Introduction
Today, most applications, libraries, and servers are designed for single-core CPU machines. These software systems will not automatically gain performance improvement by simply running it in multi-core machines. Consider a web server that runs in a single-core machine serving a thousand clients. This web server simply performs compression operation on a given file and stores it. By switching to run this web server in a multi-core machine will not simply increase the performance/throughput. The only way to achieve performance improvement is to write software systems targeting multi-cores. Unfortunately, it is not easy to write software systems that can take advantage of multi-core processors. The Microsoft .NET Framework Task Parallel Library (TPL) is designed to ease this job. This article is about a FastCompress library that uses TPL to achieve impressive performance improvements in multi-core machines. How much impressive? The answer to this depends on the number of processors in your system. If you have 4 processors, you would see approximately 4X (4 times) improvement, 8X for 8 processors etc.
For those who are new to TPL, here's a brief overview from MSDN (Reference 1):
"TPL is being created as a collaborative effort by Microsoft® Research, the Microsoft Common Language Runtime (CLR) team, and the Parallel Computing Platform team. TPL is a major component of the Parallel FX library, the next generation of concurrency support for the Microsoft .NET Framework. TPL does not require any language extensions and works with the .NET Framework 3.5 and higher.
The Task Parallel Library (TPL) is designed to make it much easier to write managed code that can automatically use multiple processors. Using the library, you can conveniently express potential parallelism in existing sequential code, where the exposed parallel tasks will be run concurrently on all available processors. Usually this results in significant speedups".
The Fast Compress Application below was tested in a multi-core machine (4 processors). Both cases - using TPL and not using TPL - are captured below. You can observe that when using TPL, the speed is nearly 4 times faster than when not using TPL.
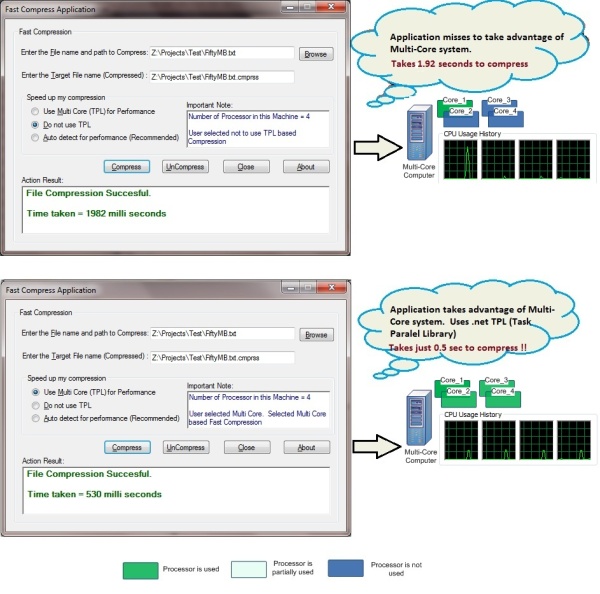
Why multi-core apps, libraries, and servers are useful
An easy way to answer this question is: Google 'The Free Lunch Is Over'. The first result will show you why a fundamental turn towards concurrency in software systems are required (Reference 2). The major processor manufacturers are unable to increase the CPU performance (speed) any further. So the hardware manufacturers are moving towards multi-core hardware architectures. What does this mean? Consider this is 1998 and I am selling App_Sweet, an application used by millions of users. Intel releases a new CPU twice as fast. All I have to do is, just run my App_Sweet in a new computer (with the 2X speed processor). I can see my application performance increase (i.e., a free lunch). But now, the situation has changed. If I run my App_Sweet in a new multi-core computer, I may not observe much of a performance increase. Because, I need to design/architect/code my application for a multi-core processor (i.e., the free lunch is over). Now, if I want to satisfy my users (by increasing my app's performance), I need to change my application design to unleash the power of the underlying multi-core architecture. Interestingly, the performance gain can be close to n times, where n is the number of processors. This increase in additional computing power can translate into a software system's performance, additional features, productivity improvement, efficiency in usage of available resources etc.
In short, if you have a business to run and hire 10 employees, will you delegate the work to all the 10 employees or just to one? If your answer is that you will delegate the work to all the 10 employees, then you will like to use TPL.
Using the code
Prerequisites
Step 1: Just to run: you will need to install .NET framework 4 Beta 2 from here: http://www.microsoft.com/downloads/details.aspx?familyid=DED875C8-FE5E-4CC9-B973-2171B61FE982&displaylang=en.
Step 2: To compile and run: you will need to install Visual Studio 2010 Beta 2 from here: http://msdn.microsoft.com/en-us/vstudio/dd582936.aspx.
Step 3: To see the demonstration of performance difference, in addition to the above steps (steps 1 and 2), you will need a multi-core machine.
To see a quick demo
- Download the QuickDemo.zip file.
- Uncompress the files into a directory (folder).
- Run the executable TestFastCompress.exe.
- Select a file (select a bigger file of size more than a few MB) to compress, by clicking the Browse button.
- Select the 'Do not use TPL' option. Then, click the Compress button. Note down the performance (in milliseconds) at the Action Result section.
- Select the 'Use Multi Core for performance' option. Then, click the Compress button. Note down the performance (in milliseconds) at the Action Result section.
Based on the number of processors in your machine, you should see the speed increase. Typically, the speed increase is close to n times, where n is the number of processors in your machine.
Troubleshooting tip: In case the test application (quick demo) downloaded from this article did not run or throws an exception, you may be having .NET Framework 4 Beta 1. Please install .NET Framework 4 Beta 2 from this link: http://www.microsoft.com/downloads/details.aspx?familyid=DED875C8-FE5E-4CC9-B973-2171B61FE982&displaylang=en.
To use the FastCompress library in your application: Using the FastCompress library in your application is easy. All you need to do is add the library (assembly) in your project as a reference. Then, start using the library.
How to do this:
- In Visual Studio 2010, select Solution Explorer.
- Right click References to select the 'Add Reference..." menu option. Browse to choose FastCompress.dll. Then, click OK to add this reference to your project.
- Use the sample code below:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using BK.Util;
namespace TestFastCompress
{
class Program
{
static void Main(string[] args)
{
FastCompress.doNotUseTPL = true;
FastCompress.compressStrictSeqential = false;
System.Console.WriteLine("Time taken for Seq compression = {0}",
FastCompress.CompressFast(@"Z:\File1.test.seq",
@"Z:\File1.test", true));
System.Console.WriteLine("Time taken for Seq Un compression = {0}",
FastCompress.UncompressFast(@"Z:\File1.test.orgSeq",
@"Z:\File1.test.seq", true));
FastCompress.doNotUseTPL = false;
FastCompress.compressStrictSeqential = false;
System.Console.WriteLine("Time taken for Parallel " +
"compression = {0}",
FastCompress.CompressFast(@"Z:\File1.test.pll",
@"Z:\File1.test", true));
System.Console.WriteLine("Time taken for Parallel Un compression = {0}",
FastCompress.UncompressFast(@"Z:\File1.test.orgpll",
@"Z:\File1.test.pll", true));
}
}
}
Performance results
The basic configuration of the machine used for this performance test is:

Shown below are the performance results of the FastCompress library. The X axis is the size of files compressed in Mega Bytes (MB), and Y axis is the time taken for the compression in milliseconds (ms). You can observe that the speed of the compression using TPL grows close to 4 times faster. The test was performed in a 4 processor machine.
Explanation of the FastCompress library (uses TPL)
Multi-processor machines are getting standard as the clock speed increase of single processors have almost ended. To improve performance, software components are required to be designed/architected to leverage the multi-core architecture. For example, consider that I have a compression utility application. Running the compression utility in a 4 processor machine and a processor machine will not differ much as is. To increase the performance of the compression utility in a 4 processor machine, the compression utility needs to be re-designed. The re-design should consider splitting the work between multiple processors. This may seem an easy task to do. Efficient dynamic work distribution to all the available processors is a tricky task. Parallelizing everything may, in some cases, decrease the performance. Also, if not performed anticipating future business dynamics, extending the parallel design may create complicated problems and result in random crashes. Random crashes are very tough to debug, especially in a parallel programming environment.
The FastCompress library is based on a simple design to parallelize the compression. As in the figure below, the FastCompress slices the file (to be compressed) to create a batch for the processor(s) to operate (compress) independently. These slices are tasked to each processor. This is achieved using the .NET Framework 4 Task Parallel Library (TPL). Note that by using Task.Factory.StartNew, we are expressing interest to the TPL that we would like to run the tasks in parallel. The TPL does the work of scaling automatically to the number of processors in the host computer. If the host machine has 8 processors, most likely, the first 8 slices will be taken for parallel execution on the 8 processors. This obviously improves the performance by approximately 8 times.
The code below is used for performing parallel compression:
while(0 != (read = sourceStream.Read(bufferRead, 0, sliceBytes)))
{
tasks[taskCounter] = Task.Factory.StartNew(() =>
CompressStreamP(bufferRead, read, taskCounter,
ref listOfMemStream, eventSignal));
eventSignal.WaitOne(-1);
taskCounter++;
bufferRead = new byte[sliceBytes];
}
Task.WaitAll(tasks);
In the above code, the while loop in the first line reads sliceBytes (1 MB) at a time. Line 2 calls the TPL method to trigger a parallel activity, i.e., calls the method CompressStreamP asynchronously. Before the method CompressStreamP completes, the code in the next line will be executed. This is a little over-parallellism here. We need to moderate this here. For example, let us assume that we do not have Line 2. In the first iteration, the taskCounter value will be 0. But before CompressStreamP is called, taskCounter may get incremented to 1 (Line 3). So, the first call to CompressStreamP may end up with the value of taskCounter = 1. To explain in detail: the CompressStramP's taskCounter parameter is passed by value. But before it gets copied to the stack (pushed to stack for method call), the value may end up changing due to the Line 3 increment operator. To avoid this, we have Line 2, that event waits for the stack copy (stack push and pop to tell precisely) to complete. Line 3 increments to pass the next 1 MB slice in the file. Line 4 creates a new buffer to copy the next 1 MB slice. After tasking all the slices for the available processors in the system, Line 6 waits for all the tasks (compression tasks) to complete.
The next step after completion of all the tasks is to merge them into a single compressed file. As many of you may assume, a simple merge will not work. This is because the compressed slices may be of different sizes, i.e., each 1 MB slice will not compress to 10 KB. These sizes can vary. During decompression, we need to uncompress exactly the same slice that is compressed. Then, a merge of all these slices will give us the original file. As shown in the figure below, we merge the compressed slices as file size, compressed stream, file size, compressed stream... This also helps us to uncompress the files later in a parallel fashion.
The code that performs this task is as below:
for (taskCounter = 0; taskCounter < tasks.Length; taskCounter++)
{
byte[] lengthToStore =
GetBytesToStore((int)listOfMemStream[taskCounter].Length);
targetStream.Write(lengthToStore, 0, lengthToStore.Length);
byte[] compressedBytes = listOfMemStream[taskCounter].ToArray();
listOfMemStream[taskCounter].Close();
listOfMemStream[taskCounter] = null;
targetStream.Write(compressedBytes, 0, compressedBytes.Length);
}
After waiting for all the tasks to complete, the compressed streams are merged. In a for loop, each stream is converted into a byte array and written to the target file stream. The memory stream is then closed and disposed.
Avoiding pitfalls while using Parallelism
- Parallelism and GUI: Any intensive task executed in UI thread blocks the responsiveness of User Interface. Often, this means, such code is off-loaded to either background thread or worker thread. Such off-loading helps in keeping GUI responsive. When a background thread (or worker thread) completes a task it pushes result back to GUI. Important thing to remember is, the call between other thread and GUI need to be through the context of GUI thread. i.e., any call made on GUI in the context of background (or worker) thread will result in crash, state corruption or even dead lock. Then you'll need WinDBG SOS to solve the dead lock later. To avoid this, background thread (or any worker thread) need to post message to GUI thread through 'invoke' method
- Shared memory: Main reason behind Parallel execution is speed. To foster speed avoid using shared memory/data. It's not completely inevitable. Keeping usage of shared memory to bare minimum gives better results. Whereever shared memory used, use appropriate lock. Read-only memory can be shared with no lock in place
- Over Parallelism: Many new developers believe parallel is always faster. While this is true,'law of diminishing returns' need to be considered here. The computation power is limited with number of CPUs in a system. Creating too many threads will initially bring in snappy execution times. But once this crosses a boundary, most cycles are spent on context switching rather than executing task at hand. A designer need to draw this line while developing an efficient App or server
- Thread-safe and Thread-unsafe methods: Avoid calls to thread unsafe method. This is because, calls to these methods need to employ lock. Often these locks are inefficient as the whole execution path is locked instead of just part of code that needs lock. Also, limiting calls to thread-safe methods is a good idea. Consider calling a thread-safe method 1000 times vs calling thread safe mthod once with an array holding 1000 values. Making smart choice in thread-safe calls brings outstanding performance gains
- COM Inter-op: Beware of various threading models while using COM component. Most of Windows API is available in .net framework stack. However, not all native SDK or COM libraries are available in .net even today. Understanding behind-the-scenes implications of using COM /native Win32 API is important while building performance oriented Application/Server
Points of interest
- Fast compression is achieved by dividing the task to all the available processors in a machine. This improves the speed of compression significantly. Also, it utilizes the available machine resources efficiently for the benefit of the users.
- The
AutoResetEvent, after starting a new task, is very much necessary for ensuring the proper copy of parameters in to the function's stack. This is required for the push and the pop operations in a method call to have the right values. - The design is kept simple to avoid any usage of synchronization (except the signal mentioned in point 2) to improve performance. An
ArrayList is passed to the parallel compress method, suppressing the temptation to use a parallel data structure. - FastCompress will be faster compared to GZipStream's (.NET Framework 4) compression and decompression in a multi-core machine.
- The performance of Fast Compress is directly proportional to the number of processors in the host machine
- The performance metrics (as described in the Performance section above) shows that the performance increase achieved is significant using the TPL.
- FastCompress's decompression is also approximately n times faster. This can also be verified by running the FastCompression sample application provided.
- The FastCompress library is multi-thread safe.
- Parallel compression becomes inefficient (results in larger file) if different compression hashes are used for compressing one file. Best idea is to use one compression hash, but distribute the compression load across different processors
- To pro tune the code, one good alternative to (2) suggested by KevinAG is as follows:
while(0 != (read = sourceStream.Read(bufferRead, 0, sliceBytes)))
{
int counterCopy = taskCounter;
tasks[counterCopy] = Task.Factory.StartNew(() =>
CompressStreamP(bufferRead, read, counterCopy,
ref listOfMemStream));
taskCounter++;
bufferRead = new byte[sliceBytes];
}
Task.WaitAll(tasks);
References:
- Optimize Managed Code For Multi-Core Machines -- http://msdn.microsoft.com/en-us/magazine/cc163340.aspx
- The Free Lunch is Over: A Fundamental Turn Towards Concurrency in Software - http://www.gotw.ca/publications/concurrency-ddj.htm
- GZipStream MSDN reference - http://msdn.microsoft.com/en-us/library/system.io.compression.gzipstream.aspx
- Parallel programming in the .NET Framework -- http://msdn.microsoft.com/en-us/library/dd460693(VS.100).aspx
History
- Version 1 - Dec. 28th 2009.
- Version 1.1
- Apr 9th 2015 - Added new section 'Avoiding pitfalls while using Parallelism'
- Apr 12th 2015 - Corrections and ideas suggested by Paulo Zemek
- Apr 14th 2015 - Added 'Point of Interest' item (10) suggested by KevinAG
- May 7th 2015 - Additional test results posted for irneb

