Introduction
In this article, I will describe the ways to handle errors accurately and without painful disturbance of a complex code. Most of the programmers don’t use error handling the way it should be, and also we ignore the error logs that need to be maintained. Why do we need these things? I will explain this as a beginner in this technique. There might be more good articles on it but the purpose of my article is to let beginners understand why, how, and when to use error handling and logs, with different scenarios.
Note:- English is not my native language so if I say something wrong, then apologies for it.
Background
When we write code in C++, we sometimes get errors like abnormal program termination, failure of some function, code corruption, etc. There is no error which can not be traced and tackled, but we programmers sometimes don’t use these facilities simply because of laziness or fear of code complexities.
C++ is a very strong language, and it gives fantastic solutions to track and destroy errors by the help of exceptional handling techniques like the usage of try, catch, and throw. But using a try-catch is an art, it isn’t required to put a try-catch on every single piece of code, which can affect the speed as well as make it difficult to understand the code.
Below is a picture which describes the purpose of the try-catch methodology:
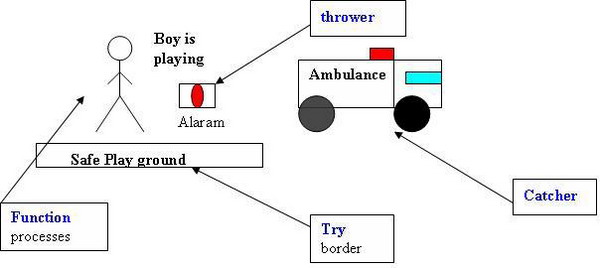
Here, we have a scenario where a boy is playing on a safe playground where an ambulance is there beside him. Also, the boy has an alarm which can help the boy if he gets hurt and then the ambulance will for sure take him to the hospital. This is what happens when we use a try-catch-throw mechanism. I am sure you will be wondering what the hell I have made in this diagram. Well, here I will explain this. The boy is actually a code inside the braces of a try which actually is like a safe playground. Suppose our code suddenly gets unstable and then unexpectedly the code finds some sort of error, then before doing anything else, it will just throw (the boy will push the alarm button) and the catch will catch the error (or just move the boy inside the ambulance and let him play anymore). Below is the code sample that shows how we can do this:
void main void()
{
try
{
Somefunction()
Somefunction2();
Somefunction3();
}
catch(somerror err)
{
}
}
void Somefunction2()
{
If(data<0)
throw someerrorobject;
}
Here, the code is inside the try block. In the second function, if something unexpected happens, before finishing Somefunction2, the main code gets the error and it throws it to the caller of that function. The thrower thinks here that you surely has defined its safe try block around its function call, otherwise an error will be shown like the one below. After that, the code will go directly in the block of its appropriate catch.

Using the code
Throw is a facility which can take a code out from its function scope, according to the coder’s requirement. Suppose I call some sort of Windows API function and it returns me an invalid value, then further moving forward, I just check the return type and throws an error according to my requirement.
Handling Win API functions
Suppose if I am calling RegOpenKey, it will return ERROR_SUCCESS on success, otherwise it will return something else. Now let's check this code ..
void Function1()
{
If( RegOpenKey(………,…….,…..) ==ERROR_SUCCESS)
{
}
else
{
throw " RegOpenKey failed";
}
}
void main(void)
{
try
{
Function1();
}
catch(char * errorword)
{
cout<< errorword;
}
}
The above example will display this message on screen: "RegOpenKey failed". Now you see we can track any error we want. We have to throw the things which we know can cause a problem. Why am I doing catch (char* errorword), because in my program, the error code or error word which I expect to be thrown is the character string or array, that’s why I am catching the term char*.
Handling multiple errors
In the above example, we assume that all the thrown data would be char* but what if you want to throw numbers as well as char*, then simply we append another catch options according to the particular type.
void function()
{
try
{
FunctionA()
FunctionB()
}
catch(char* data)
{
cout<<data;
}
catch(int id)
{
cout<<id;
}
Handling custom error objects
In previous examples, we knew the data type to be caught, but what if we are calling different Windows APIs or other SDK APIs and they throw some of their own customized objects? For this, I simply recommend reading their help or MSDN. Sometimes, we make our own classes and that class is made just for the error handling. Let’s create a sample error handler class to illustrate what I am trying to say.
Class ErrorHandle()
{
Public:
String m_FunctionName;
String m_ReasonofErr;
Int Error_id;
ErrorHandle(string strReason,strFunction,int d);
{
m_FunctionName= strFunction;
m_ReasonofErr = strReason;
Error_id = d;
}
~ErrorHandle();
}
Here we have our simple ErrorHandler class. Now, instead of throwing any other data from our side, we will use this object to be thrown.
int MyfunctionDivision(int data)
{
int return=1;
if(data<=0)
{
ErrorHandle obj("less than 1 cant be use for to divide numbers",
" MyfunctionDivision",data);
throw obj;
}
else
{
}
}
void main(void)
{
try
{
MyfunctionDivision(-1);
}
catch(ErrorHandle obj)
{
cout<<"Function Name:"<<obj. m_FunctionName;
cout<<"Reason of Error"<<obj.m_ ReasonofErr;
cout<< "Error data:"<<obj. Error_id;
}
}
This custom object has a lot of details, like it has the name of the function as well as the reason, plus the data by which the error came. So this custom class can have functions and attributes, and can be extended as much as you want. This approach is the recommended approach for catching errors. Of course, you don’t always need the functional error name, but need the function name, plus it would be much better if you know why this error came. Now, I simply check the value of Error_Id and understands that, by mistake it is obtaining the invalid data and that’s why the code is getting crashed. You see now how simple it is to handle these stupid errors. But remember that the type of the catcher should be the same as the thrower. Suppose if in the recent example, you throw a single integer error ID, it will catch nothing unless you specifically define a single ID catcher as well.
catch(ErrorHandle obj)
{
cout<<"Function Name:"<<obj. m_FunctionName;
cout<<"Reason of Error"<<obj.m_ ReasonofErr;
cout<< "Error data:"<<obj. Error_id;
}
catch(int id_anotherCodeeror)
{
Cout<< id_anotherCodeeror;
}
Handling unexpected or unknown errors
The above examples are all those where we know what kind of error types we will face, either integer or string, or any custom error handling class. For unexpected types of errors, we have to catch it by using a statement as “...”. In simple words, these three dots are meant to catch any type of error that occurs but they will not show any description of the error since we don’t know what type of error came. By this statement, we can understand that, inside our program something is getting crashed and it must be some other type which we don’t know yet.
void main(void)
{
try
{
MyfunctionDivision(-1);
}
catch(ErrorHandle obj)
{
cout<<"Function Name:"<<obj. m_FunctionName;
cout<<"Reason of Error"<<obj.m_ ReasonofErr;
cout<< "Error data:"<<obj. Error_id;
}
}
catch(ErrorHandle obj)
{
cout<<"Function Name:"<<obj. m_FunctionName;
cout<<"Reason of Error"<<obj.m_ ReasonofErr;
cout<< "Error data:"<<obj. Error_id;
}
catch(int id_anotherCodeeror)
{
cout<< id_anotherCodeeror;
}
catch(…)
{
cout<<"unexpected error came";
}
Now, this code can handle two types of errors. If a ErrorHandle object comes, the ErrorObject handler will process it. If an integer is thrown by the function, then the second catcher which has the integer type will handle it. But if anything other than ErrorHandle or an integer are thrown by any function inside the try block, then the last catch will show the message: “unexpected error came”. This is how we can track unexpected errors and then debug them one by one to destroy the bad errors.
Handling ATL/COM errors
It is not usual in Windows programming to use ATL/COM etc. Often, we face problems of unexpected errors when using COM objects. Suppose I am using the Microsoft ADO and initializing a database connection for an MDB file.
_ConnectionPtr g_pConPtr;
_CommandPtr g_pCPtr;
_RecordsetPtr g_pRPtr;
int OpenConnection()
{
string Path ;
Path = "DB\\mydatabasefile.mdb";
string CnnStr = "PROVIDER=Microsoft.Jet.OLEDB.4.0; DATA SOURCE=";
CnnStr+=Path;
CnnStr+=";USER ID=admin;PASSWORD=;Jet OleDB:Database Password = abcdefgh;";
CoInitialize(NULL);
try
{
g_pConPtr.CreateInstance(__uuidof(Connection));
if(SUCCEEDED(g_pConPtr ->Open(CnnStr.c_str(),"","",0)))
{
g_pRPtr.CreateInstance(__uuidof(Recordset));
g_pCPtr.CreateInstance(__uuidof(Command));
g_pCPtr ->ActiveConnection = g_pConPtr;
}
}
catch (...)
{
return 0;
}
return 1;
}
The code above crashed if the connection string is not valid, or if the initialization is not called, or because of any COM error which might come due to our wrong usage. Suppose the connection string CnnStr has a wrong path, then the COM error will be thrown inside its function calls. And it directly moves to the catch block. But still we won’t know what the error is and why the error came. To understand the COM error, Microsoft has given a very good class called _com_error . This class has many cool member functions like ErrorMessage() and Description(), and they can solve our COM error tensions easily without making things more complicated.
Now let's add a catch for all kinds of COM error handling:
try
{
g_pConPtr.CreateInstance(__uuidof(Connection));
if(SUCCEEDED(g_pConPtr ->Open(CnnStr.c_str(),"","",0)))
{
g_pRPtr.CreateInstance(__uuidof(Recordset));
g_pCPtr.CreateInstance(__uuidof(Command));
g_pCPtr ->ActiveConnection = g_pConPtr;
}
}
catch(_com_error &e)
{
string st = e.Description();
cout<<st;
}
catch (...)
{
return 0;
}
This time if the error comes, then the program will not go out quietly but will go inside the catch for _com_error and will show: "'F:\.........\DB\ mydatabasefile.mdb’ is not a valid path. Make sure that the path name is spelled correctly and that you are connected to the server on which the file resides." This is how the Microsoft class can describe the errors. Very simple and accurate, isn’t it?
Handling C++ STL exceptions
Like Microsoft _com_error, we have a custom class inside STL called exception, and it can be included with exception.h. Below is an example that shows how to tackle any kind of STL errors including those for vector, string, map etc.
#include <iostream>
#include <vector>
#include <algorithm>
#include <iterator>
#include <exception>
using namespace std;
int main () throw (exception)
{
vector<int> v(5);
fill(v.begin(),v.end(),1);
copy(v.begin(),v.end(),
ostream_iterator<int>(cout," "));
cout << endl;
try
{
for ( int i=0; i<10; i++ )
cout << v.at(i) << " ";
cout << endl;
}
catch( exception& e )
{
cout << endl << "Exception: "<< e.what() << endl;
}
cout << "End of program" << endl;
return 0;}
OUTPUT
// 1 1 1 1 1
// 1 1 1 1 1
// Exception: invalid vector subscript
// End of program
The Exception class’ function "what()" contains the description of the error which was recently got caught.
Ignore errors
Sometimes catch(…) is also used to ignore runtime errors or unexpected errors. This is a bad idea but sometimes it becomes necessary to use, and it all depends on the programmer’s code and logic.
Nested throw
Here I will show an example of nested functions throwing the error, and how the main caller can catch the errors and display them. We have two classes here, one is Sample1 and the other is Sample2. Sameple1 has a function DoSomeWork(). While Sample2 has four member functions.
class Sample2
{
public:
Sample2();
virtual ~Sample2();
void AddMoreData(int dt);
private:
void Function3(int);
void Function1(int);
void Function2(int);
};
class Sample1
{
public:
Sample1();
virtual ~Sample1();
void DoSomeWork();
};
Here, we have to implement a nested calling and throwing of bugs. For that, I have made AddMoreData(int) which will have its private member function call Function1(int).
void Sample2::AddMoreData(int dt)
{
if(dt<1)
throw "[AddMoreData](Invalid argument given)";
Function1(5);
}
void Sample2::Function1(int d)
{
if(d>10)
throw "problem in function 1";
Function2(4);
}
void Sample2::Function2(int d)
{
if(d<5)
throw "problem in function 2";
Function3(133);
}
void Sample2::Function3(int d)
{
if(d>100)
throw "problem in function 3";
}
void Sample1::DoSomeWork()
{
Sample2 Obj;
Obj.AddMoreData(2);
}
As you can see, the main caller in Sample2 is AddMoreData which actually calls Function1, and Function1() calls Function2(), and Function2() calls Function3(). Inside the main function, let's declare the object of Sample1. With our try-catch boundaries:
void main(void)
{
Sample1 Obj;
try
{
Obj.DoSomeWork();
}
catch(char* data)
{
cout<<data;
}
catch(...)
{
cout<<"unexpected Error";
}
}
After we run the above code, the Sample1 object will call the function DoSomeWork, and inside this function, it actually calls the function AddMoreData() of Sample2 which has nested function calls. Now at any place, if an error would occur, then it will be thrown and exits all the functions without finishing them and shows the result. The above example will show “problem in function 2”, and if the problem gets solved, then it has to call function3. So we have seen here however deep function calls exist, there is no problem in throwing errors from them and catching on the first layer where the first function gets called.
Note:- If I couldn’t explain this very well, then please just copy paste and try to run the program, and one by one, change the parameter values of Function1, Function2, and Function3.
Multiple throws
Multiple throw is a trick to throw any specific error between two or more try-catch boundaries. This can be made if the programmer needs to do something before letting the scope go out from a function call. Now, let's suppose we have two functions, function1() and function2(). Function1() is supposed to call function2(), but function1 should catch any error occurring inside function2(), and after catching it, process its own commands and then again throw that error to the main caller.
void function2();
void function1()
{
try
{
function2();
}
catch(char* errorDesc)
{
throw errorDesc;
}
}
void function2()
{
throw "we have got problem inside our second function";
}
void main(void)
{
try
{
function1();
}
catch(char* data)
{
cout<<data;
}
catch(...)
{
cout<<"unexpected Error";
}
}
The output of the above example will be "we have got problem inside our second function". So you can see function1 catch function2’s error and then process its final work before cleaning out from the memory scope, and then again throws the same error to the parent caller Main function. This is the way to throw multiple errors many times.
Handling window handles
Here we will stop talking about only the try-catch theory, and I will show you how to handle the basic Win32 window handle problems. Things to remember ...
- always close those handles which you have opened, e.g. registry handles, process handles etc.
- don’t try to close handle which don’t belong to your threads, e.g., if you get any specific desktop window handle, then its not your responsibility to close its handle because its owner is still alive.
- always use
NULL at the time of declaring any handle, and also after closing any handle or finishing the scope of any handle.
- always check the handle’s inner value before doing further operations with it.
- if you are playing with the handle which doesn’t belong to your own thread or window, then always check if it still exists or not.
HWND hd =NULL;
Hd = SomeApiFunctionReturnsHWND(........);
if(hd)
{
}
if(hd)
{
if(IsWindow(hd))
{
cout<< "yes window exist so lets work with it"
}
}
IsWindow(HWND) is a Win32 API function, and this function returns TRUE if the current HWND’s window currently exists, otherwise it will return FALSE. But be careful using this API function because window handles are recycled if the window gets destroyed, otherwise the old handle could even point to a different new window.
SendMessageTimeOut instead of SendMessage
Instead of sending messages, always use timeouts, because a simple SendMessage could make the program hang if the target window or class is in the blockage state of a thread. But if the SendMessageTimeOut API doesn’t get results till the supplied time, then it just gets back from the messaging API to the current program flow. For more information, please check MSDN.
Error logger
Error log is another part of bug tracking, and helps to understand the results more accurately in the shape of reports. Just create a class with error log member functions, like open file, close file, and write data in file, and call the open log file function in the constructor of the error log.
- Declare this object as a static in some empty header file like StdAfx.h or your own defined file.
- Now include all the .cpp files with the stdafx.h header or the header which you have made for static global objects.
- Now on every single
try-catch block, just call the “write log file” function by the static error log object.
#include "mystdfx.h"
void SomeClass::SoemFunction()
{
try
{
function1();
}
catch(char* data)
{
g_ErrorLogObj.writeLog(data);
}
catch(...)
{
g_ErrorLogObj.writeLog("unexpected error");
}
}
Complier macros for error logs
Writing to the file can cause loss in speed, so I mostly put the error log in debug mode and disable the error log in release mode. In this way, no streaming occurs and all the writing code just doesn’t get read by the compiler. For this, let's create our custom macro, this friend will help us do what I said.
- Define a macro as
#define MyErrorLogStart
- Now inside the function
writeLog of the ErrorLog class, just put the macro conditions like:
Void ErrorLog:writeLog(string str)
{
#ifdef MyErrorLogStart
……………….Writing inside the FILE or by stl streaming way
………………other log processes
#endif
}
Now suppose if I don’t want to write the log, then I simply delete the definition of MyErrorLogStart from my header. Otherwise, I will just use this header to let the compiler know that it is a must to use the writing function and processes of the error log. You can also put these macros at the time of opening the log file so it will never open the file in the absence of MyErrorLogStart.
Handling critical situations by flow logger
Flow logger is a way to understand the program’s Ins and Outs with all kinds of descriptions including its variable values, in the shape of a report. Simply use the typical error log, at the start of the function, at the end of the function, or in the middle of the function, whereever you feel to use.
void Myfunction()
{
g_ErrorLogObj.writeLog("Inside Myfunction()");
………… different functional processes
g_ErrorLogObj.writeLog("Outside Myfunction()");
}
GetLastError()
This Win32 function can help to extract error descriptions of a program, it simply returns the DWORD, and its value can be translated by the FormatMessage API function.
Conclusion
Overall, in this article, my idea was to give tricks and tell beginners how to make programs without errors. try-catch is the best methodology to be follow for a secure code, and error reporting is a good way to catch and destroy all kinds of errors. I am following the above tricks for two years, and I found them very effective to understand any program’s problems, and to kill bugs as much as I want. Hope my small piece of knowledge could help others in future.

