern about ANSI/Unicode functions being exported from our DLL. You can, definitely, use macros to hide two versions, like Windows headers do.
The following annotation is what we need for element-count specification:
bool SetPassword(COMPRESSION_HANDLE,
__in_ecount_z(nPwdLen) const TCHAR* sPassword,
int nPwdLen);
The embedded annotation, _ecount, specifies that sPassword should be counted upon as element-count for buffer-size. The buffer-size, in elements, is specified by nPwdLen.
The correct code to call SetPassword would be:
TCHAR szPwd[10];
_tcscpy(szPwd, _T("ABCD") );
SetPassword(hCompHandle, szPwd, 10);
You can also use _tcslen (variant of strlen), instead of constant 10. If the client uses sizeof to specify buffer-size:
SetPassword(hCompHandle, szPwd, sizeof(szPwd));
The Code Analysis would render following warning:
warning C6057: Buffer overrun due to number of characters/number of bytes mismatch
in call to 'SetPassword'
Since sizeof would always return the number of bytes, and not the number of characters. This warning, would however, may not be shown when code is being compiled in ANSI (MBCS) mode. Therefore, either of following should be used to pass number of elements as buffer size:
SetPassword(hCompHandle, szPwd, _countof(szPwd));
SetPassword(hCompHandle, szPwd, sizeof(szPwd) / sizeof(TCHAR));
Though, I have not shown the code of SetPassword yet; yet I want to add one more promise: The function will also be able to handle null pointer. That means, it will check if pointer (2nd argument) passed is null, and would return immediately. To let the programmer and the CA tool to know of this promise, I add one more stuff to buffer annotation:
bool SetPassword(COMPRESSION_HANDLE,
__in_ecount_z_opt(nPwdLen) const TCHAR* sPassword,
int nPwdLen)
Note the _opt added to annotation, which does not mean that argument is optional in programming perspective (like default arguments in C++), but the buffer is optional. It can be null. This way, if a call to SetPassword is made like following, no warning would be generated (otherwise C6309, C6387 would appear, as illustrated above):
SetPassword(hCompHandle, NULL, 10);
Since the function promises (or say gives guarantee) that it would check for null argument, the CA compilation would ask you to keep that promise. Following is first of implementation code, I am giving light on:
bool SetPassword(COMPRESSION_HANDLE,
__in_ecount_z_opt(nPwdLen) const TCHAR* sPassword,
int nPwdLen)
{
char cLetter;
cLetter = sPassword[nPwdLen];
return false;
}
The CA compilation would give following warnings for SetPassword:
warning C6385: Invalid data: accessing 'sPassword', the readable size is 'nPwdLen*2' bytes,
but '4' bytes might be read:
warning C6011: Dereferencing NULL pointer 'sPassword': Lines: 364, 365
The sequence of warnings shown isn't important, but warnings itself. You correct the second warning (C6011) by putting a null pointer check and return:
bool SetPassword(...)
{
if(sPassword == NULL)
return false;
...
}
The first shown warning (C6385) would need some explanation for you. I compiled the code with Unicode enabled, therefore it shows 'nPwdLen*2'. If we compile it on ANSI/MBCS build, or change the datatype from TCHAR to char, it would simply say "'nPwdLen' bytes...". This is actually the number of bytes the function should read (since the function itself is making the promise).
Further, for Unicode compilation it says, "...but '4' bytes might be read". For ANSI compilation, the CA compiler would say that 2 bytes might be read. Ponder!
Arrays are zero-based; nPwdLen is size of buffer specified, therefore it would logically be >0, and the nearest valid number is 1. The data on index 1 (sPassword[1]), for char-buffer is actually reading 2 bytes! Similarly, data on index 1 for Unicode string is would be attempting to read 4 (or 4th) byte!
By now, you are probably bored of SetPassword (at least I am!). So, let's play around with other functions that our compression library exports. Now, I would cover up CompressData and UncompressData, and show what promises it can make.
Before annotating, I should remind you that till now we worked only on input-buffers, and not on input, input-output buffers. It's time to move on and enlighten them, along with other related stuff!
Let me reintroduce our forgotten heroes, which are important players in our compression DLL, and they are...
int CompressData(COMPRESSION_HANDLE hCompHandle,
const void* pInput, int nInputLen,
void* pOutput, int* pnOutLen);
int UncompressData(COMPRESSION_HANDLE hCompHandle,
const void* pInput, int nInputLen,
void* pOutput, int* pnOutLen);
They employ input buffers, output buffers and an in/out parameter.
You must be quite comfortable with input buffer annotation (you should!), therefore I straightaway annotate input buffers for both functions.
int CompressData(COMPRESSION_HANDLE hCompHandle,
__in_bcount(nInputLen) const void* pInput,
int nInputLen,
void* pOutput, int* pnOutLen);
int UncompressData(COMPRESSION_HANDLE hCompHandle,
__in_bcount(nInputLen) const void* pInput, int nInputLen,
void* pOutput, int* pnOutLen);
And the annotated stuff simply means that the pointer/buffer cannot be null, and the buffer size is nInputLen bytes. On top of this, the following code would cause CA to say something.
char SourceData[500] = "This is the data to compress";
char Compressed[512];
int nCompressedLen=512;
CompressData(hCompHandle, SourceData, 512, Compressed, &nCompressedLen);
And the warning, that you have seen umpteen times, is:
warning C6385: Invalid data: accessing 'argument 2', the readable size is '500' bytes,
but '512' bytes might be read
Which is a potential bug and should be corrected.
And now, let's see how we can annotate for output buffer. For this, we need to use __out annotation (or _Out_ for VS2005 and higher). This is simpler than you might think:
int CompressData(COMPRESSION_HANDLE hCompHandle,
__in_bcount(nInputLen) const void* pInput,
int nInputLen,
__out void* pOutput, int* pnOutLen);
Which just expresses that pOutput is an output buffer, and that it cannot be null. Passing NULL as 4th argument would cause C6309 ("Argument is null, does not adhere to specification").
Alright! How do you specify the buffer-size for this parameter? For now, lets assume the input-length and output length, on function entry, are same. Thus, following annotation can be used:
int CompressData(COMPRESSION_HANDLE hCompHandle,
__in_bcount(nInputLen) const void* pInput,
int nInputLen,
__out_bcount(nInputLen) void* pOutput,
int* pnOutLen);
And this would cause warning(s) if inappropriate buffer sizes are passed.
Definitely, for compression, the input buffer and output buffer size (even on function entry) cannot be same. The input buffer is what is available/generated for compression at the time of function call. Output buffer, which would hold compressed data, would generally have some specified size. Anyway, we can use following annotation, which specifies output-buffer's size from last parameter:
int CompressData(COMPRESSION_HANDLE hCompHandle,
__in_bcount(nInputLen) const void* pInput,
int nInputLen,
__out_bcount(*pnOutLen) void* pOutput,
int* pnOutLen);
Please note the indirection. The value at pOutLen would be considered on entry. Therefore, following code would produce warnings, as commented:
char SourceData[500] = "This is the data to compress";
char Compressed[512];
int nCompressedLen=514;
CompressData(hCompHandle, SourceData, 512, Compressed, &nCompressedLen);
If you remember, the datatype COMPRESSION_HANDLE was declared with:
DECLARE_HANDLE(COMPRESSION_HANDLE);
And which is how most Windows handles are declared. No, I am not going into deep of handles, or what exactly DECLARE_HANDLE macro means; think of it as a void-pointer. Therefore it is possible to annotate the first arguments of our functions (that take COMPRESSION_HANDLE), to ensure that caller passes non-NULL handle. And this is quite easy:
int CompressData(__in COMPRESSION_HANDLE hCompHandle, ... );
int UncompressData(__in COMPRESSION_HANDLE hCompHandle, ... );
And as you can guess, passing NULL to first parameter of these functions would emit a warning, mentioning that argument should not be null. But our function InitializeCompressor is not smart enough (yet) to tell that it may return a null handle, and therefore no warning would arrive. More on this soon.
Till now I have covered how to specify the input buffer sizes. What about output buffer size? By this I mean, how many bytes/elements are valid to read after a function returns. For example, on input we say that input buffer is 100 bytes, and maximum output buffer size is 100 bytes, where compressed data would be placed. Let's say compression of those 100 bytes is 67 bytes.
In coding terms, this is what I mean:
BYTE data2compress[100];
BYTE compressed_data[100];
int nMaxSize=100;
CompressIt(data2compress, 100, compressed_data, &nMaxSize);
Though, the accessible bytes from compressed_data buffer is still 100 bytes, not all 100 bytes are valid. The compressed size may be just 67 bytes. A code, like following may attempt to read any arbitrary number of bytes from compressed data; and this bug should be reported by Code Analysis:
if(compressed_data[90]==144
compressed_data[91] = 128;
[Please accept the deviation from CompressData to CompressIt function, which is temporary, and for a reason.]
The compressed buffer (or any output buffer) may also be read through a loop, and we need to ensure that buffer access is valid. For this, we can specify how many bytes/elements the function would write into the buffer
Okay, after much of research, failed attempts to use _part annotation which is made for this purpose, the following code does not do anything:
int CompressIt( void* pInput,
int nInputLen,
__out_bcount_part(nMaxOutLen, *pnOutLen) void* pOutput,
int nMaxOutLen,
int* pnOutLen)
Other required annotations are omitted for brevity. The purpose of _part annotation is to tell Code Analysis tool, that first argument is the input-size (say, max-size) of output buffer (in bytes or in elements, depending on bcount/ecount used). And the second argument tells the output size of buffer (i.e. how many bytes/elements this function would modify). Thus, any code, following this function call, if attempts to read (not write) beyond the specified output-length would supposedly raise a warning from CA. The output length, specifies the valid buffer length.
But, the current versions of Visual C++ (2005, 2008 and 2010) do not raise any warning for a similar code. Noticeably, umpteen number of functions in VC++ headers (irrespective of VS version, or PSDK installed) do have this annotation (__out_bcount_part) applied to functions. One of them is ReadFile which is annotated as:
ReadFile(
__in HANDLE hFile,
__out_bcount_part_opt(nNumberOfBytesToRead, *lpNumberOfBytesRead) LPVOID lpBuffer,
__in DWORD nNumberOfBytesToRead,
__out_opt LPDWORD lpNumberOfBytesRead,
__inout_opt LPOVERLAPPED lpOverlapped
);
Which effectively tells that nNumberOfBytesToRead is how many bytes to read (and can be read into this buffer), and on return how many bytes are actually read into buffer via *lpNumberOfBytesRead specification. Therefore, a code like following should give warning, which is not reported by any version of Visual C++ compiler:
HANDLE hFile;
BYTE Buffer[100];
DWORD nBytesRead=0;
ReadFile(hFile,Buffer, 100, &nBytesRead, NULL);
if(Buffer[nBytesRead+1]==77)
Buffer[nBytesRead+2]=99;
Which raises following set of warnings, which we have seen for long:
warning C6031: Return value ignored: 'ReadFile'
warning C6001: Using uninitialized memory 'hFile': Lines: 383, 384, 385, 386
The second warning would change to C6387 if I do initialize hFile to NULL. But, that's not the point here. If I pass invalid size of input buffer, the Code Analysis would, however, find this bug:
ReadFile(hFile,Buffer, 110, &nBytesRead, NULL);
Which means, IN specification for bcount/ecount does work, and OUT specification does not.
Why I am mentioning all this, that doesn't work? Well, it does work. The _part annotation works with other modes:
- When the output size is specified as constant.
- When output size is pre-argument (i.e. specified via any integral argument on function-entry)
- When output size of specified via return value of function.
This turns out that only Post-Argument size specification doesn't work, despite the fact MSDN and SAL.H mentions that it is supposed to work. Other than pointer, I have also tried with reference (int&), it doesn't work either. If anyone has any comments/links for this, please let me know. Obviously, I have searched!
- Specifying output buffer size with a constant.
void Convert2Hex(int nNumber,
__out_bcount_part(nInput, 16) BYTE* pConverted,
int nInput);
Which explicitly states that it would write 16 bytes. Therefore, following code would emit warning:
BYTE Hex[100];
Convert2Hex( 10, Hex, sizeof(Hex) );
cout << Hex[16];
The third argument to this function is not required. Back to that soon.
- Specifying output length with other in argument
I do not see the meaninfulness of this approach, but it works. Why would anyone specify the output-buffer's output length with an in argument - that is the question! One particular reason, though, I can state: Another function would return the the output length, and can be specified into desired function. Many Windows functions, for example, require you to pass NULL to an argument that should would have the "informaiton", and another argument would receive the required-buffer-size.
Anyway, here is an example:
void Bogus( int nInLen, int nOutLen,
__out_bcount_part(nInLen, nOutLen) BYTE* pBuffer);
And here is the usage example, followed by warning:
BYTE Buffer[100];
Bogus(100, 40, Buffer);
cout<<Buffer[41];
- Specifying output length with function's return-value
Well, this approach is somewhat I like; though not comparable to pointer/reference approach that doesn't work! This annotation type is somewhat eccentric. You use the keyword 'return' itself to specify output buffer's output length. An example:
int Convert2Binary(int nNumber,
__out_bcount_part(nInLen, return) char* pConverted,
int nInLen);
Which says the return-value is the output buffer's valid buffer length the program should read after this function call. For sure, you can also specifiy __checkReturn to ensure that return value is utilized.
Quite weird, but standard compiler and CA compiler doesn't go together - a function returning void may also use this approach. The annotation __checkReturn can also be applied to a function returning void! To uncover any confusion you might have, the warnings related to SAL itself is from another arena, which I have not covered yet.
A usage example:
char Binary[120];
Convert2Binary(127, Binary, sizeof(Binary));
cout << Binary[1];
Please note that though the function Convert2Binary takes a char-pointer but it doesn't treat it as string. The usage code given above would produce following warning:
warning C6385: Invalid data: accessing 'Binary', the readable size is 'return value' bytes,
but '2' bytes might be read
One of the correct way to utilize Binary array is:
char Binary[120];
int nBinLen;
nBinLen = Convert2Binary(127, Binary, sizeof(Binary));
for (int nIndex=0;nIndex<nBinLen;++nIndex)
{
cout << Binary[nIndex];
}
(More to go)
This topic is obscure, vague and not well explained anywhere. I am gathering information, and will put everything in one place, with all possible approaches that can be used to make user/your-code analyzable. Allow me some time!
History
- Nov 13, 2010 - Initial Post
- Nov 14, 2010 - Buffer overrun, format-string warnings
- Nov 17, 2010 - Null terminated strings, Ill-defined loops warnings
- Nov 18, 2010 - Other Miscellaneous concerns (partial)
- Nov 20-22, 2010 - Making your code Analyzable (partial)

