Introduction
One of the most basic things in computer vision is recognition and tracking. Human vision is a bit complex and our understanding of it isn't perfect and impart based on how it breaks (optical illusions). For example, given a photo of a plane with four engines and then shown an identical image with three engines, the time it takes for your mind to tell you it isn't identical varies by image scale. Our brains are massively parallel and we fill in / correct and construct a view then present it to our conscious mind, a filtered view based on many biological images. Computer vision just can't (yet) attempt that kind of approach because the computer horse power just isn't there yet. Even with the benefits of mimicking human vision we would also be subject to it's drawback. There are a few good computer vision approaches (Haar, Fourier, feature extraction) that simplify / reduce the computations. In the coming years, perhaps the reader might discover a new one for the world.
This article and the accompanying code demonstrates a Fourier based method and it's strengths. Each of the approaches has it's strengths and weaknesses, and is ideal for different scenarios. The Fourier techniques are interesting because training is fast, much faster than Haar and the easiest to code. My original goal was to use Fourier as a bridge to identifying significant things for rapid Haar training.
The code uses openCV.Net, a very very nice imaging tool kit the author has used on several platforms for both personal and commercial projects with great success. The OpenCV library can be highly optimized and there are great examples.
Background
Overview of the Haar, Fourier and Feature Algorithms
Haar
The Haar wavelet technique is particularly cool. I recommend reading Viola and Jones article on boosted cascades, it is beautiful. To summarize, a "sum" image is formed where value [x,y] is the sum of all values in the rectangle 0,0 to x,y. By differencing up to sixteen or so points, you can compute how any section of an image compares to any Haar feature independent of scale (but not rotation). The classifier scans across the image and forms different Haar feature comparisons. When a set of comparisons "fails" with a small number of calculations, it rules out that region. When a comparison compares well, then the next feature may refine the comparison more in one way, if the comparison is less than a threshold then it may compare differently in another logic path or stop the comparison. For example given a face the first feature may eliminate anything that doesn't look roundish. The next classifier may split the possibilities into faces with glasses and those without. This statistical comparison, nesting and refining is why it's called a boosted cascade. The problem with the technique is forming the cascade takes hundreds of "positive" images and hundreds of negatives and then hours to create the classifier. There are demonstration applications in C# for face recognition that run extremely fast.
On a side note, the author built a Haar feature viewer to view a couple published Haar feature graphs and found they don't resemble the target. The Haar feature graph locks onto and picks out statistical things that the human eye doesn't latch onto. For example the Haar feature graph for a face isn't very symmetrical, nor are their apparent features that seem to lock onto eyes, nose or chin. When the layers are "boosted" / overlaid it looks slightly more face like.
Fourier
This is a nice technique because you take the FFT of the source and target image, multiply them, then invert. The highest value in the result is the most likely location of the target in the source. In OpenCV, this is two lines of code and you get the normalized (0 to 1=certain) likely hood, and the maximum location. If they are similar but not identical, then there would be smearing if the scale, or rotation or part of the image is blurred or obscured. The other really nice thing is though slower than Haar, if there are multiple targets in the source you find them in the same step.
Feature Extraction
There are a number of transforms that run relatively quick that can turn an image into a set of points, points that represent corners or edges of contours. The pattern of points can then be represented in a rotation and scale invariant pattern to check. The clearest examples are character recognition, but conceptually you take something unique, say the farthest point from the centroid or most isolated point then describe the other points relative to that, rotate to make the next point described horizontal to the first. This is a very fast method, and relatively easy to train, and there are some good example of that sort of thing already in use. It's also something a little hard to code than the Fourier technique.
Fourier Learning and Tracking
Fourier Math
The Fourier transform converts a signal into it's frequency representation, and it's inverse converts the frequency back into the signal. Suppose you had the following signal:
f(t) = 2, 0, 0, 2, 0, 0, 2.
The Fourier transform would combine that signal with a set of function where each function is distinctly different than the others. In fact, each function in the set of functions must be orthogonal: they can be used to describe a unit vector in an infinite dimensional vector space, and they do not correlate to each other (integral of one times the other over all bounds is zero). There are many such sets (x, x^2, x^3, x^n, or sin(x), sin(2x), ..., e^nx, Legendre polynomials). The key is to use a function easy to compute & invert. The most common is the sine function. In imaging sometimes things with radius characteristics (cylindrical harmonics) can best describe a feature but it is computationally hard, quantum mechanics often use Legendre, the Haar technique uses the Haar wavelet as the basis function For more information on the math, check out http://en.wikipedia.org/wiki/Fourier_optics.
When you are not combining a continuous wave form and dealing with a set of measured quantities, the usual way to transform f(t) would be to compute the set of a, b, c, d ... And such that:
F(t) = acos(t) + b sin(t) +c sin(2t) + d cos(2t) .... = f(t) = 2, 0, 0, 2, 0, 0, 2.
But how to solve for a, b, c, d? The key to to correlate, each function is orthogonal so:
sin (nt) f(t) = An -> sin(2t)f(t) = c
This is done quickly using an FFT or Fast Fourier Transform, most numerical techniques are based off of recurring patterns in the sin function, there are numerous articles on the FFT.
The FFT is first performed on each row of the image. This create a row that describes the frequency of the value occurrence. Then the result is FFT'd again across the columns (column FFT of the FFT of the rows). The result is a large array of floating point values that represents the image's frequency component. As an interesting aside, suppose you took an image, and projected it through a lens and looked at the image at the focal point you would see a similar pattern (it would be ordered differently and because it wouldn't be a discrete transform it would look smooth), the author's point is the data isn't lost in the 2D FFT just expressed differently.
Correlation
Once the source image and what you want to find in that image (target) are converted into 2D FFT's the goal is to recombine them (multiply the matrices). My first instinct when I learned this a few years back was, why? How does that help matters? What is really happening is the frequencies that match in the target and source increase, and the others decrease, and the result is a 2D FFT of the places in the source that match the target. By taking the inverse 2D FFT of the result you get a map of where the target is within the source.
Suppose you had a picture of a cat sitting on a couch next to a dog (source image) and a target that was a dog's face. The result would be a bright spot in the picture where the dog's face was. How bright that spot was and how tight that spot would be depends on how close the dog's face in the source resembled the dog's face in the target. If it was identical (same dog, same image) a very bright, crisp dot would be present. If they were similar looking but not the same dog, the spot wouldn't be as bright and would be smeared a bit. What would also be present would probably be a less bright, fuzzy dot that shows that while a dog may not look like a cat, their heads do share some common features.
In the above example, several things were introduced a bit subtly:
Cat * Dog = Cross correlation
This comparison is how much what your looking for correlates to what your not looking for.
Dog * Similar Dog = Matching correlation
That is how well you can use your target(s) to identify new images of what your looking for.
Dog * Same Dog = Auto correlation
The value represents how well target and source compare when only noise is the only difference.
For the above example, suppose the average values are:
Cat * Dog = 0.5, Dog * Similar Dog = 0.7, Dog * Same Dog = 0.95
By commuting the values over a set of images threshold can be computed to determine when something is recognized or not that will, on average generally work.
Now suppose you are looking for two different breeds of dogs in images, then the Dog * Similar Dog value may drop too close to the Cat * Dog value, (Matching is too close to Cross). By adding a different target (one for each dog breed) the Matching threshold can be raised because one target goes after one set of features and the other goes after other features.
Now suppose you are looking for any kind of dog in a set of images, to keep the targets to a small number you would need to use either images of distinctly different looking dogs, or use images that aren't of real dogs but look like a dog but do not have any cat like features. For example, a cat tends to have visible whiskers, so editing out the whiskers from the target image will increase Matching and Auto correlation numbers while decreasing the Cross correlation values.
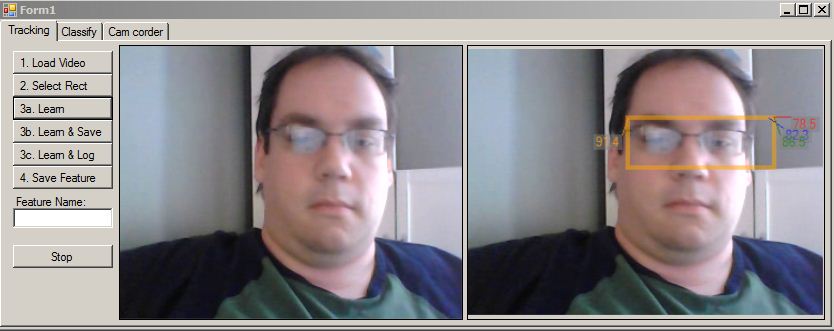
How Learning and Tracking Work
The user loads a video, and selects a rectangle in the first frame. The code also supports taking cam videos to create a training video. The selected tile becomes the first target. It should highly represent what the user wants to track. When the next frame appears, the code tries to find the tile, if the tile is similar to previous identified objects, then the learning code can continue to track the object. If the detection is different than previous ones, but statistically similar enough to still definitely be the same object the new detection is added to the list of targets. If the added target is better than previous ones they are removed.
What is unique and cool is this code finds a small as can be set of unique target image tiles that all distinctly represent the object, different angles, blurring, scales, affine transforms, etc. If it is on average similar to the existing set of targets, or similar to a subset then it definitely recognizes the object. At the same time it may be different enough from most that it could be a new unique target.
The author's idea was based on how signals evolve. In a very basic way tracking an object is like tracking anything, it is an evolving signal. The value changes and shifts but in general, it is either similar to the previous time period or similar one in the past. In signal processing speak, when the signal is very similar over a period of time, it is "stationary". The code tries to find the most representative image from each "stationary" period of the video.
After running the code, the state of the object can be serialized as XML. The tracker can then load in one or more named XML feature classifiers and then apply it to video and track multiple things at once.
Example: Suppose you wanted to train a robot to name each pet when it walks by. The user would take a video of each of their pets, generate a classifier target for each and then let the tracker run over cam images.
To get a good idea of how the learning works, picture this. The first image is of your dog from the side, so this is declared as Target 1. The dog moves a little, but it is very very similar to target 1 so a new target isn't created. The dog turns a little more and a new Target is declared (2). The dog turns a bit more and a third target is made (3). This time target 3 is in the same location as 1 and 2, similar to both, but a bit distinct. The dog stops turning but figits creating frames 4 and 5. On the fifth, it is determined that it is very similar to 3 and 4, but very different from 1 & 2. The software decides to keep the fifth but discard 3 and 4. It would be ideal if the software used all of the previous images used on frames 3, 4, 5 and found the target that most represented them but that would take a fair amount of computations. The software instead keeps replacing previous ones until it sees a new frame that is different. It finds not the "best" of the stationary period of the signal, but a decent one towards the end of each stationary period because it is computationally faster. Suppose more time goes by, and the dog has turned around a few times, sniffed the camera, etc. There could be 50 targets. Suppose then the dog returns to the same "mode" it had taken before. Suppose it now matches frame 5, the new target (proposed to be 51) instead replaces frame 5.
Tracking performance
The author has successfully used the code to track the following:
- Bottom, top and fluid level in a vial or drinking glass.
- Location of a written symbol.
- A symbol written on someone's arm as they move and turn.
- Track a face as the person moves, talks and turns around and turns back.
- Identify a weapon and track it (gun).
Using the code
The goal of the code was to make it good enough to quickly (minutes) train a new feature, and be able to track it relatively well (if the training is representative). This means the technique doesn't create a 3D scale and rotation invariant model of the object to match against like the human mind. It isn't as good as feature or Haar in terms of speed, nor is it particularly scale / rotation invariant. Because it doesn't just use edges / details but also the contours it can lock onto and track the subtle aspects of the image better than Haar or feature based techniques.
The technique is fast, fast to train, easy to code, and very accurate. For example if you wanted to make a self calibrating 3D printing robot (like the author would aspire to do), or have a robot navigate a house based on a camera (another side project) this is an excellent technique.
Learning
The easiest way to use the code is to:
- Go to the "Cam coder" tab, record a video, save it as an AVI.
- Load it into the learning tab, select the feature to track.
- Adjust the region, etc. until it tracks well.
- Save it as an XML.
Classifying
The classifier code has a demo tab, but the general idea is you load XML files into the classifier as different things to look for, then pass it a frame to look at and you can see the location of what it found as it marks a bitmap with rectangles.
Classifier cls = new Classifier();
cls.Reset();
cls.AddFeature(fileName);
cls.AddFeature(otherFileName);
cls.Features.Add(myRuntimeCreatedFeature);
cls.Classify(iplImageFrame, outputBitmap);
It's about that simple.
With that, you have the ability to detect faces, objects, cars, and track them using a built in Kalman Filter.
Here are the cool classes / features built in:
- Kalman Filter for associative tracking
- Multiple features / things tracked at once.
- Learning new objects in real time with tracking.
- A Camera interface lightly wrapped using OpenCV.
- A class to markup an image with text / markers for debug / analysis.
Points of Interest
The author has written a lot of optimized code, so, anything that can be made faster seems like something that needs doing. The code is fast, fast enough to run on a netbook and runs really well on an I3 or better, but faster would mean more could be done. Apart from optimization, the code is also single threaded, on something like an I7, the code could run 2-4x faster by adding threading (that would also tax the resources available for other things of course).
The openCV implementation is semi-optimized. The convolution is fast (FFT) about as fast as possible. The problem is to compare the source against 10 targets, the source if FFT'd 10 times, the target 10 times, they are multiplied and 10 inverse FFT's are performed. The targets need to be forward FFT'd once, not once per frame, and the source needs to be FFT'd just once.
- Current implementation N targets: N*SFFT + N*TFFT + N*Multiply + N*IFFT
- Required minimum for N targets: 1*SFFT + N*Multiply + N*IFFT.
- Potential savings: more than half.
Another thing the author is thinking of is stereo vision. Imagine a robot with stereo cameras: with each pair of frames, how the pieces of the frames match up, you can compute the distance. The interesting thing is, this identifies possible objects to track automatically, and provides two images of the object. With a fast learning tracker this means a sort of mental map of the surroundings can be formed with tracked objects. The robot could also separate out what is close and what is distant, and very likely stationary in the distance (trees, landmarks, walls) and then use those things to help establish navigation.

