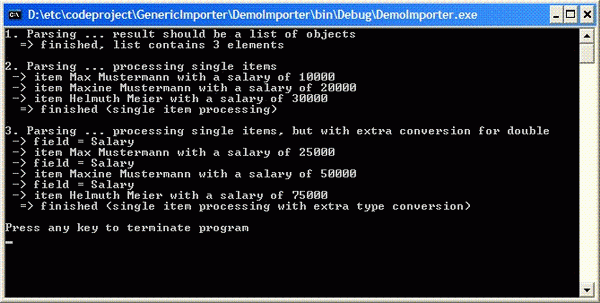
Introduction
I had to do an annoying job - once again, import text based data into objects. A dataset was not applicable, so I decided to use .net-Reflection and build an object list. The importer should handle user defined filters, type conversions, and split mechanisms, and - of course - different encoded files. On the other hand, I would like to have a "ready-to-use" solution without having to set a myriad of properties. My goal was to have a mechanism like this:
public class ImportDemo
{
public string EmployeeName;
public DateTime HiredSince;
public Double Salary;
}
...
...
var importer = new GenericTextImporter<ImportDemo>();
importer.ParseFile("myFile", out List<ImportDemo> dataList, bool hasBeenCanceled);
Background
Two things to mention here:
- The code doesn't turn its attention to speed. It is rather a question of whether the mechanism can be used as easily as possible by someone else for building import jobs. But, you can use it in a production environment, it's not too slow.
- My native language is German .... not English :-)
Behind the scenes ...
OK, now, let's have some details. The parser is very straight: read a line, split it via string.Split(), and convert column by column into the matching type of the member in the class.
First of all, we have to look at a condition in our class declaration:
public class GenericTextImporter<T>
where T: class
{
...
}
This makes sure that we can create instances of GenericTextImporter with objects only. We do not allow value types here. This condition is a must; otherwise, we cannot perform assignments like T item = null, because the compiler would not be able to decide whether it is a value or an object type (and will give us an error message).
using (StreamReader streamReader = new StreamReader(fileName, _fileEncoding));
The above opens the file to be read. The reader enables us to get the contents line by line with streamReader.ReadLine(). The property EnCsvImportColumnAssignMethod.ColumnAssignMethod allows to change the mapping between the text column and the object member. At the moment, only EnCsvImportColumnAssignMethod.FieldSequenceDefinesOrder has been implemented, but adding a mapping is not really hard to do.
As is common, the file will be read in a loop. For every line the parser gets, it has to do several steps:
- Split the line into pieces (columns).
- Create an instance of the object to be filled.
- Convert strings into the type of the member and assign it.
Splitting the line is done with the string.Split() function - the default separator is a comma, but you can use whatever you want. Also, an array of split chars is supported. In some cases, this is sufficient, but sometimes, you need more control. This will be explained later in this article.
Creating an instance of a class is easy, too:
T item = Activator.CreateInstance<T>;
The activator creates an instance of T ... remember, that's the type we've used during the construction of our class.
So, the last thing is - how to assign the member value. To get the relevant information of our destination class, the parser contains an important member:
FieldInfo[] _fieldInfo = typeof(T).GetFields(BindingFlags.NonPublic |
BindingFlags.Instance | BindingFlags.Public);
This will generate all the information we will need later. Depending on ColumnAssignMethod, the parser calls an assign method; in our case, AssignColumnValuesAnonymous.
private bool AssignColumnValuesAnonymous(string[] values, T item)
{
var result = true;
for (var i = 0; i < values.Length; i++)
{
result = i < _fieldInfo.Length && AssignFieldValue(_fieldInfo[i], values[i], item);
if (!result) break;
}
return result;
}
The code loops through all the values and assigns each to a member of the instance.
private bool AssignFieldValue(FieldInfo fieldInfo, string value, T item)
{
try
{
switch (fieldInfo.FieldType.FullName)
{
case "System.Net.IPAddress":
fieldInfo.SetValue(item, ConvertIPAddress == null ?
System.Net.IPAddress.Parse(value) :
ConvertIPAddress(fieldInfo, value));
break;
.....
}
}
FieldInfo contains some very interesting methods. fieldInfo.SetValue(destinationObject, value) allows us to set the value (you can read them with GetValue()). Remember: we build the field info at the beginning of our class with:
FieldInfo[] _fieldInfo = typeof(T).GetFields(..);
The only thing we have to do now is convert the string value (representing a column value in line) to the field type and assign it. Most types in .NET provide a .Parse() method that can be used.
The most common type conversions have been added to the parser. But, there are some cases where the built-in conversion will fail. This topic will be discussed later on in this article.
User defined splitter
As mentioned earlier, the string.Split() method will be used for getting pieces of the line. But now, let's imagine the following scenario: The separator char is comma (by default), and we want to import the following line:
"Mustermann, Max", 2008-01-01, 1000
Oops ... what happens ... the parser will detect four columns (split by the comma), but our class contains only three members. To solve this issue, there's a callback defined:
public delegate string[] LineSplitterDelegate(string aLine);
public event LineSplitterDelegate LineSplitter;
This enables you to hook into the parser and define your own split algorithm. In our case, we have to write a small piece of code that would quote the commas inside a string. The hook delivers a string array of split values back.
User defined type conversion
Now, we will take a deeper look at the type conversion. Normally, the parser calls the built-in conversion of a type, and this method normally is named type.Parse(string). For most cases, this will be enough, but let's have a look at the following scenario:
public class ImportDemo2
{
public string EmployeeName;
public DateTime HiredSince;
public Double Salary;
public bool HasCompanyStocks;
}
and we want to import the following line:
"Mustermann, Max", 2008-01-01, 1000, JA
The German "JA" (yes) could not be parsed and converted to a boolean value (in this case, "true").
public delegate System.Boolean
ConvertBooleanDelegate(FieldInfo fieldInfo, string value);
public event ConvertBooleanDelegate ConvertBoolean;
Using this hook, we can easily add a small converter that does exactly what we want.
importer.ConvertBoolean += myBooleanConverter;
...
private bool myBooleanConverter(FieldInfo fieldInfo, string value)
{
switch (value.ToLower())
{
case 'ja':
case 'yes':
case 'wahr':
case 'true':
return true;
default:
return false;
}
}
Every time the parser tries to convert a boolean, this function will be called.
The following types are supported at the moment:
System.Net.IPAddress System.String System.Char System.Int16 System.Int32 System.Int64 System.UInt16 System.UInt32 System.UInt64 System.Decimal System.Double System.DateTime System.TimeSpan System.Guid System.Boolean
If you look at this list, you may wonder why a string conversion hook has been implemented. The answer is simple: this allows you to implement advanced value handling. Let's take the example from above:
"Mustermann, Max", 2008-01-01, 1000, JA
At the moment, the first column contains a name with the order "lastname, firstname", and contains '"', but your imported value should be in "firstname-lastname" order, without a comma and the quotes. Simply assign the hook event to add your own converter, and that's it.
importer.ConvertString += myStringConverter;
...
private bool myStringConverter(FieldInfo fieldInfo, string value)
{
if (fieldInfo.Name != "EmployeeName") return value;
string[] values = value.Trim(new char[]{ '"' }).Split(new char[]{ '"' });
return values[1] + " " + values[0];
}
User defined filter
This works similar to the above mentioned hook. First, here's the declaration:
public delegate bool ItemFilterDelegate(T item);
public event ItemFilterDelegate ItemFilter;
To get the item into the list, simply return true. Inside the filter hook, you can do whatever you want. Please note that the filter will only be called if no ItemProcessor (see next chapter) has been defined.
Single item processing
Sometimes, I had to import a long list. The problem was not the time consumption, but memory. So, I implemented an alterable switch:
public delegate void ItemProcessorDelegate(T item, out bool cancel);
public event ItemProcessorDelegate ItemProcessor;
This allows you to work with a single item. After processing it (in your routine), it will go to the .NET nirvana of GC (garbage collection). To avoid permanent creation / deletion of items, you can define:
public delegate void ItemProcessorResetDelegate(T item);
public event ItemProcessorResetDelegate ItemReset;
In this case, the parser uses the same instance of the object, but it's your responsibility to cleanup the values.
Error handling
The parser returns true/false to notify the caller whether it was successful or not. In case of an error, you can take a look at LastError to get an idea of what went wrong.
In the case of type conversion errors, you can influence the behaviour with this property:
public enum EnErrorBehaviour
{
Ignore,
StopParsing,
SkipElement
}
After the parsing has been finished, you should inspect (depending on your settings) whether the property RejectedLines has a value different from zero.
Conclusion
Reflection is, of course, much, much more than I have used in this small piece of software. But, maybe, you've got an idea of how easily information about types can be used to make standard jobs more easy and less work. I hope you enjoyed the article. Please feel free to write into the forum, or to email me.
Points of interest
Reflection is easy.
In a near future version, the column / field mapping will be enhanced (via attributes). At the moment, the order of members and columns is identical.
History
- 2012-06-23 - Rewrite of code parts, put importer into an own assembly, c# 4.0 support, text updated
- 2008-09-16 - Updated, hope it's more readable. Some smaller text errors fixed.
- 2008-03-04 - Updated, problems displaying < and > in code fragments solved.
- 2008-03-03 - Updated, example added, officially published.
- 2008-02-12 - First version.

