Introduction
IPC (Inter Process Communication) has been covered by many other articles, so there is no real need for 'another' IPC article to show how to implement IPC. However, there was a severe lack of information of how to implement a fast IPC class. This is the purpose of this article.
Due to the availability of information already out there on IPC implementation, I will not dive too deeply on the inner workings of how to implement IPC, but will concentrate on how to make them very fast.
There are several ways to implement an IPC, here are just a few:
- Shared memory
- TCP
- Named Pipe
- File Mapping
- Mailslots
- MSMQ (Microsoft Queue Solution)
With so many choices, how is one to know the fastest? The answer is simple, there is no ideal fastest solution to the problem. Each has its advantages and disadvantages, but one most definitely stands out above the others....... Shared Memory.
Not only is the shared memory implementation one of the easiest to implement, it's also one of the fastest. Why would this be one of the fastest, I hear you ask? Minimal overhead. Overhead is generated whenever you make a call to another function. Be it a kernel or library, if your IPC makes no calls to any other function, then you've done away with a large bottleneck. Shared memory IPCs have no requirement for third party function calls.
So we now know one of the best and most widely used IPC implementations, now we just need to find one of the fastest ways of implementing it.
Updated
This article has been updated. The latest changes include the implementation of a circular linked list with read and write pointers. The changes were introduced to combat the problem of LIFO (Last In First Out). The previous implementation could only provide a transfer system that operated with a LIFO posting system due to the singly linked list design. This problem has how been rectified, with the added benefit of increased transfer rate. If you would like to skip the initial article, jump to the next updated header.
(Thanks for the ideas Jean!)
Background
In any IPC implementation, it's always best to derive a server/client approach to communication. Also, for simplicity, it's wise to have the communication one way, normally to the server. It's very easy to modify an IPC to perform two way communication. Simply create two IPC servers on both processes. Making your IPC communication one way allows you to concentrate on performance issues.
To write a fast shared memory IPC, you will need to implement several things.
Firstly, you need to have multiply blocks within the allocated memory. The reason you use more than one block is so that while a thread has CPU execution time, it has the ability to post lots of different blocks of data to the other threads without blocking. One of the fastest optimizations is batching your requests. To just post one block, then wait for a context switch for the server to process a single block, would be extremely inefficient. My implementation uses the following block structure:
struct Block
{
volatile LONG Next;
DWORD Amount;
BYTE Data[IPC_BLOCK_SIZE];
};
Secondly, you need some form of inter-process thread synchronization. Without it, multiple threads could write to the same block, resulting at best to data corruption, and worst, race conditions leading to deadlock (100% CPU usage). For my implementation, I use events, as these are very fast, much faster than semaphores or Mutexs:
HANDLE m_hMapFile;
HANDLE m_hSignal;
HANDLE m_hAvail;
Finally, you need some way of blocking thread execution on the server thread while it waits for data. One of the fastest is the WaitForSingleObject function call. My implementation uses this function and waits on the named events.
Most shared memory IPCs are implemented similar to the following:
Server
- Create named shared memory with N number of blocks of fixed size X
- Create inter-thread sync objects used to prevent simultaneous access blocks and race conditions
- Wait for a signal that blocks need to be processed
- Process the blocks and flag them as available again
- Go to step 3
Client
- Open named shared memory
- Wait for blocks to become available
- Write to blocks
- Signal that blocks needs to be processed
- Go to step 2
Fast Synchronization
One of the biggest problems with using shared memory is preventing multiple threads accessing blocks at the same time. We, therefore, need a way of only allowing one thread to access a block at a time.
The first hurdle you must overcome is deciding how you will organize your blocks. You must provide, effectively, two groups of blocks. One set is the blocks that are available for new data, while the second is the blocks that require processing. One very effective way of doing this is to create two double linked lists, one containing the blocks that are available for new data, while the other containing the blocks that requiring processing. The programmer would only, then, need to code in critical sections to protect the two lists. This method works very well, and is one of my very first implementations of IPCs. However, after implementing it, I was very much disappointed at the speed/bandwidth.
Using Critical Sections and double linked lists, I could only produce 40-50k block transfers per second on a 3.2Ghz P4, before I hit 100% CPU usage. Not very impressive.
So, what's the bottleneck here? Synchronization. Most of the wasted CPU time is down to entering and leaving critical sections, blocking CPU execution and thread context switching. One of the best advise I ever read was with the graphics engine design, "The fastest polygon is a polygon that isn't drawn". Applying this to the current context, the fastest critical section is no critical section at all. But if we don't use critical sections, how can we protect our lists? The answer is simple, use lists that are multi-thread safe..... single linked lists. Enter "InterlockedCompareExchange".
Now, originally, I used the InterlockedPopEntrySList and InterlockedPushEntrySList functions with single linked lists. However, I ran into quite a serious problem. At first, it seemed to work perfectly as I was testing the IPC server and IPC client within the same process; however, when testing the class on two separate processes, I ran into a big dilemma. Virtual memory.
Every block within a single linked list has to have a pointer to the next block. Now, if we dig into the SLIST_ENTRY, we see the following problem:
typedef struct _SLIST_ENTRY {
struct _SLIST_ENTRY* Next;
} SLIST_ENTRY, *PSLIST_ENTRY;
The standard Windows interlocked lists use memory pointers to the next block, but this is a serious problem when you use multiple processes, as the other process has a completely different memory address space. While the memory block pointer is valid under one thread context, as soon as it switches to the other, it's no longer valid, leading to access violations.
InterlockedPopEntrySList can't be used. But the concept can, we just need to rewrite the function so that it doesn't use pointers. This is where my block structure comes into play. If you look back at the definition, you'll notice that it has this:
volatile LONG Next;
The volatile syntax tells the compiler to make sure it doesn't use the CPU cache with this variable. If the CPU uses the cache, it could assume the Next pointer is some cached value, but another thread could have changed it between fetching the cache and using the variable. Also, note that the variable type is a LONG. This is because it's actually representing a distance in bytes within the entire mapped memory where the next block starts. This makes the next pointer relative to the current address space. We simply now need to write our own InterlockedPushEntrySList and InterlockedPopEntrySList functions for this new block structure. These are my implementations of the functions:
void osIPC::Client::postBlock(Block *pBlock)
{
LONG blockIndex = (PointerConverter(pBlock).ptrLong -
PointerConverter(&m_pBuf->m_Blocks).ptrLong)
/ sizeof(Block);
for (;;) {
LONG iFirst = pBlock->Next = m_pBuf->m_Filled;
if (InterlockedCompareExchange(&m_pBuf->m_Filled,
blockIndex, iFirst) == iFirst)
break;
}
SetEvent(m_hSignal);
};
osIPC::Block* osIPC::Client::getBlock(void)
{
for (;;) {
LONG blockIndex = m_pBuf->m_Available;
if (blockIndex == 0) return NULL;
Block *pBlock = m_pBuf->m_Blocks + blockIndex;
if (InterlockedCompareExchange(&m_pBuf->m_Available,
pBlock->Next, blockIndex) == blockIndex)
return pBlock;
}
};
m_pBuf is a pointer to the mapped memory which has the following structure:
struct MemBuff
{
volatile LONG m_Available;
volatile LONG m_Filled;
Block m_Blocks[IPC_BLOCK_COUNT];
};
The server will use very similar functions, but on opposing lists.
WaitForSingleObject and Signals
We are almost there. We now have two lists that both the client and the server can manipulate at the same time, with no possibility of multithreading issues. We now simply need to have a way of telling the client that blocks are now available for writing, and tell the server that blocks are available for processing.
This is simply done with Events and the WaitForSingleObject with appropriate timeouts. Once you have these and the lists, you've a very fast IPC that so long as both threads are getting sufficient CPU time, should never enter a blocking state or make any external function calls.
Speed
By now, you must be wondering how fast this implementation can really go. It's fast, very fast! Not only is the blocks per second rate very fast, but the bandwidth can be huge as long as you keep your code optimized.
On my 3.2Ghz P4 1024 MB RAM laptop, I recently measured these speeds:
Bandwidth Test (Packet Size: 3000 Bytes) -> 800,000,000 Bytes/Sec
Rate Test (Packet Size: 100 Bytes) -> 650,000 Packets/Sec

These figures really do speak for themselves, I've not seen any implementation that comes close. I've tested it on a dual core computer, with the client and server on separate CPUs, and got bandwidths of 1,000,000,000 Bytes/Sec and rates of 2,000,000 Packets / Sec!!!!!!
The most interesting performance gains are when you stress test it with multiple clients. As long as the block count is scaled with the number of clients, the total bandwidth is hardly affected with a moderate number of clients.
Problems?
There should be one glaring design flaw with this implementation? FIFO (First in first out). Double linked lists are used in other implementations for a very good reason, they allow the programmer to add blocks to the end of the list. This ensures that the first block added to the list will be the first block that's processed. Single linked lists only allow adding blocks to the front of the list, meaning the first block added will be the last block (FILO) that's processed. If blocks are added faster than they are processed, then that block that was added first could spend quite some time sitting in the list waiting to be processed, while new blocks get processed instead. If you know and understand this limitation, then that's OK, but what if this limitation is unacceptable, for example, let's say you are trying to duplicate the behavior of a local TCP connection. TCP connections have to guarantee FIFO.
The answer is simple. When the server processes blocks, simple create another single linked list and fill this first. When the server pops a block from the 'to be processed' list, it simply adds this block to the intermittent list before it's processed. As long as the server ensures it takes all the blocks out of the 'to be processed' list before going on to process the intermittent list as per usual, it will ensure that it's processing blocks in a FIFO fashion. Try and work it out in your head, you will see how it works.
Happy coding!
Updated
Introduced
The need for a FIFO has resulted in updating this document. As previously mentioned in the Problems section of this article, the existing implementation has a serious flaw, LIFO. It will only read the last block added to the list. They are not only reversed, but also jumbled up. This means all data posted to the IPC will become out of order, for most programs this is an unacceptable restriction.
My first plan to rectify this problem was to use another single linked list and push all the blocks into this list before processing them. This would result in the order being reversed. Although this method would have worked to some degree, it still has a major problem. If a block was added to the filled list before the second list is fully populated, this new block could appear anywhere between the start and the end. This would result in neither FIFO nor LIFO.
Comments from Jean and others pointed me towards another implementation I could try. Circular linked lists with read and write cursors. The IPC class would need complete rewriting to work with this model, so let's jump right into the concept.
Concept
First, let me explain what's being proposes. A double circular linked list is the equivalent of a double linked list, but with the start and end of the list pointing to each other. Effectively, if you were to try and transverse such a list, you would circle though every entry forever. E.g.:
We now introduce some read and write pointers. They must all follow some set rules:
- All pointers must never pass each other
- End pointers may equal start pointers (indicating zero data)
- Read and write pointers must never equal each other
What this design concept means is we can simultaneously have many blocks being written to while having many blocks being read at the same time. As long as there is space in front of the write start cursor, writing will never be blocked. Likewise, as long as there is space in front of the reading cursor, read operations will never block.
This design also deals with multiple reading and writing. The number of threads that can work on the same IPC is equal to the number of blocks held in it, this includes both reading and writing. The area where reading and writing is taking place (green and red area on the diagram) will only contain blocks that are owned by other threads, meaning they are multi-thread safe. Once a block has been retrieved, that thread effectively owns the block. The main advantage of this method is that this system now operates in a FIFO nature.
For performance reasons, we do not want to use any critical sections, mutex's, or other thread sync just like the existing implementation. This means, all operations to move the pointers must be performed atomically. I.e., they appear to complete in a single instruction from all other threads' perspective. This ensures the pointers are not corrupted by multiple threads trying to move the same read and write cursors forward.
OK. Let's dive into the code:
First, we must modify our data structures and setup the circular linked list. This is all done once the IPC server is created.
struct Block
{
LONG Next;
LONG Prev;
volatile LONG doneRead;
volatile LONG doneWrite;
DWORD Amount;
DWORD _Padding;
BYTE Data[IPC_BLOCK_SIZE];
};
We've made a few changes to this structure. Firstly, we've added a previous pointer that will point to the previous block in the circular list. Secondly, we've added doneRead and doneWrite flags. More on these later. We've also aligned everything to a 64 bit boundary. This is an optimization for 64 bit machines.
struct MemBuff
{
Block m_Blocks[IPC_BLOCK_COUNT];
volatile LONG m_ReadEnd;
volatile LONG m_ReadStart;
volatile LONG m_WriteEnd;
volatile LONG m_WriteStart;
};
We've moved the blocks array to the front of the shared memory buffer. This is a performance optimization so that we remove the offset that needs adding every time we reference a block.
All the singly linked lists have been removed and replaced with cursors (one for reading, one for writing).
Let's now build the circular linked list and set the default cursor positions (server initializing code).
int N = 1;
m_pBuf->m_Blocks[0].Next = 1;
m_pBuf->m_Blocks[0].Prev = (IPC_BLOCK_COUNT-1);
for (;N < IPC_BLOCK_COUNT-1; N++)
{
m_pBuf->m_Blocks[N].Next = (N+1);
m_pBuf->m_Blocks[N].Prev = (N-1);
}
m_pBuf->m_Blocks[N].Next = 0;
m_pBuf->m_Blocks[N].Prev = (IPC_BLOCK_COUNT-2);
m_pBuf->m_ReadEnd = 0;
m_pBuf->m_ReadStart = 0;
m_pBuf->m_WriteEnd = 1;
m_pBuf->m_WriteStart = 1;
The first block in the array is linked to the second and last block, likewise the last block is linked to the first and second to last block. This completes the circle.
We, then, set the read and write pointers. The start and end are equal because no read or write operations are currently taking place, also the read cursor is right behind the write cursor as no data has been added yet.
Now, we need to implement a method for adding data. This should move the writeStart pointer forward (but only if there's space to expand), thus increasing the gap between the writeStart and writeEnd cursors. Once this gap is expanded by the thread, the resulting block can be accessed, allowing data to be written to it.
for (;;)
{
LONG blockIndex = m_pBuf->m_WriteStart;
Block *pBlock = m_pBuf->m_Blocks + blockIndex;
if (pBlock->Next == m_pBuf->m_ReadEnd)
{
if (WaitForSingleObject(m_hAvail, dwTimeout) == WAIT_OBJECT_0)
continue;
return NULL;
}
if (InterlockedCompareExchange(&m_pBuf->m_WriteStart,
pBlock->Next, blockIndex) == blockIndex)
return pBlock;
continue;
}
First, we need to ensure the operation is atomic. To do this, the block index is recorded to be used by the InterlockedCompareExchange later on.
Next, we make sure the writeStart cursor will not pass any outstanding read operations (readEnd). If it would, then we need to wait for some space to become available. A timeout is provided in case the user does not wish to wait. This situation would occur if the IPC buffers have been completely filled with data.
The cursor is then moved forward using an InterlockedCompareExchange call. This makes sure the cursor was not modified by another thread while all the checks took place, the previously recorded value (blockIndex) is used as the reference. If the call is successful, the block is then returned.
Block *pBlock = getBlock(dwTimeout);
if (!pBlock) return 0;
DWORD dwAmount = min(amount, IPC_BLOCK_SIZE);
memcpy(pBlock->Data, pBuff, dwAmount);
pBlock->Amount = dwAmount;
postBlock(pBlock);
return 0;
This block of code does the actual data writing itself. Once the data is copied into the block, the thread gives up ownership of the block using the 'postBlock()' call. This will move the writeEnd cursor up, allowing read operations to take place on the data we've posted.
void osIPC::Client::postBlock(Block *pBlock)
{
pBlock->doneWrite = 1;
for (;;)
{
DWORD blockIndex = m_pBuf->m_WriteEnd;
pBlock = m_pBuf->m_Blocks + blockIndex;
if (InterlockedCompareExchange(&pBlock->doneWrite, 0, 1) != 1)
{
return;
}
InterlockedCompareExchange(&m_pBuf->m_WriteEnd,
pBlock->Next, blockIndex);
if (pBlock->Prev == m_pBuf->m_ReadStart)
SetEvent(m_hSignal);
}
};
Remember the flags we added to the block structure earlier? These are now used in the 'postBlock()' function call, one flag for reading and one for writing. This particular case uses the 'doneWrite' flag. The reason for the use of these flags is explained in detail below.
Without the 'doneWrite' flag, there is a serious problem. Imagine this situation. An outstanding block owned by a thread posts back a block. This block is not the first block in the 'write' section of the memory (i.e., it's not equal to m_WriteEnd). We, therefore, cannot move the writeEnd cursor forward. To do so would mean that another thread that actually owns the first block has lost its exclusive ownership, not to mention the problems that would occur if this other thread then tried to post back this very block that's already been taken into account. We therefore have delay moving the writeEnd cursor forward, leaving the responsibility of the cursor to the thread that owns the first block. But to signal that we've given up ownership of the block, we set this 'doneWrite' flag.
Without this 'doneWrite' flag, when it comes to actually moving the first block forward later on, there's no way of knowing if the rest of the blocks have been returned yet, hence the need for the flag. The flag is initialized to zero; once a block is returned, it's set to one. When the block is made available again by moving the writeEnd pointer forward, the flag is again zeroed (InterlockedCompareExchange).
The writeEnd pointer will be moved forward as far as the last block that's completed, i.e., all sequential blocks that have their 'doneWrite' flag set to one. Notice that by design, this also ensures that the writeEnd cursor can never pass the writeStart pointer.
Finally, we signal any threads that are waiting to read data.
We now have a way of filling blocks in the buffer, we just need a way of reading those blocks back again. Onto read operations:
osIPC::Block* osIPC::Server::getBlock(DWORD dwTimeout)
{
for (;;)
{
LONG blockIndex = m_pBuf->m_ReadStart;
Block *pBlock = m_pBuf->m_Blocks + blockIndex;
if (pBlock->Next == m_pBuf->m_WriteEnd)
{
if (WaitForSingleObject(m_hSignal,
dwTimeout) == WAIT_OBJECT_0)
continue;
return NULL;
}
if (InterlockedCompareExchange(&m_pBuf->m_ReadStart,
pBlock->Next, blockIndex) == blockIndex)
return pBlock;
continue;
}
};
void osIPC::Server::retBlock(osIPC::Block* pBlock)
{
pBlock->doneRead = 1;
for (;;)
{
DWORD blockIndex = m_pBuf->m_ReadEnd;
pBlock = m_pBuf->m_Blocks + blockIndex;
if (InterlockedCompareExchange(&pBlock->doneRead, 0, 1) != 1)
{
return;
}
InterlockedCompareExchange(&m_pBuf->m_ReadEnd,
pBlock->Next, blockIndex);
if (pBlock->Prev == m_pBuf->m_WriteStart)
SetEvent(m_hAvail);
}
};
DWORD osIPC::Server::read(void *pBuff, DWORD buffSize, DWORD dwTimeout)
{
Block *pBlock = getBlock(dwTimeout);
if (!pBlock) return 0;
DWORD dwAmount = min(pBlock->Amount, buffSize);
memcpy(pBuff, pBlock->Data, dwAmount);
retBlock(pBlock);
return dwAmount;
};
Notice that this implementation is also identical to the operation to write to blocks, except the cursors and flags are different. If you think about it, this makes sense as we are effectively doing the same thing, as in moving an area of blocks sequentially. We could, if we wanted, add another cursor somewhere between the read and write cursors that performs some other action. Obviously, this particular implementation has no need of this, but it could be useful to others.
That's basiclly all there is to it. We have the ability to write to blocks and the ability to read from them. All functions are multi-thread safe, they all use minimal overhead and don't block / pass CPU execution unless they have too.
We now have all the functionality needed to perform IPC communication quickly and in a FIFO fashion. Let's see how it performs!!!
Performance
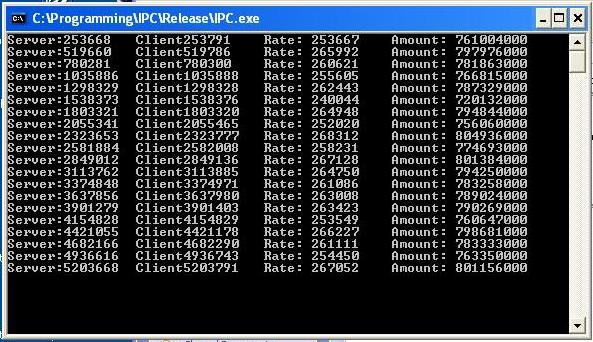
Bandwidth Test:
Transfer Rate Test:
The numbers all go up, so that's good!! Pay special attention to the increased transfer rate. Over 2 million block transfers a second! That's a huge transfer potential. Bandwidth is mainly restricted by the speed that data can be transferred onto and out of a block, i.e., the time it takes to complete the 'memcpy' call, but even with huge memory transfers, the IPC achieves well over 7.5 GBit/s. That's getting rather close to the physical RAM writing speed. To put this all in perspective, try putting a 'memcpy' call in a simple loop, and see what transfer rates you get. If you compare the overhead of this IPC implementation to the rest of a program, you will see it uses almost no overhead. The potential for more performance is only limited by the hardware itself.
With the best BSP tree I could write, I can only achieve two million BSP tree lookups a second, and with my best hash table, lookups of four million a second were observed. A simple loop that does almost nothing at all could only perform ten million iterations per second. The use of this IPC implementation can be regarded as almost CPU free.
In terms of memory consumption, only 2 MB of RAM is used regardless of how much you use the IPC. This memory usage can even be reduced by lowering the block count (IPC_BLOCK_COUNT) or the block size (IPC_BLOCK_SIZE). Memory fragmentation is impossible as all the memory blocks are in a continuous piece of memory. (This is also a benefit to the CPU cache.)
All this extra performance is a major bonus considering all we wanted to do was make the IPC operate in a FIFO nature!
I hope this code is of benefit to others. Happy coding!

