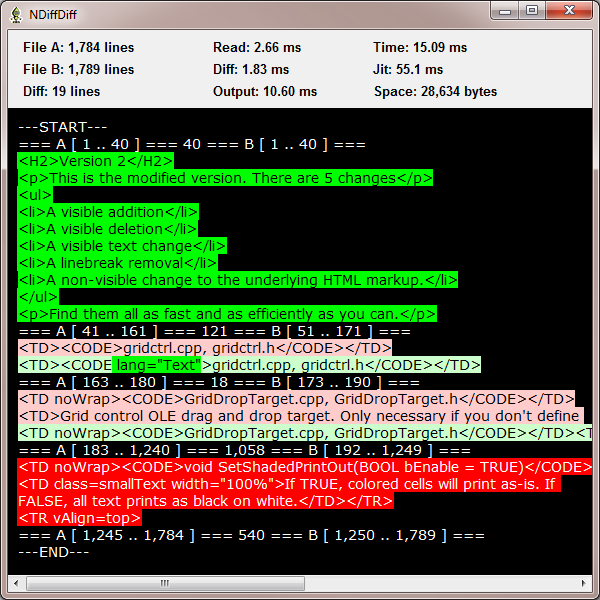
The screenshot shows, in order:
- The visible addition
- The visible text change
- The linebreak removal
- The visible deletion
The white on black lines show matching sections of the files with line numbers and counts.
Introduction
This article is an entry for the Lean and Mean competition, which ran on The Code Project during August 2009.
It is my third entry after NLineDiff and NLineDiffConsole.
The second test file, "grid2.html", says there are 5 changes. I still haven't found the last one: "A non-visible change to the underlying HTML markup", but I thought I could do a better job of the "visible text change", which is the insertion of " lang="Text"" in line 172 of grid2.html and the "linebreak removal" at the end of line 181 in grid1.html.
Background
I will again be using my implementation of the diff algorithm written by Douglas McIlroy in the early 70's and described by Eugene W. Myers in his paper, which is available in the downloads.
However this time, multiple diffs are run. The first diff is run as before on complete lines. This reveals the differences between the two input files. These differences can be grouped into sections separated by identical lines. The sections can be classed as either deletions from file A, insertions in file B, or both.
The interesting sections are those that have both deleted lines and inserted lines. In these sections, it is possible that there is matching text within the lines, as well as a smaller real difference. As for the lines case, all differences can be thought of as deletions from file A or insertions in file B.
For each of these sections, the diff algorithm is run on the characters in the section. This time, we are looking for similarities between the two versions. These are recorded and displayed in more subdued colours in the output, thus highlighting the differences.
Using the Code
The download is a WinForms application which has the two test files as embedded resources, which are loaded by default. You can also diff two arbitrary files by supplying the paths as two command line arguments. The app runs all the required diffs and displays the results and some timing measurements.
The Output
In my first article, I used a WebBrowser control to render the output. This time, I knocked up a custom control that derives from ScrollableControl. It isn't very clever, but it renders the output from the test files in just over 10 ms.
Deleted text is displayed in red, while matching text from file A is shown in light red. Similarly, inserted text is green, while matching text from file B is light green. I think this highlights the actual changes quite well.
Results
As this is an entry for the Lean and Mean competition, here are some metrics:
Time
Representative time measurements for the test case are shown in the screenshot. The time to render the output is large, but I was pleased that the multiple diffs still took less than 2 ms. So the times are about 15 ms for the results and 70 ms including the JIT time.
Space
The largest space requirement is still holding the files in memory as string[]s. This takes about 390 KB for the test case. The two main arrays of Int32s are both roughly ( N + M ) long, where N = the number of lines in file A and M = the number of lines in file B. So the calculated space requirement is still about 420 KB for the results. It is hard to calculate the space taken by the display, but it could be argued that this is the responsibility of the framework.
The change in Process.PeakWorkingSet64 is consistently under 1.5 MB.
Points of Interest
I chose to copy the diff algorithm source to handle the two cases of string[] and char[]. This is because the hot path in the algorithm is the equality operator. I could have used a generic parameter, restricted it with where T : IEquatable<T> and called Equals, but this would have slowed the algorithm considerably. Also, the JIT compiler still has to do work on both versions, so there is no gain.
I did hold on to the two big Int32 arrays and reuse them for the char diffs. This helps because memory allocation and especially collection are expensive in .NET. It also helped that in the particular test case, the two char diffs require less space than the first line diff.
The rendering of the custom control is thread-safe. This is necessary because the diff is run on a background thread and it needs to render the output on that thread. It uses CreateGraphics, which is one of the 5 members of Control that are thread-safe.
History
- 2009 08 31: First edition

