Introduction
Introduction
Many a times, when we convert the computation code to SIMD using intrinsic, the SIMD code take more time and effort to write and it is unreadable and harder to maintain, compared to the scalar code. We do have to maintain a version of scalar code so that the application can fallback on when executed on a system without the SIMD support. More often than not, we discovered, to our dismay, the vectorized code is lower in performance. It is one thing to use well-optimized SIMD library and another to hand-code our own library using SIMD. In this article, we will introduce some SIMD vector class and their overloaded operators (+,-,*,/) that shipped with Visual C++ (the class are actually from Intel C++ Libraries) to ease our SIMD writing and lessen the effort to write readable SIMD code. Would you rather read/write z = x + y; or z = _mm_add_ps(x, y);? The answer is obvious. In this way, we can throw away our hand-written vectorized code without much heart pain in the event that they are found to be slower in execution.
Simple Example
Let me illustrate with an simple example of using SSE (not SSE2) float vector class, F32vec4, for integer to do addition of four numbers. F32vec4 is defined in the fvec.h header.
F32vec4 vec1(1.0f, 2.0f, 3.0f, 4.0f);
F32vec4 vec2(5.0f, 6.0f, 7.0f, 8.0f);
F32vec4 result = vec1 + vec2;
Without using the F32vec4 class and using pure SSE intrinsic, the code would be as follows. As you can see, using intrinsic, we have to either remember them or look them up in the documentation whenever we need to use them. For those who are looking into delaying the onset of dementia or Alzheimer, can try memorizing those hard-to-remember intrinsic names.
__m128 vec1 = _mm_set_ps(1.0f, 2.0f, 3.0f, 4.0f);
__m128 vec2 = _mm_set_ps(5.0f, 6.0f, 7.0f, 8.0f);
__m128 result = _mm_add_ps(vec1, vec2);
Below is the table which lists the vector classes and their associated header files from Optimizing software in C++ ebook.
| Vector class | Size of each element, bits | Number of elements | Type of elements | Total size of vector, bits | Header file |
Is8vec8 | 8 | 8 | char | 64 | ivec.h |
Iu8vec8 | 8 | 8 | unsigned char | 64 | ivec.h |
Is16vec4 | 16 | 4 | short int | 64 | ivec.h |
Iu16vec4 | 16 | 4 | unsigned short int | 64 | ivec.h |
Is32vec2 | 32 | 2 | int | 64 | ivec.h |
Iu32vec2 | 32 | 2 | unsigned int | 64 | ivec.h |
I64vec1 | 64 | 1 | __int64 | 64 | ivec.h |
Is8vec16 | 8 | 16 | char | 128 | dvec.h |
Iu8vec16 | 8 | 16 | unsigned char | 128 | dvec.h |
Is16vec8 | 16 | 8 | short int | 128 | dvec.h |
Iu16vec8 | 16 | 8 | unsigned short int | 128 | dvec.h |
Is32vec4 | 32 | 4 | int | 128 | dvec.h |
Iu32vec4 | 32 | 4 | unsigned int | 128 | dvec.h |
I64vec2 | 64 | 2 | __int64 | 128 | dvec.h |
F32vec4 | 32 | 4 | float | 128 | fvec.h |
F64vec2 | 64 | 2 | double | 128 | dvec.h |
F32vec8 | 32 | 8 | float | 256 | dvec.h |
F64vec4 | 64 | 4 | double | 256 | dvec.h |
Optimizing software in C++: It is not recommended to use the 64-bit vectors in ivec.h because these are incompatible with floating point code. If you do use the 64-bit vectors then you have to execute _mm_empty() after the 64-bit vector operations and before any floating point code. The 128-bit vectors do not have this problem. The 256-bit vectors require that the AVX instruction set is supported by the microprocessor and the operating system.
Most of the integer vector class do not support vector multiplication operations and all integer vector class do not support vector division operations, while float and double vector class do support vector addition, subtraction, multiplication and division. Here is an example to implement your own integer (32bit) division operator using the scalar division. And of course, using scalar operation will be slower.
static inline Is32vec4 operator / (Is32vec4 const & a, Is32vec4 const & b)
{
Is32vec4 ans;
ans[0] = a[0] / b[0];
ans[1] = a[1] / b[1];
ans[2] = a[2] / b[2];
ans[3] = a[3] / b[3];
return ans;
}
Drawing a Circle
We will use the F32vec4 class (128 bit float vector) to draw a circle. I'll show a plain scalar C++ code to do it first.
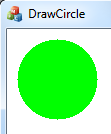

The code uses Pythagorean theorem to determine if the pixel falls within the circle. Using X and Y coordinates from the center of the circle, we calculate the hypotenuse, using sqrt(X2+Y2). The hypotenuse is the pixel distance from the center point. If it is smaller than the radius, then it is within the circle and the pixel should be set to green color.
void CScratchPadDlg::OnPaint()
{
if( !pixelsCanvas )
return;
UINT col = 0;
int stride = bitmapDataCanvas.Stride >> 2;
float fPointX = 100.0f; float fPointY = 100.0f; float fRadius = 40.0f;
float fy=0.0f;
float fx=0.0f;
UINT color = 0xff00ff00;
for(UINT row = 0, fy=0.0f; row < bitmapDataCanvas.Height; row+=1, fy+=1.0f)
{
for(col = 0, fx=0.0f; col < bitmapDataCanvas.Width; col+=1, fx+=1.0f)
{
int index = row * stride + col;
float X = fx - fPointX;
float Y = fy - fPointY;
X = X * X;
Y = Y * Y;
float hypSq = X + Y;
float hyp = std::sqrt(hypSq);
UINT origPixel = pixelsCanvas[index];
if(hyp<=fRadius)
{
pixelsCanvas[index] = color;
}
else
{
pixelsCanvas[index] = origPixel;
}
}
}
graphics.DrawImage(m_pSrcBitmap,0,0,
m_pSrcBitmap->GetWidth(),m_pSrcBitmap->GetHeight());
}
I have to admit this is an inefficient way to draw circle. A better and faster way is to draw a circle with a stroke and then use floodfill to fill the circle with a solid color. And there is also no antialiasing at the circle boundary. Our demo at the end requires circles to be drawn in such a way.
Below is the version written with intrinsic (not using F32vec4 yet). I will not try to explain this intrinsic version but I'll explain the F32vec4 version. Both version are similar.
void CScratchPadDlg::OnPaint()
{
UINT col = 0;
int stride = bitmapDataCanvas.Stride >> 2;
float fPointX = 100.0f; float fPointY = 100.0f; float fRadius = 40.0f;
__m128 vecPointX = _mm_set_ps1(fPointX);
__m128 vecPointY = _mm_set_ps1(fPointY);
__m128 vecRadius = _mm_set_ps1(fRadius);
float fy=0.0f;
float fx=0.0f;
UINT color = 0xff00ff00;
for(UINT row = 0, fy=0.0f; row < bitmapDataCanvas.Height; row+=1, fy+=1.0f)
{
for(col = 0, fx=0.0f; col < bitmapDataCanvas.Width; col+=4, fx+=4.0f)
{
int index = row * stride + col;
__m128 vecX= _mm_set_ps(fx+3.0f, fx+2.0f, fx+1.0f, fx+0.0f);
__m128 vecY = _mm_set_ps1(fy);
vecX = _mm_sub_ps(vecX, vecPointX);
vecY = _mm_sub_ps(vecY, vecPointY);
vecX = _mm_mul_ps(vecX, vecX);
vecY = _mm_mul_ps(vecY, vecY);
__m128 vecHypSq = _mm_add_ps(vecX, vecY);
__m128 vecHyp = _mm_sqrt_ps(vecHypSq);
__m128 mask = _mm_cmple_ps(vecHyp, vecRadius);
if(col+3<bitmapDataCanvas.Width)
{
UINT origPixel = pixelsCanvas[index+0];
pixelsCanvas[index+0] = color & (__m128(mask)).m128_u32[0];
pixelsCanvas[index+0] |= origPixel & ~((__m128(mask)).m128_u32[0]);
origPixel = pixelsCanvas[index+1];
pixelsCanvas[index+1] = color & (__m128(mask)).m128_u32[1];
pixelsCanvas[index+1] |= origPixel & ~((__m128(mask)).m128_u32[1]);
origPixel = pixelsCanvas[index+2];
pixelsCanvas[index+2] = color & (__m128(mask)).m128_u32[2];
pixelsCanvas[index+2] |= origPixel & ~((__m128(mask)).m128_u32[2]);
origPixel = pixelsCanvas[index+3];
pixelsCanvas[index+3] = color & (__m128(mask)).m128_u32[3];
pixelsCanvas[index+3] |= origPixel & ~((__m128(mask)).m128_u32[3]);
}
else {
UINT origPixel = pixelsCanvas[index+0];
pixelsCanvas[index+0] = color & (__m128(mask)).m128_u32[0];
pixelsCanvas[index+0] |= origPixel & ~((__m128(mask)).m128_u32[0]);
if(col+1<bitmapDataCanvas.Width)
{
origPixel = pixelsCanvas[index+1];
pixelsCanvas[index+1] = color & (__m128(mask)).m128_u32[1];
pixelsCanvas[index+1] |= origPixel & ~((__m128(mask)).m128_u32[1]);
}
if(col+2<bitmapDataCanvas.Width)
{
origPixel = pixelsCanvas[index+2];
pixelsCanvas[index+2] = color & (__m128(mask)).m128_u32[2];
pixelsCanvas[index+2] |= origPixel & ~((__m128(mask)).m128_u32[2]);
}
if(col+3<bitmapDataCanvas.Width)
{
origPixel = pixelsCanvas[index+3];
pixelsCanvas[index+3] = color & (__m128(mask)).m128_u32[3];
pixelsCanvas[index+3] |= origPixel & ~((__m128(mask)).m128_u32[3]);
}
}
}
}
graphics.DrawImage(m_pSrcBitmap,0,0,
m_pSrcBitmap->GetWidth(),m_pSrcBitmap->GetHeight());
}
Below is the code written with F32vec4 class provided by Microsoft Visual Studio. In fact, I wrote the vector class version first, then wrote the scalar and SIMD intrinsic version. It's easier to convert the vector class version to the intrinsic version: I only have to look up the intrinsic name inside the vector class overloaded operators and replace them accordingly.
void CScratchPadDlg::OnPaint()
{
UINT col = 0;
int stride = bitmapDataCanvas.Stride >> 2;
float fPointX = 100.0f; float fPointY = 100.0f; float fRadius = 40.0f;
F32vec4 vecPointX(fPointX);
F32vec4 vecPointY(fPointY);
F32vec4 vecRadius(fRadius);
float fy=0.0f;
float fx=0.0f;
UINT color = 0xff00ff00;
for(UINT row = 0, fy=0.0f; row < bitmapDataCanvas.Height; row+=1, fy+=1.0f)
{
for(col = 0, fx=0.0f; col < bitmapDataCanvas.Width; col+=4, fx+=4.0f)
{
int index = row * stride + col;
F32vec4 vecX(fx+3.0f, fx+2.0f, fx+1.0f, fx+0.0f);
F32vec4 vecY((float)(fy));
vecX -= vecPointX;
vecY -= vecPointY;
vecX = vecX * vecX;
vecY = vecY * vecY;
F32vec4 vecHypSq = vecX + vecY;
F32vec4 vecHyp = sqrt(vecHypSq);
F32vec4 mask = cmple(vecHyp, vecRadius);
if(col+3<bitmapDataCanvas.Width)
{
UINT origPixel = pixelsCanvas[index+0];
pixelsCanvas[index+0] = color & (__m128(mask)).m128_u32[0];
pixelsCanvas[index+0] |= origPixel & ~((__m128(mask)).m128_u32[0]);
origPixel = pixelsCanvas[index+1];
pixelsCanvas[index+1] = color & (__m128(mask)).m128_u32[1];
pixelsCanvas[index+1] |= origPixel & ~((__m128(mask)).m128_u32[1]);
origPixel = pixelsCanvas[index+2];
pixelsCanvas[index+2] = color & (__m128(mask)).m128_u32[2];
pixelsCanvas[index+2] |= origPixel & ~((__m128(mask)).m128_u32[2]);
origPixel = pixelsCanvas[index+3];
pixelsCanvas[index+3] = color & (__m128(mask)).m128_u32[3];
pixelsCanvas[index+3] |= origPixel & ~((__m128(mask)).m128_u32[3]);
}
else {
UINT origPixel = pixelsCanvas[index+0];
pixelsCanvas[index+0] = color & (__m128(mask)).m128_u32[0];
pixelsCanvas[index+0] |= origPixel & ~((__m128(mask)).m128_u32[0]);
if(col+1<bitmapDataCanvas.Width)
{
origPixel = pixelsCanvas[index+1];
pixelsCanvas[index+1] = color & (__m128(mask)).m128_u32[1];
pixelsCanvas[index+1] |= origPixel & ~((__m128(mask)).m128_u32[1]);
}
if(col+2<bitmapDataCanvas.Width)
{
origPixel = pixelsCanvas[index+2];
pixelsCanvas[index+2] = color & (__m128(mask)).m128_u32[2];
pixelsCanvas[index+2] |= origPixel & ~((__m128(mask)).m128_u32[2]);
}
if(col+3<bitmapDataCanvas.Width)
{
origPixel = pixelsCanvas[index+3];
pixelsCanvas[index+3] = color & (__m128(mask)).m128_u32[3];
pixelsCanvas[index+3] |= origPixel & ~((__m128(mask)).m128_u32[3]);
}
}
}
}
graphics.DrawImage(m_pSrcBitmap,0,0,m_pSrcBitmap->GetWidth(),m_pSrcBitmap->GetHeight());
}
The benchmark result is as below.
Intel i7 CPU (Quad Core)
Debug Mode
Scalar : 12ms
SSE Intrinsic : 5ms
SSE vector class : 38ms.
Release Mode
Scalar : 2ms
SSE Intrinsic : 1ms
SSE vector class : 1ms.
Core 2 Duo CPU (Dual Core)
Debug Mode
Scalar : 18ms
SSE Intrinsic : 5ms
SSE vector class : 57ms.
Release Mode
Scalar : 4ms
SSE Intrinsic : 1ms
SSE vector class : 1ms.
As the reader can see, the benchmark result for the SSE vector in debug build is very bad and is not acceptable for our demo application which animates the expanding circle on a interval of 30 milliseconds. The reason is probably because in debug build, the inline constructor and methods are not inline'd by the compiler. I work around it by always running the program in release mode. After all, it is a simple graphics program which does not need debugging, I figure out what is wrong by observing.
Now I begin to explain the previous code snippet.
float fPointX = 100.0f; float fPointY = 100.0f; float fRadius = 40.0f;
F32vec4 vecPointX(fPointX);
F32vec4 vecPointY(fPointY);
F32vec4 vecRadius(fRadius);
This code merely initialize the two vector of X coordinates and Y coordinates of the circle center. The third vector is circle radius.
float fy=0.0f;
float fx=0.0f;
UINT color = 0xff00ff00;
for(UINT row = 0, fy=0.0f; row < bitmapDataCanvas.Height; row+=1, fy+=1.0f)
{
for(col = 0, fx=0.0f; col < bitmapDataCanvas.Width; col+=4, fx+=4.0f)
{
int index = row * stride + col;
F32vec4 vecX(fx+3.0f, fx+2.0f, fx+1.0f, fx+0.0f);
F32vec4 vecY((float)(fy));
This is a nested for loop. The outer loop iterates the rows while the inner loop iterates every 4 columns. vecX and vecY are the columns and rows of the pixels. You may have noticed that the float arguments to vecX constructor is reversed. This is due to little endianness of Intel processor. Below is what it looks like if they are not reversed.
vecX -= vecPointX;
vecY -= vecPointY;
vecX = vecX * vecX;
vecY = vecY * vecY;
F32vec4 vecHypSq = vecX + vecY;
F32vec4 vecHyp = sqrt(vecHypSq);
Now we subtract the circle center from the XY coordinates of the pixels to get where the pixels are in relative to te circle center. We may get a negative X or Y result but we do not have to convert them to the absolute value because the next multiplication operation to compute for the squared value (e.g., X2, Y2), will convert negative values to positive values because the product of two negative numbers gives a positive result. The rest of the code computes the hypotenuse.
F32vec4 mask = cmple(vecHyp, vecRadius);
The first statement generates a mask if the hypotenuse of the triangle is less than the circle radius. The mask is all ones (0xffffffff) when the condition is true, else is all zeroes
if(col+3<bitmapDataCanvas.Width)
{
UINT origPixel = pixelsCanvas[index+0];
pixelsCanvas[index+0] = color & (__m128(mask)).m128_u32[0];
pixelsCanvas[index+0] |= origPixel & ~((__m128(mask)).m128_u32[0]);
origPixel = pixelsCanvas[index+1];
pixelsCanvas[index+1] = color & (__m128(mask)).m128_u32[1];
pixelsCanvas[index+1] |= origPixel & ~((__m128(mask)).m128_u32[1]);
origPixel = pixelsCanvas[index+2];
pixelsCanvas[index+2] = color & (__m128(mask)).m128_u32[2];
pixelsCanvas[index+2] |= origPixel & ~((__m128(mask)).m128_u32[2]);
origPixel = pixelsCanvas[index+3];
pixelsCanvas[index+3] = color & (__m128(mask)).m128_u32[3];
pixelsCanvas[index+3] |= origPixel & ~((__m128(mask)).m128_u32[3]);
}
else {
UINT origPixel = pixelsCanvas[index+0];
pixelsCanvas[index+0] = color & (__m128(mask)).m128_u32[0];
pixelsCanvas[index+0] |= origPixel & ~((__m128(mask)).m128_u32[0]);
if(col+1<bitmapDataCanvas.Width)
{
origPixel = pixelsCanvas[index+1];
pixelsCanvas[index+1] = color & (__m128(mask)).m128_u32[1];
pixelsCanvas[index+1] |= origPixel & ~((__m128(mask)).m128_u32[1]);
}
if(col+2<bitmapDataCanvas.Width)
{
origPixel = pixelsCanvas[index+2];
pixelsCanvas[index+2] = color & (__m128(mask)).m128_u32[2];
pixelsCanvas[index+2] |= origPixel & ~((__m128(mask)).m128_u32[2]);
}
if(col+3<bitmapDataCanvas.Width)
{
origPixel = pixelsCanvas[index+3];
pixelsCanvas[index+3] = color & (__m128(mask)).m128_u32[3];
pixelsCanvas[index+3] |= origPixel & ~((__m128(mask)).m128_u32[3]);
}
}
The first if condition test whether column + 3 is less than the image width. If it is, it will assign the color to the pixelCanvas[i] according if the mask is 0xffffffff. If mask is all zeros, the original color will be applied to pixelCanvas[i] instead. The else block executes when column + 3 is more than the image width and we have to test every pixel whether it is within the boundary before assigning the color to pixelCanvas[i].
Out of curiosity, I modified the earlier code snippet to draw a circle with a gradient. You noticed the gradients color 'spiked' into the center. This is okay because our final demo does not involve gradients.
void CScratchPadDlg::OnPaint()
{
UINT col = 0;
int stride = bitmapDataCanvas.Stride >> 2;
float fPointX = 50.0f; float fPointY = 50.0f; float fRadius = 40.0f;
F32vec4 vecPointX(fPointX, fPointX, fPointX, fPointX);
F32vec4 vecPointY(fPointY, fPointY, fPointY, fPointY);
F32vec4 vecRadius(fRadius, fRadius, fRadius, fRadius);
float fy=0.0f;
float fx=0.0f;
UINT color = 0xff0000ff;
UINT color2 = 0xff00ffff;
UINT* arrGrad = GenGrad(color, color2, 40);
for(UINT row = 0, fy=0.0f; row < bitmapDataCanvas.Height; row+=1, fy+=1.0f)
{
for(col = 0, fx=0.0f; col < bitmapDataCanvas.Width; col+=4, fx+=4.0f)
{
int index = row * stride + col;
F32vec4 vecX(fx+3.0f, fx+2.0f, fx+1.0f, fx+0.0f);
F32vec4 vecY(fy, fy, fy, fy);
vecX -= vecPointX;
vecY -= vecPointY;
vecX = vecX * vecX;
vecY = vecY * vecY;
F32vec4 vecHypSq = vecX + vecY;
F32vec4 vecHyp = sqrt(vecHypSq);
F32vec4 mask = cmple(vecHyp, vecRadius);
if(col+3<bitmapDataCanvas.Width)
{
UINT origPixel = pixelsCanvas[index+0];
pixelsCanvas[index+0] =
arrGrad[ (int)((__m128(vecHyp)).m128_f32[0]) ] & (__m128(mask)).m128_u32[0];
pixelsCanvas[index+0] |= origPixel & ~((__m128(mask)).m128_u32[0]);
origPixel = pixelsCanvas[index+1];
pixelsCanvas[index+1] =
arrGrad[ (int)((__m128(vecHyp)).m128_f32[1]) ] & (__m128(mask)).m128_u32[1];
pixelsCanvas[index+1] |= origPixel & ~((__m128(mask)).m128_u32[1]);
origPixel = pixelsCanvas[index+2];
pixelsCanvas[index+2] =
arrGrad[ (int)((__m128(vecHyp)).m128_f32[2]) ] & (__m128(mask)).m128_u32[2];
pixelsCanvas[index+2] |= origPixel & ~((__m128(mask)).m128_u32[2]);
origPixel = pixelsCanvas[index+3];
pixelsCanvas[index+3] =
arrGrad[ (int)((__m128(vecHyp)).m128_f32[3]) ] & (__m128(mask)).m128_u32[3];
pixelsCanvas[index+3] |= origPixel & ~((__m128(mask)).m128_u32[3]);
}
else {
UINT origPixel = pixelsCanvas[index+0];
pixelsCanvas[index+0] =
arrGrad[ (int)((__m128(vecHyp)).m128_f32[0]) ] & (__m128(mask)).m128_u32[0];
pixelsCanvas[index+0] |= origPixel & ~((__m128(mask)).m128_u32[0]);
if(col+1<bitmapDataCanvas.Width)
{
origPixel = pixelsCanvas[index+1];
pixelsCanvas[index+1] =
arrGrad[ (int)((__m128(vecHyp)).m128_f32[1]) ] & (__m128(mask)).m128_u32[1];
pixelsCanvas[index+1] |= origPixel & ~((__m128(mask)).m128_u32[1]);
}
if(col+2<bitmapDataCanvas.Width)
{
origPixel = pixelsCanvas[index+2];
pixelsCanvas[index+2] =
arrGrad[ (int)((__m128(vecHyp)).m128_f32[2]) ] & (__m128(mask)).m128_u32[2];
pixelsCanvas[index+2] |= origPixel & ~((__m128(mask)).m128_u32[2]);
}
if(col+3<bitmapDataCanvas.Width)
{
origPixel = pixelsCanvas[index+3];
pixelsCanvas[index+3] =
arrGrad[ (int)((__m128(vecHyp)).m128_f32[3]) ] & (__m128(mask)).m128_u32[3];
pixelsCanvas[index+3] |= origPixel & ~((__m128(mask)).m128_u32[3]);
}
}
}
}
delete [] arrGrad;
graphics.DrawImage(m_pSrcBitmap,0,0,m_pSrcBitmap->GetWidth(),m_pSrcBitmap->GetHeight());
}
UINT* CDrawCircleDlg::GenGrad(UINT a, UINT b, UINT len)
{
int r1=(a&0xff0000)>>16,g1=(a&0xff00)>>8,b1=(a&0xff); int r2=(b&0xff0000)>>16,g2=(b&0xff00)>>8,b2=(b&0xff);
UINT* arr = new UINT[len+1];
for(UINT i=0;i<len+1;i++)
{
int r,g,b;
r = r1 + (i * (r2-r1) / len);
g = g1 + (i * (g2-g1) / len);
b = b1 + (i * (b2-b1) / len);
arr[i] = 0xff000000 | r << 16 | g << 8 | b;
}
return arr;
}
Circle Cover Effect
In this section, we are going to use the code which we developed previously for drawing circle to implement a circle cover effect where a circle keep expanding and exposing the image underneath. So how does the code know when to stop expanding (that is when the entire image is already covered/replaced)? Look at the image below. When you mouse-click on the client area, the distance from the 4 corner are calculated and the longest distance (red line) is selected as the maximum radius to expand.
Tip: you can replace the flickr1.jpg and flickr2.jpg in the res folder with your own images (just rename them to be flickr1.jpg and flickr2.jpg but their dimension have to be equal), the CircleCover application will automatically resize its client dimension to be the same as the 1st embedded image on startup.
Hexagon Cover Effect
The hexagon cover effect is similar to the circle cover application. The only difference is the expanding edge is replaced by little hexagons. As with the CircleCover application, you can replace the images before compilation.
This is how it works. The difference between each hexagon center and the mouse point is calculated. If the difference is greater than the hexagon, then the hexagon should be displayed. If the difference is smaller, then a pre-computed mask (which store the distance of each pixel from the hexagon center) is used to determine whether the pixel underneath should be displayed. I did not convert this application to use SSE, simply because the speed gain will not be much as the number of distance to compute between each hexagon center and the mouse point, are not many. And the distance of each pixel from the hexagon center is pre-computed as a mask. I leave it as a exercise for the reader to convert this code to use SSE. The source code is heavily commented.
Conclusion
We has seen how to use the SIMD vector class provided by Visual Studio for code clarity and code speedup. However, we have also seen the speed penalty in debug build is quite bad (40x). Only simple operations like addition, subtraction, multiplication, division and square root are provided by SIMD vector class. There is no trigonometry functions (like sine and cosine). This is why I restricted my effect to use Pythagorean theorem. The source code is hosted at CodePlex.
History
- 5 March 2012: Added how to write integer division operation using scalar division.
- 28 February 2012: Updated the article with table of the vector classes and their header files.
- 19 February 2012: First release
Reference

