Introduction
Hi folks,
This time I wanted to bring something that I think is very useful but there is not much information about it. "Everybody" loves Microsoft and their products, but when we talk about products like whether these products run on a trusted environment and support big loads then these big companies start looking elsewhere especially when we talk about critical data.
That is the case with Oracle and SQL Server. I have worked with Oracle and SQL 6.5/7.0 and I don’t want to create a discussion forum on each one, but still SQL is not as trusted as Oracle. Hopefully, SQL Server 2005 will reduce the breach between them.
When Oracle was run on Intel it gave unexpected results, I don't know about the new servers running on 64 bits, but so far my experience with it was not too good. On the other hand, Oracle runs pretty well on Unix/Linux.
Usually, I like to do my projects with the best that is available in the market and when it comes to database where there is a huge amount of data, immediately Oracle came to my mind. Now when we have to program the application and/or the front end layer then there is no choice other than go for Microsoft. Here you can choose between C/C++, MFC, VB and now the amazing .NET.
Oracle advance queue
Some time ago, I had to work with Oracle advance queue and I was amazed with what they could do. This is the link that was missing between the DB and the applications. Of course, it had Oracle pipes, but they are a prehistoric version of what advance queue can do. I’m not an Oracle expert, and neither a DB developer, I’m on the middleware side where I see DB as a big bunch of organized data and I have to insert or extract information as fast as possible.
Today many applications are reading and writing on the DB at the same time, but the problem arises when one application depends on the input of another application. Think about a process that does sales billing. The first process will create the sale and insert all data in the DB. The second process gets the last fresh info from the DB and mixes it with another data coming from a different place to create an invoice.
In the traditional way, the second process will query the DB or execute a store proc say every 10 seconds may be, and process all those invoices that were introduced in the last 10 seconds. Basically the second process queries the DB to "see" if there is fresh data. What if there is no new data in the DB, which means that the local process has spent local resources trying to get this information, as the DB also spends resources querying tables. (Basically we are wasting resources).
Now think that these transactions are introduced in the DB every second then in the first 9 seconds the second process won't do anything. When the second process queries the DB it will have 10 transactions to process which means that the local process has spent 90% of the time doing nothing and then overloaded the machine trying to process 10 transactions at the same time.
It can be easily resolved using messages, exactly what Windows does when you make a click somewhere inside the screen, instead of querying Windows every milliseconds to know if the mouse was pressed, we give that responsibility to Windows to tell us when somebody presses a button. In the Windows environment we call this an Event.
Oracle advance queue is similar to this concept, it can work in many ways, but what I like the most is the asynchronous method. We are going to give the responsibility to Oracle to tell us when a new transaction arrives and at the same time send the input data to be processed.
If we now apply the same example given above, now every time the DB has a new data, it will immediately notify the second process to grab this info. The second process now has a whole second to process each transaction. With this concept we use the resources only when we need it.
What about a big load to be processed?
Using this mechanism is very efficient. Let's now go through the problem that the second process takes too long to process a message, just think that a lot of info is being inserted into the DB in the first process, and in the second process part of it creates a SOAP post to another server which takes between 0 to 2 seconds in the idle state to respond. Because of that Oracle queue will start to grow as the second process won’t process another AQ message as long as it doesn't finish processing the first message.
We could run more instances of the "Second Process" on the same machine or put more machines running on the "Second Process", definitely it will help but still we are wasting resources. Running many machines is a costly affair and running many processes on the same machine overloads the CPU processor.
Processing many AQ messages at the same time
As we saw, the second process can wait in the idle state for a SOAP response, and need not process new AQ messages, what if we take advantage of that and make sure that we spend the CPU processor time as best as we can processing more than one AQ message at the same time. Basically the concept is pretty generic and powerful. One process will create two plus X threads to do the job. One Producer, One Dispatcher, and X Consumers.
Pizza delivery job
Think about having a huge truck fully loaded with pizzas (AQ messages) that we need to deliver to the clients around the city. There is one guy "Producer" at the back of the truck. One guy "Dispatcher" at the edge of the truck door waiting for the pizzas. Many guys "Consumers" ready to deliver the pizza to the customers. The Producer will go inside the truck and start making a pizza stack at the edge of the back door in the truck ready to be taken by the dispatcher. The Dispatcher will take one and look at the delivery guys to see if the Consumer is free or if there is anyone back after the previous delivery. The Dispatcher works as a load balance thread. The Consumer's task is only taking the pizza from the Dispatcher guy and delivering it to the right customer.
Using this concept, each guy will work as much as he can and each one will do a simple task independent of the rest. If a delivery guy “Consumer” has many red traffic lights on the way to the customer, it will take more time to do the delivery, but another guy will be ready to take his pizza from the dispatcher and make the delivery.
Of course, like in the real life it can also be a problem. If every deliver guy takes too long to deliver a pizza or go home to drink a beer or visit his girlfriend and go back to work then only few Consumers will be available to keep doing the Job, because of that the dispatcher cannot take more pizzas from the truck door, and the Producer will keep putting the pizzas on the edge. At some point, the truck door will be full of pizzas where it will be difficult for the dispatcher to take one and the producer won’t have any space left.
For that reason the Producer will have an optimum limit on the pizzas that can be put in the truck door. In this way, our process will work as best as it can spending exact amount of resources necessary for the task.
.NET publisher (same as JPublisher for Oracle/Java)
Currently, Oracle supports Oracle custom types which are similar to a class in the .NET world. Both contain constructors, methods, and fields.
When Oracle AQ delivers a message it is basically of one type, but in .NET, a type or class can contain one or more native/custom types/classes. So, we will have one type which will be the entry point to the hierarchical data structure that can be as big as you want. Oracle types are not compatible with anything else outside the Oracle environment so basically we need a "mapping" between the two worlds, in Java there is a process called JPublisher. JPublisher will take as parameter "the root type" and will navigate through all the fields in it (recursive types inclusive) and will create the .java files that will map those Oracle types.
The Java developer will take those .java files and include them in his own project, now every time the Java process takes an AQ message it will create objects from the .java files generated by JPublisher and fill those with the AQ message data.
Finally, a Java object will be the root for all the data from the AQ message. Oracle misses this tool for the .NET developers, or at least in version 8, 9i or 10g. Oracle Data Provider (ODP) basically is the same as .NET Managed Provider for Oracle from MS and both of them don't have Oracle AQ support.
Oracle will probably implement OAQ in future inside ODP but because "future" is not useful here, I created basically what JPublisher does but it generates .cs CSharp files, and with a small change it can be modified or expanded to create .cpp (MC++) or .vb (VB.NET) files.
Inside the AQLib there is a class Publisher, it contains four methods to work with Oracle queues for type mapping:
GetQueueName: It will receive an array of queue names from the Oracle DB for the oracle user.
GetQueueTypeName: It will get the Oracle type associated with a specific queue.
GetTypeDetail: It will get the hierarchical structure about the Oracle type info and the entire fields inside it.
CreateFileType: It will take as parameter an AQObjectDetail from GetTypeDetail and create the .cs files on the FS. (It will create as many files as the type and types inside the Type in the parameter.)
Note
At first, I used CodeDom class on the publisher project to create the files, but .NET CodeDom produces the code to be compiled for the CSharp compiler, it produces a real horrible code that any developer would hate to see, I guess the guy inside MS who created CodeDom didn’t have enough time to provide tools to create a readable code for the developer. (For me a readable code has the same importance as the running code stability). Because of this, I just replaced CodeDom with a simple TextWritter writing in the file, exactly like what I wanted to produce. Also the CodeDom source code is in the library, it is commented because it is obsolete but I leave it there just in case you want to see how it works.
Oracle advance queue support in .NET world
If you want to access Oracle advance queue from a high level point then you are out of luck. Oracle advance queue is supported for OCI or OO4O and not for ODP. At first, I expected to find AQ support inside ODP (Oracle Data Provider) but nothing was there, I kept researching and found that OO4O (Oracle Object 4 Ole) supports Oracle AQ.
I created a ticket in Oracle metalink asking about it, and they replied that currently they don’t have Oracle advance queue support from ODP but they will consider implementing it in future. OO4O fully supports Oracle advance queue. You can get the installer from the Oracle client or from here.
AQLib uses OO4O for Oracle9i Version 9.0.1.4.3 but I tried using OO4O for Oracle10g Version 10.1.0.5.2 on Oracle 9i and it worked perfectly. If you don’t have Oracle client and OO4O on your machine then download OO4O90143.exe and install it in your client using the link given above.
Warning
OO4O for Oracle 9i under stressful test on “some” machines gives NULL pointer exception when a message is dequeued, I wrote an Oracle TAR and they suggested to install the Oracle 9.2.0.7.0 client patch for Oracle client 9.2. I installed the patch and after that it worked OK, but still under very stressful situations I get the same NULL pointer error.
You can get the patch from the metalink if you have Oracle support, the patch number is 4163445 and it has 228 MB, as you can see the Oracle client 9.2 is 82 MB and the patch for it is 228 MB, the patch will just replace the files that are necessary, but still 300 MB has to be downloaded :).
I used OO4O for Oracle 10g Version 10.1.0.5.2 for Windows 2000/XP/2003 ODAC101040.exe from here. I did not have any problem with the NULL pointers on a Oracle 9i DB and it has "just" 174 MB in all.
Oracle 9i developers: If you have Oracle 9i then "try" to use Oracle client 9.2, if you get errors, then install the patch 4163445 from Oracle metalink if you have Oracle support. Else you can go with the easy solution and install OO4O for Oracle10g (10.1.0.5.2) ODAC101040.exe, but you will be using a OO4O client for version 10g on an Oracle 9i DB, I’m pretty sure they are 100% backward compatible.
Oracle 10g developers: Install OO4O for Oracle10g (10.1.0.5.2) ODAC101040.exe. OO4O was created to be used with C++ and VB and other languages using COM. The objective was creating a managed .NET library to be used from any .NET language.
- First attempt was to create a library in C# and add a reference to "Oracle Object for Ole" from C# creating an interop file. This didn’t work, and in fact, there are critical classes that were not exposed to C#.
- Second attempt was to create a MC++ (Managed C++) library and add as reference "Oracle Object for Ole", this time the interop file was created and all the classes were exposed, but when you try to execute most of the simple codes, OO4O COM object crashed giving exceptions of all kinds, I tried to make it work in many ways but I couldn't.
- Third attempt was creating a MC++ (Managed C++) but not using the COM object, or else linking the library directly with ORACLM32.LIB and using an AQ object in a raw way from oracl.h, this case worked pretty well.
Compiling the code
To compile the code you need OO4O already installed, if you are using OO4O version 9 and it was installed in the default directory, then you don't need to do nothing, just compile the code and run it. If you have installed OO40 version 10 or the default directory is different from C:\oracle\Ora92\oo4o\CPP\LIB then you will need to change two paths for the AQLib project. To do that:
- Right-click on AQLib Project->Properties->Linker->General->Additional Library Directory and change the path for the path where OO4O is installed.
- Right-click on AQLib Project->Properties->C/C++->General->Additional Include Directories and change the path for the path where OO4O is installed.
AQLib description
AQException
All methods inside AQLib are free unknown exceptions; all of them have a try/catch and AQLib will only produce one kind of exception, AQException, if the error is coming from AQLib then AQException will have an error code and an error description, if the exception is coming from OO4O then it will produce an AQException with error code -9999, and an inner exception will give the OO4O OException.
AQManager
AQManager class will take care of creating a DB session and a DB connection, it also opens an Oracle AQ and has enough code to dequeue one message from the AQ. After that an AQMessage is dequeued and the message is on OObject (Oracle Object), AQManager will parse OObject and using reflection will map every field inside the Oracle object with each field inside the type declared as a parameter in the Dequeue method.
I tried to map the entire set of Oracle types in the best way possible but I couldn’t test all of them. If your type cannot be mapped just write me a message with the type and the data and I’ll fix the library.
Producer/Dispatcher/Consumer
Inside AQLib there are 10 classes, three of them will do the AQ dequeue job for you.
AQProducer
AQProducer will spawn a new thread and it will take care of opening a DB connection to create an AQDispatcher and will listen for the AQMessages from a particular queue. Each time an AQMessage is dequeued it will be re-queued on the dispatcher queue. If the dispatcher queue is full (100 messages hard coded) it won’t dequeue any message and it will wait for making the space available on the AQDispatcher queue. If you see the code, I had to create a workaround to dequeue an AQMessage inside AQManager.cpp, because when .NET threads are simply sitting and waiting for the memory objects, they cannot be aborted (It is by design, but I think it is a design bug :) ), because there is no way to send a signal to OO4O to tell stop listening and give me the thread control back, I had to put a dequeue with 2 second time-out, if in 2 seconds an AQMessage was not dequeued then an AQException will be raised, and there it will query if the AQProducer wants to be finished, if not, it will try to dequeue again from the AQ. That is one of the reasons when you stop the demo it takes a couple seconds to unload.
I'm still researching but the library has a memory leak of 20 bytes for every AQMessage dequeued, which means it will have a 20 MB memory leak for every million AQMessage dequeued. I checked the code many times and I think probably the leak is coming from the OO4O library but still I’m working on it. (In real life processing a lot items a day could take a long long time before you need to restart the process, may be 6 months and still it is only 20 MB memory leak whereas a server usually has a minimum 1 GB of RAM). The AQProducer can dequeue AQMessages in three different modes.
- Browse: Get
AQMessage for AQLib and the message is available in the queue to be taken again.
- Lock: Read and obtain a write lock on the message (still under development).
- Remove: Read the message and remove it from the queue.
AQDispacher
AQDispacher will spawn a new thread and will sit and listen for a .NET AutoReset event. When this event is set it will query AQDispatcher queue and will deliver all the AQMessages to free the consumers. The AutoReset event is set by the AQProducer each time there is a new AQMessage. The logic used for the AQDispacher to load balance the AQMessages is the next. If for example, the client creates 50 consumers then it will do a round robin algorithm to find the next free consumer, which means first it will ask consumer 1 if it is available, if it is then it will deliver the message and will increment the consumer flag, next time it will be 2, 3… 50. When it restarts and asks for consumer 1 and if it is not available then it will skip that and try to find the next available consumer. Each time a complete loop is made and the AQDispacher waits for 500 milliseconds before asking again, this is to avoid the AQDispacher overloading the CPU in case all the consumers are busy otherwise, the AQDispatcher will generate a CPU intensive loop which will make the consumers slower creating a slower chain effect.
AQConsumer
AQConsumer is a simple class, it will be instantiated by the dispatcher or it will be instantiated by the client before creating AQProducer. This class has a virtual method ProcessPayload, the client must create a new class inherited from AQConsumer and implement the method, ProcessPayload. ProcessPayload method is like the main method on a standard process; here the client will introduce whatever code is necessary to process the AQMessage. ProcessPayload comes with a parameter "payload" type object.
This payload object has to be casted to the DB type before it can be used. The type to be casted must be the same as the type declared on the AQProducer object.

Perfect working mode according to the project
AQProducer can work in three different modes, each one has some differences against the other.
Single callback
When the process needs to dequeue a message and getting the best performance is not an issue then we can make AQProducer work on a single callback mode, this means that each time an AQMessage is dequeued the callback function declared as parameter in AQProducer will be called. This configuration won’t create a dispatcher or a consumer, and basically the AQProducer won’t dequeue a new message as long as the callback function hasn’t returned the thread control to the library.
Dynamic AQConsumer creation
AQProducer will create an AQDispatcher and this will create X instances of AQConsumers declared as parameter, this is useful where every consumer has to allocate his own resources inside the ProcessPayload method, basically this ProcessPayload method works like the main method of a standard process. The consumer is created automatically and ProcessPayload is called for every new AQMessage.
Pre-instantiated AQConsumer
AQProducer will create an AQDispatcher and this will take as parameter an array of AQConsumers already instantiated, this is useful when an AQConsumer needs to allocate resources prior to calling the ProcessPayload method. For example, each time the ProcessPayload method is called it needs to process the data and store it again in the DB. If we use dynamic AQConsumer creation we would create an OLE DB connection each time the ProcessPayload is called. If we use pre-instantiated AQConsumers then we can create the array of consumers and create an OLE DB connection for each consumer, then every time the ProcessPayload is called we can reuse the DB connection previously created saving resources and improving performance. I tried to create the classes as open/flexible as possible. For example, instead of using AQProducer you can create a new class inherited from AQProducer to add more functionality to it. Also, you can create a new kind of dispatcher inherited from AQDispatcher and set it in AQProducer.Dispacher. AQConsumer by default is abstract and must be inherited to add any kind of code there, especially for having the flexibility of running AQProducer in a dynamic or pre-instantiated mode.
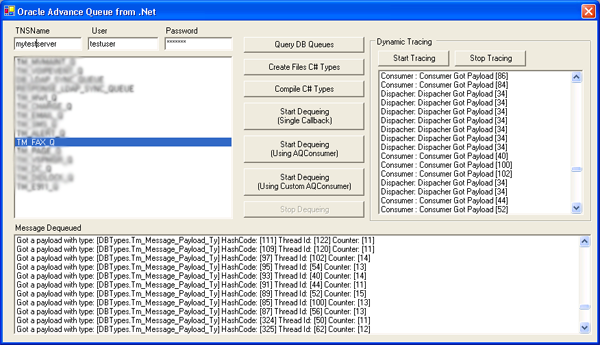
Dynamic tracing
Like other critical production code it has to run for a long time without being stopped, and at the same time we would like to have a way to trace for problems, also it would be good if we could watch the behavior of the library from a different application without messing the log files. Well, AQLib supports dynamic tracing, I learned this trick some time ago when I had to capture the Visual Studio Output window. (Thanks ashvin) AQManager will create a Windows event and will query it every time an AQMessage is dequeued or an instance of AQManager is created. The event name is "AQEnableTracing".
If AQEnableTracing event is set then all classes in AQLib will start to log trace sentences, all those sentences will be captured for the shared memory using the TracingHelper class and every sentence will fire a .NET event.
This case is pretty useful because we can control AQLib tracing from a totally different application, just like the TraceMonitor example in the demo, add a reference to AQLib, create one instance of TracingHelper, call Initialize and redirect the event DbgHandler to your application. Two methods will help you to start or stop the trace capture - StartReading/StopReading.
The only cons of this method is when you run the project inside Visual Studio in Debug mode, the trace sentence will go to Visual Studio Output window instead of going to your application. To test it inside Visual Studio you will have to run it in the Release mode or Start without Debugging (Ctrl+F5 instead F5).
Demo solution
AQLib solution has three projects.
AQLib
.NET Managed C++ library to make use of the Oracle advance queue, it should work on any .NET language, if it doesn’t work on VB.NET or MC++ let me know.
Oracle AQ
It has a complete demo application on how to implement AQProducer, AQDispatcher, and AQConsumer in the three different modes, because I don’t know what kind of queues you have created, this project will read all the queues from your database, after you choose a DB queue you can create the C# file types, which will be compiled on the fly generating a new library DBTypes.dll, this library will contain all the Oracle DB types to map with the .NET world, this library can be used with any .NET language, if you are using C# then instead of adding a reference to the .NET DLL you could incorporate the DB type files directly to your project as shown in the example.
After the files are created you can choose which mode runs the AQProducer (single callback, dynamic AQConsumer creation or pre-instantiated AQConsumer). Also it incorporates a few lines necessary to make dynamic tracing work (remember to work you have to run it in the Release mode, outside Visual Studio or run it without debugging (Ctrl+F5).
TraceMonitor
This application is a separate application that shows how tracing can be captured from a different application other than the application where the AQLib is running. (Remember to work you have to run it in the Release mode, outside Visual Studio or run it without debugging (Ctrl+F5).) This library is still in the development stage, which means it has to still log in a log file, when exceptions are produced (you can search for the TODO string), but the missing stuff is not critical and I am pretty sure you can implement it the way you want.
AQLib is still not in production and it contains bugs, so some modifications can be expected in future releases. I hope it is useful for you. You can do whatever you want with it as long as the headers are not changed, which I think can be implemented by you. If it works for you do write a message here sharing your experience, which will help me improve this.
Performance
Using a Sun server running Oracle 9i with 2 GB of RAM and AQLib running on an average PC 2.8 GHz 1 GB RAM 100 MB network, it can process about 120 AQMessages in a second working on a single-callback method, but it is not very useful in production environments where every consumer takes about X seconds to do a task.
The same test done on a dynamic AQConsumer creation method with a limit of 50 consumers can dequeue and deliver around 150 AQMessages in a second, and the CPU usage is about 40%, that's pretty good as it can process more than half a million AQMessages each hour :).
Of course, the real performance is tested after a real work is done in the consumers, but an empty test shows us how the library can dequeue, map and deliver high volume data without performance loss.
Note: For now when the AQProducer is stopped all the messages in the dispatcher queue that were not processed will be lost, soon I'll change that to requeue those messages again in the queue. The source code is under Visual Source Safe, it gave some warning when I opened the solution, just click OK or Cancel to continue and make it work.

