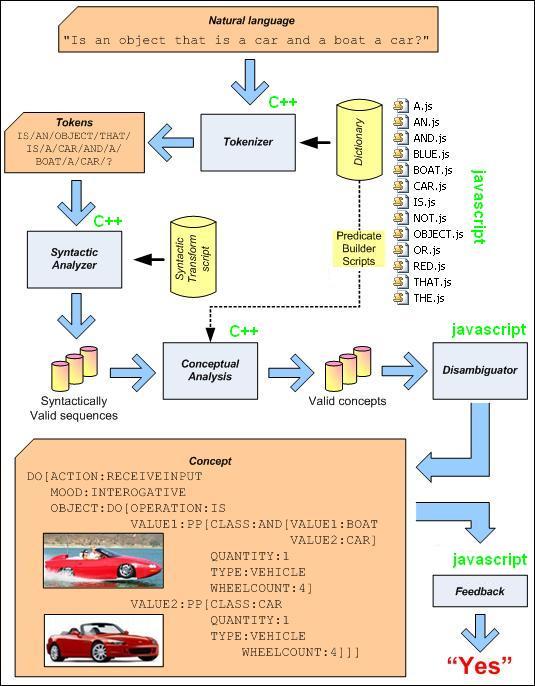
Introduction
People spend a significant amount of time and energy at putting their thoughts into writing. So, it is time for a technology to concentrate on automating the retrieval and manipulation of these thoughts in such a way that the original meaning is not lost in the process. To that end, a means by which concepts are reconstructed and then manipulated from natural language is required. That goal cannot be achieved by a diminutive form of natural language understanding that limits itself to word-spotting or a superficial association of semantic blocks, but rather by a process that mimics the functions of the human brain in its processing and outcome. This article exposes a novel means by which such processing is achieved through a Conceptual Language Understanding Engine (CLUE).
The dominant part of the word "recognition" is "cognition", which is defined in the Oxford dictionary as "the mental acquisition of knowledge through thought, experience, and the senses". The present approach uses techniques that encapsulate most aspects associated with a cognitive approach to recognition.
Communication is a procedural sequence that involves the following processes:
- a "de-cognition" process - producing a syntactic stream representing the cognitive aspect to communicate.
- a transporting process - putting such syntactic stream on a medium.
- a perceptive process - senses acquiring the syntactic stream.
- a "re-cognition" process - rebuilds the original cognitive substance that hopefully has not been lost throughout the syntactic, transporting, and perceptive processing.
Because a full cycle language analysis involving natural language understanding requires putting the concept back in its original form, without incurring any loss of the conceptual manipulations that can be achieved following a "de-cognition" and "re-cognition" processes, the conceptual aspect of language cannot and must not be overlooked. Only when a conceptual dimension to speech analysis becomes available will the syntactic aspect of processing language becomes unconstrained. That is, syntactic analysis will limit to a required transient step for communications to fit on a medium. Only then the limitations that we have endured until today related to natural language understanding and processing will start to fade.
The reward with a CLUE is the ability to abstract the written syntactic forms from conveyed concepts - the words used to communicate become irrelevant as soon as the concept is calculated - while maintaining the ability to intelligently react to recognized content. It further shifts the final responsibility of disambiguation to the conceptual analysis layer, instead of the phonetic and syntactic layers as it has typically been done to this day. That frees the person communicating from the obligation of using predetermined sequences of words or commands in order to be successfully understood by an automated device. In an era where automated devices have become the norm, the bottleneck has shifted to the inability of technology to deal effectively with the human element. People are not comfortable with a set of syntactic related rules that appear to them as counter-natural in relation to their conceptual natural abilities.
Background
This article is the third of a sequence. In the first article, "Implementing a std::map Replacement that Never Runs Out of Memory and Instructions on Producing an ARPA Compliant Language Model to Test the Implementation", the memory management technique used within the code-base provided in the present article is exposed. As a result of that, you shall observe there is only one delete call throughout the entire code-base, and you are certain there is no memory leak within the said C++ code. In the second article, "The Building of a Knowledge Base Using C++ and an Introduction to the Power of Predicate Calculus," predicate calculus is introduced, but falls short of processing natural language input. Although it also exposes techniques in order to infer from a knowledge base - not used in this article, but could easily be adapted to do so - the article covers basic predicate calculus techniques that are widely used in this article. A reading of these two articles will help you gain a better understanding of the basis upon which this code is built. Although Conceptual Speech Recognition is used to interpret speech (sound), for the sake of simplicity and demonstration, this article limits itself to textual content input. A software implementation of this technology can be referred to as a Conceptual Language Understanding Engine, or "CLUE" for short. The approach to process speech recognition is comparable to what is exposed here, but with a couple of software engineering twists in order to include further biases from speech through the integration of a Hidden-Markov-Model that is not discussed in this article.
Using the Code
The current project builds under Visual Studio 2008. It is composed of about 10,000 lines of C++ source code, and about 500 lines of JavaScript code that is processed by Google V8.
The main components of the code are divided as follows:
- The dictionary: A 195,443 words, 222,048 parts-of-speech dictionary, held in a 2.1 MB file, which can return information on spelling almost instantly. [IndexStructure.h, StoredPOSNode.h, StoredPOSNode.cpp, DigitalConceptBuilder::BuildDictionary]
- Tokenization: Transforming a stream of natural language input into tokens based on content included into a dictionary. [IndexStructure.h, POSList.h, POSList.cpp, POSNode.h, POSNode.cpp, IndexInStream.h, DigitalConceptBuilder::Tokenize]
- Syntactic Analysis: The algorithms to extrapolate complex nodes, such as
SENTENCE, from atomic nodes, such as NOUN, ADJECTIVE, and VERB obtained from the dictionary following the tokenization phase. [SyntaxTransform.txt, POSTransformScript.h, POSTransformScript.cpp, Permutation.h, Permutation.cpp, POSList.h, POSList.cpp, POSNode.h, POSNode.cpp, Parser.h, Parser.cpp, BottomUpParser.h, BottomUpParser.cpp, MultiDimEarleyParser.h, MultiDimEarleyParser.cpp] - Conceptual Analysis: The building of concepts based on syntactic organizations, and how Google V8, the JavaScript engine, is integrated into the project. [Conceptual Analysis/*.js, Conceptual Analysis/Permutation scripts/*.js, Conceptual Analysis/POS scripts/*.js, POSList.h, POSList.cpp, POSNode.h, POSNode.cpp, Predicate.h, Predicate.cpp, JSObjectSupport.h, JSObjectSupport.cpp, POSNode::BuildPredicates]
Execution of the Code
Execution of the code as provided with this article runs the test cases specified in SimpleTestCases.txt. Each block within curly brackets defines a scope to run, where CONTENT is the natural language stream to analyze.
Each variable definition prior to the test case sentences can also be inserted within curly bracket scopes to override its value. For example, to enable only the first test case, the following change is possible:
...
#-------------------------------------------------------------------
# ENABLED
# _______
#
# Possible values: TRUE, FALSE
#
# TRUE: enable the test cases within that scope.
#
# FALSE: disable the test cases within that scope.
ENABLED = FALSE
#-------------------------------------------------------------------
{
ENABLED = TRUE
CONTENT = Is a red car a car?
ID = CAR1
}
...
Executing the test cases, as available from within the zip files attached, results in the following output. The remainder of this article exposes the approach, philosophies, and techniques used in order to transition from the Natural Language input from these test-cases to concepts and responses as exposed here.
Evaluating: "Is a red car a car?" (ID:CAR1)
YES:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:PP[CLASS:CAR
COLOR:RED
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]
VALUE2:PP[CLASS:CAR
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]]
Total time: 250 ms
Syntactic: 63 ms
Conceptual: 187 ms.
Evaluating: "Is a red car the car?" (ID:CAR2)
MAYBE:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:PP[CLASS:CAR
COLOR:RED
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]
VALUE2:PP[CLASS:CAR
DETERMINED:TRUE
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]]
Total time: 2 sec (2235 ms)
Syntactic: 31 ms
Conceptual: 2 sec (2204 ms).
Evaluating: "Is the red car a car?" (ID:CAR3)
YES:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:PP[CLASS:CAR
COLOR:RED
DETERMINED:TRUE
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]
VALUE2:PP[CLASS:CAR
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]]
Total time: 203 ms
Syntactic: 31 ms
Conceptual: 172 ms.
Evaluating: "Is the red car red?" (ID:CAR4)
YES:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:PP[CLASS:CAR
COLOR:RED
DETERMINED:TRUE
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]
VALUE2:PP[COLOR:RED]]]
Total time: 219 ms
Syntactic: 31 ms
Conceptual: 188 ms.
Evaluating: "The car is red" (ID:CAR5)
No inquiry to analyze here:
DO[ACTION:RECEIVEINPUT
MOOD:AFFIRMATION
OBJECT:PP[CLASS:CAR
COLOR:RED
DETERMINED:TRUE
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]
Total time: 547 ms
Syntactic: 15 ms
Conceptual: 532 ms.
Evaluating: "Is a red car blue?" (ID:CAR6)
NO:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:PP[CLASS:CAR
COLOR:RED
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]
VALUE2:PP[COLOR:BLUE]]]
Total time: 2 sec (2453 ms)
Syntactic: 31 ms
Conceptual: 2 sec (2422 ms).
Evaluating: "Is a red car red?" (ID:CAR7)
YES:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:PP[CLASS:CAR
COLOR:RED
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]
VALUE2:PP[COLOR:RED]]]
Total time: 235 ms
Syntactic: 32 ms
Conceptual: 203 ms.
Evaluating: "Is a car or a boat a car?" (ID:CAR8)
YES:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:PP[CLASS:OR[VALUE1:BOAT
VALUE2:CAR]
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]
VALUE2:PP[CLASS:CAR
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]]
Total time: 390 ms
Syntactic: 187 ms
Conceptual: 203 ms.
Evaluating: "Is a car an object that is not a car?" (ID:CAR9)
NO:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:PP[CLASS:CAR
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]
VALUE2:AND[VALUE1:PP[QUANTITY:1
TYPE:{DEFINED}]
VALUE2:NOT[VALUE:PP[CLASS:CAR
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]]]]
Total time: 3 sec (3297 ms)
Syntactic: 141 ms
Conceptual: 3 sec (3156 ms).
Evaluating: "Is a boat an object that is not a car?" (ID:CAR10)
YES:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:PP[CLASS:BOAT
QUANTITY:1
TYPE:VEHICLE]
VALUE2:AND[VALUE1:PP[QUANTITY:1
TYPE:{DEFINED}]
VALUE2:NOT[VALUE:PP[CLASS:CAR
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]]]]
Total time: 328 ms
Syntactic: 78 ms
Conceptual: 250 ms.
Evaluating: "Is an object that is not a car a boat?" (ID:CAR11)
MAYBE:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:AND[VALUE1:PP[QUANTITY:1
TYPE:{DEFINED}]
VALUE2:NOT[VALUE:PP[CLASS:CAR
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]]
VALUE2:PP[CLASS:BOAT
QUANTITY:1
TYPE:VEHICLE]]]
Total time: 3 sec (3500 ms)
Syntactic: 63 ms
Conceptual: 3 sec (3437 ms).
Evaluating: "Is a car that is not red a car?" (ID:CAR12)
YES:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:PP[CLASS:CAR
COLOR:!RED
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]
VALUE2:PP[CLASS:CAR
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]]
Total time: 313 ms
Syntactic: 63 ms
Conceptual: 250 ms.
Evaluating: "Is a car an object that is a car or a boat?" (ID:CAR13)
MAYBE:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:PP[CLASS:CAR
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]
VALUE2:OR[VALUE1:PP[CLASS:BOAT
QUANTITY:1
TYPE:VEHICLE]
VALUE2:PP[CLASS:CAR
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]]]
Total time: 3 sec (3875 ms)
Syntactic: 125 ms
Conceptual: 3 sec (3750 ms).
Evaluating: "Is a red car an object that is a car or a boat?" (ID:CAR14)
MAYBE:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:PP[CLASS:CAR
COLOR:RED
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]
VALUE2:OR[VALUE1:PP[CLASS:BOAT
QUANTITY:1
TYPE:VEHICLE]
VALUE2:PP[CLASS:CAR
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]]]
Total time: 4 sec (4563 ms)
Syntactic: 344 ms
Conceptual: 4 sec (4219 ms).
Evaluating: "Is a car that is not red a car?" (ID:CAR15)
YES:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:PP[CLASS:CAR
COLOR:!RED
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]
VALUE2:PP[CLASS:CAR
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]]
Total time: 360 ms
Syntactic: 63 ms
Conceptual: 297 ms.
Evaluating: "Is a red car not red?" (ID:CAR16)
NO:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:PP[CLASS:CAR
COLOR:RED
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]
VALUE2:PP[COLOR:!RED]]]
Total time: 1 sec (1844 ms)
Syntactic: 32 ms
Conceptual: 1 sec (1812 ms).
Evaluating: "Is a car a car that is not red?" (ID:CAR17)
MAYBE:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:PP[CLASS:CAR
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]
VALUE2:PP[CLASS:CAR
COLOR:!RED
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]]
Total time: 3 sec (3125 ms)
Syntactic: 78 ms
Conceptual: 3 sec (3047 ms).
Evaluating: "Is a car that is not red a blue car?" (ID:CAR18)
MAYBE:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:PP[CLASS:CAR
COLOR:!RED
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]
VALUE2:PP[CLASS:CAR
COLOR:BLUE
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]]
Total time: 4 sec (4250 ms)
Syntactic: 250 ms
Conceptual: 4 sec (4000 ms).
Evaluating: "Is a red car a car that is not red?" (ID:CAR19)
NO:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:PP[CLASS:CAR
COLOR:RED
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]
VALUE2:PP[CLASS:CAR
COLOR:!RED
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]]
Total time: 3 sec (3547 ms)
Syntactic: 234 ms
Conceptual: 3 sec (3313 ms).
Evaluating: "Is an object that is not a car a car?" (ID:CAR20)
NO:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:AND[VALUE1:PP[QUANTITY:1
TYPE:{DEFINED}]
VALUE2:NOT[VALUE:PP[CLASS:CAR
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]]
VALUE2:PP[CLASS:CAR
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]]
Total time: 3 sec (3891 ms)
Syntactic: 47 ms
Conceptual: 3 sec (3844 ms).
Evaluating: "Is an object that is a car or a boat a car?" (ID:CAR21)
YES:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:PP[CLASS:OR[VALUE1:BOAT
VALUE2:CAR]
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]
VALUE2:PP[CLASS:CAR
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]]
Total time: 781 ms
Syntactic: 141 ms
Conceptual: 640 ms.
Evaluating: "Is an object that is a car or a boat a red car?" (ID:CAR22)
MAYBE:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:OR[VALUE1:PP[CLASS:BOAT
QUANTITY:1
TYPE:VEHICLE]
VALUE2:PP[CLASS:CAR
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]
VALUE2:PP[CLASS:CAR
COLOR:RED
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]]
Total time: 5 sec (5984 ms)
Syntactic: 344 ms
Conceptual: 5 sec (5640 ms).
Evaluating: "Is an object that is a car and a boat a red car?" (ID:CAR23)
MAYBE:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:PP[CLASS:AND[VALUE1:BOAT
VALUE2:CAR]
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]
VALUE2:PP[CLASS:CAR
COLOR:RED
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]]
Total time: 6 sec (6437 ms)
Syntactic: 734 ms
Conceptual: 5 sec (5703 ms).
Evaluating: "Is a car an object that is a car and a boat?" (ID:CAR24)
NO:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:PP[CLASS:CAR
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]
VALUE2:AND[VALUE1:PP[CLASS:BOAT
QUANTITY:1
TYPE:VEHICLE]
VALUE2:PP[CLASS:CAR
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]]]
Total time: 4 sec (4313 ms)
Syntactic: 125 ms
Conceptual: 4 sec (4188 ms).
Evaluating: "Is an object that is a car and a boat a car?" (ID:CAR25)
YES:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:PP[CLASS:AND[VALUE1:BOAT
VALUE2:CAR]
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]
VALUE2:PP[CLASS:CAR
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]]
Total time: 797 ms
Syntactic: 156 ms
Conceptual: 641 ms.
Done.
The dictionary that is made available through the zip files is a file, article_testcases_streams.txt, with partial content cumulated for the sole purpose to provide the words and parts-of-speech necessary to run the test-cases successfully. That special step was done in order to save readers of this article from a significant download in size since the non-abridged dictionary is more than 8 MB in size.
The non-abridged dictionary is available for download by clicking here (2.2 MB). Unzip the downloaded file and place streams.txt into the DigitalConceptBuilder directory, at the same level as article_testcases_streams.txt, to have it loaded the next time the program will be launched.

The text files streams.txt and article_testcases_streams.txt are editable. The content in streams.txt was obtained over the years from a variety of sources, some of which are under copyright as expressed in the "Licensing information.txt" file from the non-abridged dictionary zip file.
The format used is as follows:
<spelling - mandatory>:<pronunciation - mandatory>:
<part-of-speech - optional>(<data - optional>)
Example: December:dusembar:DATE(m_12).
The pronunciation is mandatory, yet is not used for the purpose of the current article. When the topic of speech recognition is covered in a later article, its use will be necessary.
The text file holding the spellings and parts-of-speech is loaded into a three-way decision tree, whose code can be found in the IndexStructure template, as described in the article: "Implementing a std::map Replacement that Never Runs Out of Memory and Instructions on Producing an ARPA Compliant Language Model to Test the Implementation". A representation of the three-way decision tree can be seen here holding the primary keys "node", "do", "did", "nesting", "null", and "void", as illustrated below:
Holding the dictionary in such a structure provides the best possible performance when tokenizing, while ensuring that the tokens generated from the process have a corresponding entry in the dictionary. Furthermore, the IndexStructure template used can hold data partially on disk and partially in memory, making it a suitable medium for that purpose.
The goal of tokenization is to create a POSList object that holds spelling and corresponding parts-of-speech for the provided syntactic stream.
Following is the partial output from the first test-case executed with DEFINITIONNEEDED = FALSE, OUTPUTTOKENS = TRUE with the non-abridged dictionary loaded.
Evaluating: "Is a red car a car?" (ID:CAR1)
Tokens before syntactic analysis:
[NOUN & "IS"], from 0, to: 1, bridge: 3, index: 0
[VERB & "IS"], from 0, to: 1, bridge: 3, index: 0
[AUX & "IS"], from 0, to: 1, bridge: 3, index: 0
[NOUN & "A"], from 3, to: 3, bridge: 5, index: 1
[PREPOSITION & "A"], from 3, to: 3, bridge: 5, index: 1
[VERB & "A"], from 3, to: 3, bridge: 5, index: 1
[DEFINITE_ARTICLE & "A"], from 3, to: 3, bridge: 5, index: 1
[ADJECTIVE & "RED"], from 5, to: 7, bridge: 9, index: 2
[NOUN & "RED"], from 5, to: 7, bridge: 9, index: 2
[VERB & "RED"], from 5, to: 7, bridge: 9, index: 2
[PROPER_NOUN & "RED"], from 5, to: 7, bridge: 9, index: 2
[NOUN & "CAR"], from 9, to: 11, bridge: 13, index: 3
[PROPER_NOUN & "CAR"], from 9, to: 11, bridge: 13, index: 3
[NOUN & "A"], from 13, to: 13, bridge: 15, index: 4
[PREPOSITION & "A"], from 13, to: 13, bridge: 15, index: 4
[VERB & "A"], from 13, to: 13, bridge: 15, index: 4
[DEFINITE_ARTICLE & "A"], from 13, to: 13, bridge: 15, index: 4
[NOUN & "CAR"], from 15, to: 17, bridge: 18, index: 5
[PROPER_NOUN & "CAR"], from 15, to: 17, bridge: 18, index: 5
[PUNCTUATION & "?"], from 18, to: 18, bridge: 0, index: 6
Tokenization can appear as an easy task, but it has hidden difficulties of its own.
- Tokenization must allow words to be included in other words (for example, 'all' and 'all-in-one').
- While tokenizing, special provisions for numbers handling, which are not part of the dictionary, must be covered.
- Allowed punctuation must be taken into account.
- Punctuation that is not allowed must be ignored, unless it is part of a dictionary entry.
- Any word from the resulting list of words in
POSList must be readily accessible based on its position in the stream and its part of speech to ensure that later processing will not be negatively affected in regards to performance.
#ifndef __POSLIST_HH__
#define __POSLIST_HH__
#include <vector>
#include <map>
#include <string>
using std::vector;
using std::map;
using std::string;
#include "POSNode.h"
#include "shared_auto_ptr.h"
#include "IndexInStream.h"
class POSList;
class POSList
{
public:
POSList(bool duplicateDefense = false);
virtual POSNode *AddToPOSList(shared_auto_ptr<POSNode> dNode);
vector<shared_auto_ptr<POSNode>>
BrigdgeableNodes(int position, shared_auto_ptr<POSNode> dPOSNode);
int GetLowestStartPosition();
int GetHighestEndPosition();
vector<shared_auto_ptr<POSNode>> AccumulateAll(
shared_auto_ptr<POSNode> dPOSNode,
POSNode::ESortType sort = POSNode::eNoSort,
int fromPos = -1, int toPos = -1);
void Output(int pos = -1);
unsigned long Count();
virtual void Clear();
void ResetPOSNodeIteration();
virtual IndexInStream<POSNode> *GetPositionInList();
virtual bool GetNext(shared_auto_ptr<POSNode> &dPOSNode);
protected:
virtual string GetLineOutput(shared_auto_ptr<POSNode> dNode);
IndexInStream<POSNode> m_position;
int m_lowestStart;
int m_highestEnd;
bool m_duplicateDefense;
map<string, int> m_uniqueEntries;
int m_count;
};
#endif
In order to have a quick retrieval mechanism, the POSList class uses the m_position member that is an IndexInStream<POSNode> instance. The IndexInStream template is used in some cases when quick retrieval of an object, in our case, a POSNode, is needed based on a position in the stream and a POSEntry type. The implementation of the IndexInStream template follows:
#ifndef __INDEXSINSTREAM_H__
#define __INDEXSINSTREAM_H__
#include <map>
#include <vector>
using std::map;
using std::vector;
#include "POSEntry.h"
template <class T> class IndexInStreamPosition
{
public:
IndexInStreamPosition();
void Add(shared_auto_ptr<T> dContent, POSEntry dPosEntry);
typedef typename map<int, vector<shared_auto_ptr<T>>>
container_map_vector_type;
typedef typename
container_map_vector_type::iterator iterator_map_vector_type;
container_map_vector_type m_content;
};
template <class T> IndexInStreamPosition<T>::IndexInStreamPosition() {}
template <class T> void IndexInStreamPosition<T>::Add(
shared_auto_ptr<T> dContent, POSEntry dPosEntry)
{
m_content[dPosEntry.GetValue()].push_back(dContent);
}
template <class T> class IndexInStream
{
public:
IndexInStream();
void Reset();
void Clear();
void Add(shared_auto_ptr<T> dObject, int position, POSEntry dPos);
bool GetNext(shared_auto_ptr<T> &dPOSNode);
vector<shared_auto_ptr<T>> ObjectsAtPosition(int position,
POSEntry dPOSEntry, int *wildcardPosition = NULL);
protected:
typedef typename map<int,
shared_auto_ptr<IndexInStreamPosition<T>>>
container_map_index_type;
typedef typename
container_map_index_type::iterator iterator_map_index_type;
typedef typename map<int,
vector<shared_auto_ptr<T>>> container_map_vector_type;
typedef typename container_map_vector_type::iterator
iterator_map_vector_type;
container_map_index_type m_allSameEventPOSList;
iterator_map_index_type m_iterator1;
iterator_map_vector_type m_iterator2;
int m_posVectorEntryIndex;
};
template <class T> IndexInStream<T>::IndexInStream(): m_posVectorEntryIndex(-1)
{
Reset();
m_allSameEventPOSList.clear();
}
template <class T> void IndexInStream<T>::Clear()
{
Reset();
}
template <class T> vector<shared_auto_ptr<T>>
IndexInStream<T>::ObjectsAtPosition(int position,
POSEntry dPOSEntry, int *wildcardPosition)
{
vector<shared_auto_ptr<T>> dReturn;
if (m_allSameEventPOSList.find(position) != m_allSameEventPOSList.end())
{
if (m_allSameEventPOSList[position]->m_content.find(dPOSEntry.GetValue()) !=
m_allSameEventPOSList[position]->m_content.end())
{
dReturn =
m_allSameEventPOSList[position]->m_content[dPOSEntry.GetValue()];
}
}
if (wildcardPosition != NULL)
{
vector<shared_auto_ptr<T>> temp =
ObjectsAtPosition(*wildcardPosition, dPOSEntry);
for (unsigned int i = 0; i < temp.size(); i++)
{
dReturn.push_back(temp[i]);
}
}
return dReturn;
}
template <class T> bool IndexInStream<T>::GetNext(shared_auto_ptr<T> &dObject)
{
while (m_iterator1 != m_allSameEventPOSList.end())
{
while ((m_posVectorEntryIndex != -1) &&
(m_iterator2 != m_iterator1->second.get()->m_content.end()))
{
if (m_posVectorEntryIndex < (int)m_iterator2->second.size())
{
dObject = m_iterator2->second[m_posVectorEntryIndex];
m_posVectorEntryIndex++;
return true;
}
else
{
m_iterator2++;
m_posVectorEntryIndex = 0;
}
}
m_iterator1++;
m_posVectorEntryIndex = 0;
if (m_iterator1 != m_allSameEventPOSList.end())
{
m_iterator2 = m_iterator1->second.get()->m_content.begin();
}
else
{
m_posVectorEntryIndex = -1;
}
}
Reset();
return false;
}
template <class T> void IndexInStream<T>::Add(
shared_auto_ptr<T> dObject, int position, POSEntry dPos)
{
if (m_allSameEventPOSList.find(position) == m_allSameEventPOSList.end())
{
m_allSameEventPOSList[position] =
shared_auto_ptr<IndexInStreamPosition<T>>(
new IndexInStreamPosition<T>());
}
m_allSameEventPOSList[position]->Add(dObject, dPos);
}
template <class T> void IndexInStream<T>::Reset()
{
m_iterator1 = m_allSameEventPOSList.begin();
m_posVectorEntryIndex = 0;
if (m_iterator1 != m_allSameEventPOSList.end())
{
m_iterator2 = m_iterator1->second.get()->m_content.begin();
}
else
{
m_posVectorEntryIndex = -1;
}
}
#endif
With the POSList class implemented, the tokenization is implemented as follows:
shared_auto_ptr<POSList> DigitalConceptBuilder::Tokenize(string dContent,
string posNumbers,
string posPunctuation,
string punctuationAllowed,
bool definitionNeeded)
{
struct TokenizationPath
{
TokenizationPath(
shared_auto_ptr<IndexStructureNodePosition<StoredPOSNode>> dPosition,
unsigned int dStartIndex): m_position(dPosition), m_startIndex(dStartIndex) {}
shared_auto_ptr<IndexStructureNodePosition<StoredPOSNode>> m_position;
unsigned int m_startIndex;
};
unsigned int dWordIndex = 0;
shared_auto_ptr<POSList> dReturn = shared_auto_ptr<POSList>(new POSList(true));
string dNumberBuffer;
vector<TokenizationPath> activePaths;
vector<POSNode*> floatingBridges;
int latestBridge = -1;
for (unsigned int i = 0; i <= dContent.length(); i++)
{
bool isAllowedPunctuation = false;
string dCharStr = "";
if (i < dContent.length())
{
dCharStr += dContent.c_str()[i];
if ((posPunctuation.length()) &&
(punctuationAllowed.find(dCharStr) != string.npos))
{
isAllowedPunctuation = true;
latestBridge = i;
}
}
activePaths.push_back(TokenizationPath(
shared_auto_ptr<IndexStructureNodePosition<StoredPOSNode>>(
new IndexStructureNodePosition<StoredPOSNode>(
m_POS_Dictionary.GetTopNode())), i));
for (unsigned int j = 0; j < activePaths.size(); j++)
{
if ((activePaths[j].m_position.get() != NULL) &&
(activePaths[j].m_position->get() != NULL) &&
(activePaths[j].m_position->get()->m_data != NULL))
{
if ((i == dContent.length()) || (IsDelimitor(dContent.c_str()[i])))
{
string dKey = activePaths[j].m_position->GetNode()->GetKey();
if ((i < dKey.length()) ||
(IsDelimitor(dContent.c_str()[i - dKey.length() - 1])))
{
StoredPOSNode *dPOS = activePaths[j].m_position->get();
for (int k = 0; k < kMAXPOSALLOWED; k++)
{
if (dPOS->m_pos[k] != -1)
{
shared_auto_ptr<POSNode> candidate =
POSNode::Construct("["+POSEntry::StatGetDescriptor(
dPOS->m_pos[k]) + " & \"" + dKey + "\"]", NULL,
activePaths[j].m_startIndex, i-1, 0,
(dPOS->m_data[k] != -1)?m_data[dPOS->m_data[k]]:"");
if (PassedDefinitionRequirement(candidate, definitionNeeded))
{
POSNode *dNewNode = dReturn->AddToPOSList(candidate);
if (dNewNode != NULL)
{
floatingBridges.push_back(dNewNode);
}
latestBridge = activePaths[j].m_startIndex;
}
}
}
}
}
}
if ((latestBridge != -1) && (((i < dContent.length()) &&
(!IsDelimitor(dContent.c_str()[i]))) ||
(i == dContent.length()) || (isAllowedPunctuation)))
{
bool atLeastOneAdded = false;
for (int l = (floatingBridges.size() - 1); l >= 0; l--)
{
if ((floatingBridges[l]->GetBridgePosition() == 0) &&
(floatingBridges[l]->GetStartPosition() != latestBridge))
{
atLeastOneAdded = true;
floatingBridges[l]->SetWordIndex(dWordIndex);
floatingBridges[l]->SetBridgePosition(latestBridge);
floatingBridges.erase(floatingBridges.begin() + l);
}
}
if (atLeastOneAdded)
{
dWordIndex++;
}
if (isAllowedPunctuation)
{
shared_auto_ptr<POSNode> candidate =
POSNode::Construct("[" + posPunctuation + " & \"" +
dCharStr + "\"]", NULL, i, i, 0);
if (PassedDefinitionRequirement(candidate, definitionNeeded))
{
POSNode *dNewNode = dReturn->AddToPOSList(candidate);
if (dNewNode != NULL)
{
floatingBridges.push_back(dNewNode);
}
latestBridge = i;
}
}
else
{
latestBridge = -1;
}
}
if (i == dContent.length())
{
break;
}
shared_auto_ptr<IndexStructureNodePosition<StoredPOSNode>>
dNewPosition = m_POS_Dictionary.ForwardNodeOneChar(
activePaths[j].m_position, toupper(dContent.c_str()[i]));
if (dNewPosition.get() != NULL)
{
activePaths[j].m_position = dNewPosition;
}
else
{
activePaths[j].m_position->Clear();
}
}
if ((posNumbers.length() > 0) && ((dContent.c_str()[i] >= '0') &&
(dContent.c_str()[i] <= '9') ||
((dContent.c_str()[i] == '.') && (dContent.length() > 0))))
{
if ((i == 0) || (dNumberBuffer.length() > 0) ||
(IsDelimitor(dContent.c_str()[i-1])))
{
dNumberBuffer += dContent.c_str()[i];
}
}
else if (dNumberBuffer.length() > 0)
{
shared_auto_ptr<POSNode> candidate =
POSNode::Construct("["+posNumbers + " & \"" +
dNumberBuffer + "\"]", NULL, i - dNumberBuffer.length(), i - 1, 0);
if (PassedDefinitionRequirement(candidate, definitionNeeded))
{
POSNode *dNewNode = dReturn->AddToPOSList(candidate);
if (dNewNode != NULL)
{
floatingBridges.push_back(dNewNode);
}
latestBridge = i - dNumberBuffer.length();
dNumberBuffer = "";
}
}
for (int j = (activePaths.size() - 1); j >= 0; j--)
{
if ((activePaths[j].m_position.get() == NULL) ||
(activePaths[j].m_position->GetNode().get() == NULL))
{
activePaths.erase(activePaths.begin() + j);
}
}
}
for (int l = (floatingBridges.size() - 1); l >= 0; l--)
{
floatingBridges[l]->SetWordIndex(dWordIndex);
}
return dReturn;
}
The purpose of Syntactic Analysis is to produce complex nodes from the atomic nodes passed in the POSList and to identify the targeted complex nodes to provide to the Conceptual Analysis process. In a CLUE, Syntactic Analysis is not the final disambiguator; rather, the Conceptual Analysis process working in conjunction with the Syntactic Analysis process shall determine which concept prevails over the others based on meaning and syntactic integrity. Consequently, there is no requirement to fully disambiguate during the Syntactic Analysis process, meaning that Syntactic Analysis produces a multitude of syntactic organizations that later need to be disambiguated by Conceptual Analysis. Prior to Syntactic Analysis, there is a lot of ambiguity because the process only holds a list of POSNodes that each have associated parts-of-speech; following Syntactic Analysis, there is less ambiguity because targeted parts-of-speech have been identified and associated with their corresponding sequences of words and parts-of-speech required to build them. Syntactic Analysis is also useful in providing Conceptual Analysis with syntactic information to rely upon in predicate calculation. As is later exposed in this article, a Predicate Builder Script is composed of code that mostly relates to syntax, and making the transition from a syntactic stream to concepts relies heavily on syntactic information produced during Syntactic Analysis.
The Syntactic Transform Script stored in SyntaxTransform.txt is central to Syntactic Analysis. The content of that file holds sequencing decisions used to build complex nodes from a configuration of complex nodes and atomic nodes found in the dictionary. The Syntactic Transform Script is composed of about 50 lines of code of a language that is created for the sole purpose of permuting nodes.
A closer look into the first three lines of code from SyntaxTransform.txt helps in understanding that language.
ADJECTIVE PHRASE CONSTRUCTION 1: ([ADVERB])[ADJECTIVE] -> ADJECTIVE_PHRASE
MAXRECURSIVITY:2
ADJECTIVE PHRASE ENUMERATION: [ADJECTIVE_PHRASE]([CONJUNCTION])
[ADJECTIVE_PHRASE] -> ADJECTIVE_PHRASE
# Verbs
MAXRECURSIVITY:1
COMPLEX VERB CONSTRUCTION: [VERB & "is" | "was" | "will" | "have" |
"has" | "to" | "will be" | "have been" |
"has been" | "to be" | "will have been" |
"be" | "would" | "could" | "should"]([ADVERB])[VERB] -> VERB
Lines have been wrapped in the above snippet to avoid scrolling.
The first line permutes all possibilities from ([ADVERB])[ADJECTIVE] and creates a resulting node that is a part-of-speech, ADJECTIVE_PHRASE. For example, tokens such as "more red" result in an ADJECTIVE_PHRASE since "more" is an ADVERB and "red" is an ADJECTIVE. But since the ADVERB node is between parentheses, it is identified as being optional. Consequently, the ADJECTIVE token "blue" also results in an ADJECTIVE_PHRASE node.
The following line, [ADJECTIVE_PHRASE]([CONJUNCTION])[ADJECTIVE_PHRASE], takes sequences of ADJECTIVE_PHRASE nodes, optionally separated by a CONJUNCTION node, and creates a new ADJECTIVE_PHRASE node with them. Such a script line is recursive since it transforms into a part-of-speech that is part of its sequencing. To that effect, in order to limit computing to a reasonable level of parsing, we may want to limit recursion as it is done on the preceding line: MAXRECURSIVITY:2. That basically states that only two successful passes at this transformation line are allowed. That means that tokens such as "more blue and less green" are transformed successfully, while tokens such as "red, some green and grey" are not transformed successfully since a recursion level of at least 3 is required for that transform to happen. Note that recursion limitations are only relevant while performing bottom-up parsing and not multi-dimensional Earley parsing. More on that later...
The next line, [VERB & "is" | "was" | "will" | "have" | "has" | "to" | "will be" | "have been" | "has been" | "to be" | "will have been" | "be" | "would" | "could" | "should"]([ADVERB])[VERB], has comparable rules, but also states some conditions in regards to spellings for the first node. The components between double-quotes are spelling conditions, where at least one of which must succeed for the node match to occur. From that line of code, a successful transform happens for the token sequence: "could never see", but fails for the token sequence: "see always ear".
Here is the complete script. It encapsulates most of the English language, although slight adaptations may be required if more complex test cases are not transformed as expected.
# NOTES ON THE SYNTAX OF THE SCRIPTING LANGUAGE
# - BEFORE THE ':' CHARACTER ON A LINE IS THE LINE NAME
# - A NODE BETWEEN PARENTHESIS IS INTERPREATED AS BEING OPTIONAL
# - CONTENT BETWEEN QUOTES RELATES TO SPELLING
# - SPELLINGS THAT BEGIN WITH A '*' CHARACTER ARE INTERPREATED
#- AS A 'START WITH' STRING MATCH
# - ON THE RIGHT SIDE OF THE CHARACTERS '->'
# - IS THE DEFINITION OF THE NEW ENTITY (AFFECTATION)
# SCRIPT
# Adjective phrase construction
ADJECTIVE PHRASE CONSTRUCTION 1: ([ADVERB])[ADJECTIVE] -> ADJECTIVE_PHRASE
MAXRECURSIVITY:2
ADJECTIVE PHRASE ENUMERATION: [ADJECTIVE_PHRASE]([CONJUNCTION])
[ADJECTIVE_PHRASE] -> ADJECTIVE_PHRASE
# Verbs
MAXRECURSIVITY:1
COMPLEX VERB CONSTRUCTION: [VERB & "is" | "was" | "will" | "have" |
"has" | "to" | "will be" | "have been" |
"has been" | "to be" | "will have been" |
"be" | "would" | "could" |
"should"]([ADVERB])[VERB] -> VERB
# Noun phrase construction
GERUNDIVE ING: [VERB & "*ing"] -> GERUNDIVE_VERB
GERUNDIVE ED: [VERB & "*ed"] -> GERUNDIVE_VERB
PLAIN NOUN PHRASE CONSTRUCTION: ([DEFINITE_ARTICLE | INDEFINITE_ARTICLE])
([ORDINAL_NUMBER])([CARDINAL_NUMBER])
([ADJECTIVE_PHRASE])[NOUN | PLURAL |
PROPER_NOUN | TIME |
DATE | PRONOUN] -> NOUN_PHRASE
MAXRECURSIVITY:2
NOUN PHRASE ENUMERATION: [NOUN_PHRASE]([CONJUNCTION])[NOUN_PHRASE] -> NOUN_PHRASE
MAXRECURSIVITY:1
# Preposition phrase construction
PREPOSITION PHRASE CONSTRUCTION: [PREPOSITION][NOUN_PHRASE] -> PREPOSITION_PHRASE
MAXRECURSIVITY:2
PREPOSITION PHRASE ENUMERATION: [PREPOSITION_PHRASE]([CONJUNCTION])
[PREPOSITION_PHRASE] -> PREPOSITION_PHRASE
# Verb phrase construction
VERB PHRASE CONSTRUCTION 1: [VERB]([ADVERB])[NOUN_PHRASE]
([PREPOSITION_PHRASE]) -> VERB_PHRASE
VERB PHRASE CONSTRUCTION 2: [VERB][PREPOSITION_PHRASE] -> VERB_PHRASE
VERB PHRASE CONSTRUCTION 3: [ADJECTIVE_PHRASE][PREPOSITION][VERB] -> VERB_PHRASE
# Noun phrase construction while considering gerundive
GERUNDIVE PHRASE CONSTRUCTION: [GERUNDIVE_VERB]([NOUN_PHRASE])
([VERB_PHRASE])([ADVERB]) -> GERUNDIVE_PHRASE
MAXRECURSIVITY:2
NOUN PHRASE CONST WITH GERUNDIVE: [NOUN_PHRASE][GERUNDIVE_PHRASE]
([GERUNDIVE_PHRASE])([GERUNDIVE_PHRASE]) -> NOUN_PHRASE
PREPOSITION PHRASE CONSTRUCTION 3: [PREPOSITION][GERUNDIVE_PHRASE] -> PREPOSITION_PHRASE
# Noun phrase construction while considering restrictive relative clauses
RESTRICTIVE RELATIVE CLAUSE: [WH_PRONOUN & "who" | "where" | "when" |
"which"][VERB_PHRASE] -> REL_CLAUSE
RESTRICTIVE RELATIVE CLAUSE 2: [PRONOUN & "that"][VERB_PHRASE] -> REL_CLAUSE
MAXRECURSIVITY:2
NOUN PHRASE WITH REL_CLAUSE: [NOUN_PHRASE][REL_CLAUSE] -> NOUN_PHRASE
# Make sure the restrictive relative clauses built are part of the verb phrases
VERB PHRASE WITH REL_CLAUSE: [VERB_PHRASE][REL_CLAUSE] -> VERB_PHRASE
VERB PHRASE CONSTRUCTION 4: [VERB][NOUN_PHRASE][REL_CLAUSE]
([PREPOSITION_PHRASE]) -> VERB_PHRASE
MAXRECURSIVITY:2
WH_PRONOUN CONSTRUCTION ENUMERATION: [WH_PRONOUN][CONJUNCTION][WH_PRONOUN] -> WH_PRONOUN
# Make sure the gerundive built are part of the verb phrases
VERB PHRASE CONSTRUCTION 5: [VERB][NOUN_PHRASE][GERUNDIVE_PHRASE]
([GERUNDIVE_PHRASE])([GERUNDIVE_PHRASE])
([PREPOSITION_PHRASE]) -> VERB_PHRASE
VERB PHRASE CONSTRUCTION 6: [VERB][NOUN_PHRASE][ADJECTIVE_PHRASE] -> VERB_PHRASE
VERB PHRASE CONSTRUCTION 7: ([VERB])[NOUN_PHRASE][VERB] -> VERB_PHRASE
MAXRECURSIVITY:2
VERB PHRASE CONSTRUCTION 8: [VERB_PHRASE][NOUN_PHRASE][GERUNDIVE_PHRASE]
([GERUNDIVE_PHRASE])([GERUNDIVE_PHRASE])
([PREPOSITION_PHRASE]) -> VERB_PHRASE
MAXRECURSIVITY:2
VERB PHRASE CONSTRUCTION 9: [VERB_PHRASE]([NOUN_PHRASE])
[ADJECTIVE_PHRASE] -> VERB_PHRASE
MAXRECURSIVITY:2
VERB PHRASE CONSTRUCTION 10: [WH_PRONOUN][VERB_PHRASE] -> VERB_PHRASE
MAXRECURSIVITY:2
VERB PHRASE CONSTRUCTION 11: [VERB_PHRASE][NOUN_PHRASE](
[PREPOSITION_PHRASE |
GERUNDIVE_PHRASE]) -> VERB_PHRASE
MAXRECURSIVITY:2
VERB PHRASE CONSTRUCTION 12: [VERB_PHRASE][PREPOSITION_PHRASE] -> VERB_PHRASE
# WH-Phrases construction
WH_NP CONSTRUCTION 1: [WH_PRONOUN][NOUN_PHRASE] -> WH_NP
WH_NP CONSTRUCTION 2: [WH_PRONOUN][ADJECTIVE]([ADVERB]) -> WH_NP
WH_NP CONSTRUCTION 3: [WH_PRONOUN][ADVERB][ADJECTIVE] -> WH_NP
MAXRECURSIVITY:2
WH_NP CONSTRUCTION 4: [WH_NP][CONJUNCTION][WH_NP | WH_PRONOUN] -> WH_NP
# Sentence construction
SENTENCE CONSTRUCTION QUESTION 1: [VERB & "is" | "was" | "were"]
[NOUN_PHRASE][NOUN_PHRASE](
[PUNCTUATION & "?"]) -> SENTENCE
SENTENCE CONSTRUCTION QUESTION 2: [VERB & "is" | "was" | "were"]
[VERB_PHRASE][VERB_PHRASE](
[PUNCTUATION & "?"]) -> SENTENCE
SENTENCE CONSTRUCTION 1: [VERB_PHRASE]([PREPOSITION & "at" | "in" | "of" |
"on" | "for" | "into" | "from"])
([PUNCTUATION & "?"]) -> SENTENCE
SENTENCE CONSTRUCTION 2: ([AUX])[NOUN_PHRASE][VERB_PHRASE | VERB](
[PREPOSITION & "at" | "in" | "of" |
"on" | "for"])([ADVERB])([PUNCTUATION & "?"]) -> SENTENCE
WH_NP SENTENCE CONSTRUCTION 1: [WH_NP][VERB_PHRASE]([PREPOSITION & "at" |
"in" | "of" | "on" | "for" | "into" |
"from"])([PUNCTUATION & "?"]) -> SENTENCE
WH_NP SENTENCE CONSTRUCTION 2: [WH_NP]([AUX])[NOUN_PHRASE][VERB_PHRASE | VERB](
[PREPOSITION & "at" | "in" | "of" | "on" | "for"])
([ADVERB])([PUNCTUATION & "?"]) -> SENTENCE
WH_NP SENTENCE CONSTRUCTION 3: [NOUN_PHRASE | VERB_PHRASE]([PREPOSITION &
"at" | "in" | "of" | "on" | "for" | "into" |
"from"])[WH_NP]([PUNCTUATION & "?"]) -> SENTENCE
MAXRECURSIVITY:2
SENTENCE CONSTRUCTION 4: [SENTENCE]([CONJUNCTION])[SENTENCE] -> SENTENCE
Lines have been wrapped in the above snippet to avoid scrolling.
One goal for the Syntactic Transform Script is to create [SENTENCE] complex nodes. Sentences are special as they are expected to encapsulate a complete thread of thoughts that can later be represented by a predicate. Although predicates can also be calculated for other complex nodes, only [SENTENCE] parts-of-speech can reliably fully be encapsulated into a predicate. That does not mean the [SENTENCE] part-of-speech is necessarily self-contained, though. For example, think about the two following [SENTENCE]s: "I saw Edith yesterday. She is feeling great." The object of knowledge "she" in the second [SENTENCE] refers to the object of knowledge "Edith" from the first [SENTENCE]. For the purpose of this sample project, although it is possible to do so, we will not keep a context between different [SENTENCE] nodes.
Permuting the Syntactic Transform Script
One of the first things done by the syntactic analyzer is to create a decision-free version of the Syntactic Transform Script. That is, it creates a version of the Syntactic Transform Script into POSDictionary_flat.txt that is functionally equivalent to SyntaxTransform.txt that does not hold any decision nodes (nodes between parenthesis in SyntaxTransform.txt, or different spellings conditions that are delimited by the pipe character within a node). The content of POSDictionary_flat.txt, as generated by the downloadable executable attached to this article, can be referred to by clicking here. In order to do that, it performs two distinct steps into POSTransformScript::ManageSyntacticDecisions, where the parameter decisionFile is the string holding the name of the Syntax Transform Script.
void POSTransformScript::ManageSyntacticDecisions(string decisionFile,
string dFlatFileName)
{
FlattenDecisions(decisionFile, "temp.txt");
FlattenDecisionNodes("temp.txt", dFlatFileName);
}
During the first step (into POSTransformScript::FlattenDecisions), each line of the file is read, and each element between parenthesis is removed from parenthesis in one line and ignored into another. Since an element between parenthesis is optional, there are indeed only two possibilities - it is included or not.
void POSTransformScript::FlattenDecisions(string dDecisionFileName,
string dFlattenDecisionFileName)
{
fstream dOutputStream;
dOutputStream.open(dFlattenDecisionFileName.c_str(),
ios::out | ios::binary | ios::trunc);
ifstream dInputStream(dDecisionFileName.c_str(), ios::in | ios::binary);
dInputStream.unsetf(ios::skipws);
string dBuffer;
char dChar;
while (dInputStream >> dChar)
{
switch (dChar)
{
case '\n':
case '\r':
if (dBuffer.find("#") != string::npos)
{
dBuffer = SubstringUpTo(dBuffer, "#");
}
if (dBuffer.length() > 0)
{
unsigned int i;
vector<string> *matches;
Permutation perms(dBuffer);
matches = perms.GetResult();
for (i = 0; i < matches->size(); i++)
{
dOutputStream.write(
matches->at(i).c_str(), matches->at(i).length());
dOutputStream.write("\r\n", strlen("\r\n"));
}
}
dBuffer = "";
break;
default:
dBuffer += dChar;
}
}
dInputStream.close();
dOutputStream.close();
}
To help the calculation of all possible permutations of a single line, the Permutation class is used. Since there may be more than one permutation on a line, the use of the recursive Permutation::FillResult method is the best approach to perform these calculations.
void Permutation::FillResult()
{
m_result.clear();
vector<string> matches;
if (PatternMatch(m_value, "(*)", &matches, true))
{
string tmpString = m_value;
size_t pos = tmpString.find("(" + matches[0] + ")");
if (SearchAndReplace(tmpString, "(" + matches[0] +
")", "", 1, true) == 1)
{
Permutation otherPerms(tmpString);
vector<string> *otherMatches = otherPerms.GetResult();
for (unsigned int i = 0; i < otherMatches->size(); i++)
{
m_result.push_back(otherMatches->at(i));
m_result.push_back(m_value.substr(0, pos) +
matches[0] + otherMatches->at(i).substr(pos));
}
}
}
else
{
m_result.push_back(m_value);
}
}
Once this first step of taking care of content between parenthesis is done, decisions within atomic nodes need to be handled. An atomic node with a decision is like [DEFINITE_ARTICLE | INDEFINITE_ARTICLE], where the part-of-speech is a choice, or [WH_PRONOUN & "who" | "where" | "when" | "which"], where the spelling constraint is also a choice. Most of the logic is in POSTransformScript::FlattenOneDecisionNodes, which itself relies heavily on POSNode::Construct for parsing.
vector<string> POSTransformScript::FlattenOneDecisionNodes(string dLine)
{
vector<string> dReturn;
vector<string> matches;
if (PatternMatch(dLine, "[*]", &matches, true) > 0)
{
for (unsigned int i = 0; i < matches.size(); i++)
{
vector<shared_auto_ptr<posnode />> possibilities;
POSNode::Construct("[" + matches[i] + "]", &possibilities);
if (possibilities.size() > 1)
{
for (unsigned int j = 0; j < possibilities.size(); j++)
{
string dLineCopy = dLine;
SearchAndReplace(dLineCopy, "[" + matches[i] + "]",
possibilities[j].get()->GetNodeDesc(), 1);
vector<string> dNewLineCopies = FlattenOneDecisionNodes(dLineCopy);
for (unsigned int k = 0; k < dNewLineCopies.size(); k++)
{
dReturn.push_back(dNewLineCopies[k]);
}
}
break;
}
}
}
if (dReturn.size() == 0)
{
dReturn.push_back(dLine);
}
return dReturn;
}
shared_auto_ptr<POSNode> POSNode::Construct(string dNodeDesc,
vector<shared_auto_ptr<POSNode>> *allPOSNodes,
unsigned int dStartPosition,
unsigned int dEndPosition,
unsigned int dBridgePosition,
string data)
{
vector<shared_auto_ptr<POSNode>> tmpVector;
if (allPOSNodes == NULL)
{
allPOSNodes = &tmpVector;
}
vector<string> matches;
vector<string> spellings;
vector<POSEntry> dPOS;
string dLeftPart = "";
if (PatternMatch(dNodeDesc, "[* & *]", &matches, false) == 2)
{
dLeftPart = matches[0];
string dRightPart = matches[1];
if (PatternMatch(dRightPart, "\"*\"", &matches, true, "|") > 0)
{
for (unsigned int i = 0; i < matches.size(); i++)
{
spellings.push_back(matches[i]);
}
}
}
else
{
matches.clear();
if (PatternMatch(dNodeDesc, "[*]", &matches, false) == 1)
{
dLeftPart = matches[0];
}
else
{
throw new exception("Formatting error");
}
}
while (dLeftPart.length())
{
matches.clear();
if (PatternMatch(dLeftPart, "* | *", &matches, false) == 2)
{
dPOS.push_back(POSEntry(matches[0]));
dLeftPart = matches[1];
}
else
{
dPOS.push_back(POSEntry(dLeftPart));
dLeftPart = "";
}
}
if ((spellings.size() > 0) && (dPOS.size() > 0))
{
for (unsigned int i = 0; i < dPOS.size(); i++)
{
for (unsigned int j = 0; j < spellings.size(); j++)
{
allPOSNodes->push_back(shared_auto_ptr<POSNode>(
new POSNode(dPOS[i], spellings[j], dStartPosition,
dEndPosition, dBridgePosition, data)));
}
}
}
else if (dPOS.size() > 0)
{
for (unsigned int i = 0; i < dPOS.size(); i++)
{
allPOSNodes->push_back(shared_auto_ptr<POSNode>(
new POSNode(dPOS[i], "", dStartPosition,
dEndPosition, dBridgePosition, data)));
}
}
if (allPOSNodes->size() > 0)
{
return shared_auto_ptr<POSNode>(allPOSNodes->at(0));
}
else
{
return NULL;
}
}
Loading the Decision-free Syntax Transform Script
It is only when POSDictionary_flat.txt has been generated that a POSTransformScript object is created and the content from POSDictionary_flat.txt is loaded into it by calling the POSTransformScript::BuildFromFile method. While referring to the class definition that follows, we can see it is fairly simple. A POSTransformScript is simply composed of a vector of POSTransformScriptLines.
#ifndef __POSTRANSFORM_H__
#define __POSTRANSFORM_H__
#include <vector>
#include <string>
#include <stack>
#include "POSNode.h"
#include "POSList.h"
#include "shared_auto_ptr.h"
#include "StoredScriptLine.h"
using std::vector;
using std::string;
using std::stack;
class POSTransformScriptLine
{
public:
friend class POSTransformScript;
int GetLineNumber() const;
int GetRecursivity() const;
string GetLineName() const;
string ReconstructLine() const;
shared_auto_ptr<POSNode> GetTransform() const;
vector<shared_auto_ptr<POSNode>> GetSequence() const;
bool MustRecurse() const;
protected:
POSTransformScriptLine(string lineName,
vector<shared_auto_ptr<POSNode>> dSequence,
shared_auto_ptr<POSNode> dTransform,
int recursivity,
string originalLine,
int lineNumber);
vector<shared_auto_ptr<POSNode>> m_sequence;
shared_auto_ptr<POSNode> m_transform;
string m_lineName;
string m_originalLineContent;
int m_recursivity;
int m_lineNumber;
bool m_mustRecurse;
};
class POSTransformScript
{
public:
friend class POSTransformLine;
POSTransformScript();
void BuildFromFile(string dFileName);
vector<shared_auto_ptr<POSTransformScriptLine>> *GetLines();
string GetDecisionTrees(string dTreesType);
void KeepDecisionTrees(string dTreesType, string dValue);
bool IsDerivedPOS(POSEntry dPOSEntry) const;
static void ManageSyntacticDecisions(string decisionFile,
string dFlatFileName);
private:
static void FlattenDecisions(string dDecisionFileName,
string dFlattenDecisionFileName);
static void FlattenDecisionNodes(string dDecisionFileName,
string dFlattenDecisionFileName);
static vector<string> FlattenOneDecisionNodes(string dLine);
vector<shared_auto_ptr<POSTransformScriptLine>> m_lines;
vector<bool> m_derived;
map<string, string> m_decisionTrees;
};
#endif
Parsing Tokens
Once the Syntactic Transform Script is held in an object in memory, tokens parsing is the next step that is required. That transforms atomic parts-of-speech into complex ones, which in turn are the ones which are later to be relevant to conceptual analysis processing. Since the topic of parsing is subject to a great diversity in regard to implementation algorithms, an abstract interface is preferred.
#ifndef __PARSER_H__
#define __PARSER_H__
#include "shared_auto_ptr.h"
#include "POSTransformScript.h"
class Parser
{
public:
Parser(shared_auto_ptr<POSTransformScript> dScript);
virtual ~Parser();
virtual void ParseList(shared_auto_ptr<POSList> dList) = 0;
protected:
shared_auto_ptr<POSTransformScript> m_script;
};
#endif
The Parser abstract class keeps a reference to the POSTransformScript object that has the details regarding transformations that can happen. The ParseList method is the one responsible for performing the actual transformations for the tokens passed as a parameter in dList.
The Bottom-up Parser: A Simple Parser Implementation
Bottom-up parsing (also called shift-reduce parsing) is a strategy for parsing sentences that attempt to construct a parse tree, beginning at the leaf nodes and working "bottom-up" towards the root. It has the advantage of being a simple algorithm which is typically easy to implement, with the disadvantage of resulting in slow calculations, since all nodes need to be constructed prior to getting to the root node.
#include "BottomUpParser.h"
#include "CalculationContext.h"
#include "POSTransformScript.h"
#include "StringUtils.h"
#include "DigitalConceptBuilder.h"
#include "DebugDefinitions.h"
#ifdef _DEBUG
#define new DEBUG_NEW
#undef THIS_FILE
static char THIS_FILE[] = __FILE__;
#endif
BottomUpParser::BottomUpParser(
shared_auto_ptr<POSTransformScript> dScript): Parser(dScript) {}
BottomUpParser::~BottomUpParser() {}
void BottomUpParser::ParseList(shared_auto_ptr<POSList> dList)
{
string dLastOutput = "";
for (unsigned int i = 0; i < m_script->GetLines()->size(); i++)
{
if (DigitalConceptBuilder::
GetCurCalculationContext()->SyntacticAnalysisTrace())
{
if (i == 0)
{
originalprintf("\nBottom-up Syntactic trace:\n\n");
}
for (unsigned int j = 0; j < dLastOutput.length(); j++)
{
originalprintf("\b");
originalprintf(" ");
originalprintf("\b");
}
dLastOutput = FormattedString(
"%d of %d. line \"%s\" (%lu so far)",
i+1, m_script->GetLines()->size(),
m_script->GetLines()->at(i)->GetLineName().c_str(),
dList->Count());
originalprintf(dLastOutput.c_str());
}
BottomUpLineParse(dList, m_script->GetLines()->at(i));
}
for (unsigned int j = 0; j < dLastOutput.length(); j++)
{
originalprintf("\b");
originalprintf(" ");
originalprintf("\b");
}
}
int BottomUpParser::BottomUpLineParse(shared_auto_ptr<POSList> dList,
shared_auto_ptr<POSTransformScriptLine> dLine,
int fromIndex,
int atPosition,
int lowestPos,
string cummulatedString,
vector<shared_auto_ptr<POSNode>> *cummulatedNodes)
{
vector<shared_auto_ptr<POSNode>> childNodes;
if (cummulatedNodes == NULL)
{
cummulatedNodes = &childNodes;
}
int dTransformCount = 0;
if (fromIndex == -1)
{
fromIndex = 0;
}
int fromPosition = atPosition;
int toPosition = atPosition;
if (atPosition == -1)
{
fromPosition = dList->GetLowestStartPosition();
toPosition = dList->GetHighestEndPosition();
}
for (int i = 0; i < dLine->GetRecursivity(); i++)
{
dTransformCount = 0;
for (int pos = fromPosition; pos <= toPosition; pos++)
{
vector<shared_auto_ptr<POSNode> > dNodes =
dList->BrigdgeableNodes(pos, dLine->GetSequence()[fromIndex]);
for (unsigned int j = 0; j < dNodes.size(); j++)
{
if (fromIndex == (dLine->GetSequence().size() - 1))
{
dTransformCount++;
string dSpelling = cummulatedString + " " +
dNodes[j]->GetSpelling();
RemovePadding(dSpelling, ' ');
shared_auto_ptr<POSNode> dNewNode(new POSNode(
dLine->GetTransform()->GetPOSEntry(), dSpelling,
(lowestPos == -1)?pos:lowestPos, dNodes[j]->GetEndPosition(),
dNodes[j]->GetBridgePosition()));
dNewNode->SetConstructionLine(dLine->GetLineName());
for (unsigned int k = 0; k < cummulatedNodes->size(); k++)
{
cummulatedNodes->at(k)->SetParent(dNewNode);
}
dNodes[j]->SetParent(dNewNode);
dList->AddToPOSList(dNewNode);
}
else
{
if (dNodes[j]->GetBridgePosition() != 0)
{
int sizeBefore = cummulatedNodes->size();
cummulatedNodes->push_back(dNodes[j]);
dTransformCount += BottomUpLineParse(dList, dLine,
fromIndex+1, dNodes[j]->GetBridgePosition(),
(lowestPos == -1)?pos:lowestPos, cummulatedString +
" " + dNodes[j]->GetSpelling(), cummulatedNodes);
while ((int)cummulatedNodes->size() > sizeBefore)
{
cummulatedNodes->erase(cummulatedNodes->begin() +
cummulatedNodes->size() - 1);
}
}
}
}
}
if ((dTransformCount == 0) || (!dLine->MustRecurse()))
{
break;
}
}
return dTransformCount;
}
The Multi-dimensional Earley Parser: A More Efficient Parsing Method
An Earley parser is essentially a generator that builds left-most derivations, using a given set of sequence productions. The parsing functionality arises because the generator keeps track of all possible derivations that are consistent with the input up to a certain point. As more and more of the input is revealed, the set of possible derivations (each of which corresponds to a parse) can either expand as new choices are introduced, or shrink as a result of resolved ambiguities. Typically, an Earley parser does not deal with an ambiguous input as it requires a one-dimensional sequence of tokens. But, in our case, there is ambiguity since each word may have generated multiple tokens that have different parts-of-speech. This is the reason why the algorithm is adapted and named a multi-dimensional Earley parser.
#include "MultiDimEarleyParser.h"
#include "CalculationContext.h"
#include "POSTransformScript.h"
#include "StringUtils.h"
#include "DigitalConceptBuilder.h"
#include "DebugDefinitions.h"
#ifdef _DEBUG
#define new DEBUG_NEW
#undef THIS_FILE
static char THIS_FILE[] = __FILE__;
#endif
class ScriptMultiDimEarleyInfo
{
public:
map<int, vector<shared_auto_ptr<POSTransformScriptLine>>>
m_startPOSLines;
};
class UnfinishedTranformLine
{
public:
UnfinishedTranformLine();
UnfinishedTranformLine(
shared_auto_ptr<POSTransformScriptLine> dTransformLine);
shared_auto_ptr<POSTransformScriptLine> m_transformLine;
vector<shared_auto_ptr<POSNode>> m_cummulatedNodes;
};
map<uintptr_t, ScriptMultiDimEarleyInfo>
MultiDimEarleyParser::m_scriptsExtraInfo;
MultiDimEarleyParser::MultiDimEarleyParser(
shared_auto_ptr<POSTransformScript> dScript): Parser(dScript) {}
MultiDimEarleyParser::~MultiDimEarleyParser() {}
void MultiDimEarleyParser::ParseList(shared_auto_ptr<POSList> dList)
{
m_listParsed = dList;
MultiDimEarleyParser::BuildDecisionsTree(m_script);
shared_auto_ptr<POSNode> dPOSNode;
m_derivedNodesLookup.Clear();
m_derivedNodesProduced.Clear();
m_targetNodesProduced.Clear();
dList->GetPositionInList()->Reset();
while (dList->GetPositionInList()->GetNext(dPOSNode))
{
NodeDecisionProcessing(dPOSNode);
ProcessAgainstUnfinishedLines(dPOSNode);
}
while ((m_delayedSuccessCondition.size() > 0) &&
(m_targetNodesProduced.Count() <
(unsigned long)DigitalConceptBuilder::
GetCurCalculationContext()->GetMaxSyntaxPermutations()))
{
SuccessNodeCondition(
m_delayedSuccessCondition.front().m_partialLine,
m_delayedSuccessCondition.front().m_POSNode);
m_delayedSuccessCondition.pop();
}
m_targetNodesProduced.GetPositionInList()->Reset();
while (m_targetNodesProduced.GetPositionInList()->GetNext(dPOSNode))
{
dList->AddToPOSList(dPOSNode);
}
m_derivedNodesProduced.GetPositionInList()->Reset();
while (m_derivedNodesProduced.GetPositionInList()->GetNext(dPOSNode))
{
dList->AddToPOSList(dPOSNode);
}
m_decisionTrees.clear();
m_derivedNodesLookup.Clear();
m_targetNodesProduced.Clear();
Trace("");
}
void MultiDimEarleyParser::SuccessNodeCondition(
shared_auto_ptr<UnfinishedTranformLine> dPartialLine,
shared_auto_ptr<POSNode> dPOSNode)
{
if (m_targetNodesProduced.Count() >=
(unsigned long)DigitalConceptBuilder::
GetCurCalculationContext()->GetMaxSyntaxPermutations())
{
return;
}
dPartialLine->m_cummulatedNodes.push_back(dPOSNode);
if (dPartialLine->m_cummulatedNodes.size() ==
dPartialLine->m_transformLine->GetSequence().size())
{
shared_auto_ptr<POSNode> dPOSNode(new POSNode(
dPartialLine->m_transformLine->GetTransform()->GetPOSEntry()));
dPOSNode->SetConstructionLine(
dPartialLine->m_transformLine->GetLineName());
unsigned int i;
for (i = 0; i < dPartialLine->m_cummulatedNodes.size(); i++)
{
dPartialLine->m_cummulatedNodes[i]->SetParent(dPOSNode);
}
dPOSNode->UpdateFromChildValues();
ProcessAgainstUnfinishedLines(dPOSNode);
m_derivedNodesProduced.AddToPOSList(dPOSNode);
NodeDecisionProcessing(dPOSNode);
if ((dPOSNode->GetEndPosition() - dPOSNode->GetStartPosition() >=
(unsigned int)(m_listParsed->GetHighestEndPosition() -
m_listParsed->GetLowestStartPosition() - 1)) &&
(DigitalConceptBuilder::
GetCurCalculationContext()->GetTargetPOS().GetValue() ==
dPOSNode->GetPOSEntry().GetValue()))
{
m_targetNodesProduced.AddToPOSList(dPOSNode);
}
}
else if (dPOSNode->GetBridgePosition() > dPOSNode->GetEndPosition())
{
shared_auto_ptr<UnfinishedTranformLine> usePartialLine = dPartialLine;
if (m_script->IsDerivedPOS(
dPartialLine->m_transformLine->GetSequence().at(
dPartialLine->m_cummulatedNodes.size())->GetPOSEntry()))
{
shared_auto_ptr<UnfinishedTranformLine>
dPartialLineCopy(new UnfinishedTranformLine());
*dPartialLineCopy.get() = *dPartialLine.get();
m_derivedNodesLookup.Add(dPartialLineCopy, dPOSNode->GetBridgePosition(),
dPartialLine->m_transformLine->GetSequence().at(
dPartialLine->m_cummulatedNodes.size())->GetPOSEntry());
usePartialLine = dPartialLineCopy;
}
shared_auto_ptr<POSNode> dTestNode =
usePartialLine->m_transformLine->GetSequence()
[usePartialLine->m_cummulatedNodes.size()];
BridgeableNodesProcessing(dPOSNode->GetBridgePosition(),
dTestNode, &usePartialLine->m_cummulatedNodes,
usePartialLine->m_transformLine);
}
}
void MultiDimEarleyParser::ProcessAgainstUnfinishedLines(
shared_auto_ptr<POSNode> dPOSNode)
{
vector<shared_auto_ptr<UnfinishedTranformLine>> dUnfinishedLines =
m_derivedNodesLookup.ObjectsAtPosition(dPOSNode->GetStartPosition(),
dPOSNode->GetPOSEntry(), NULL);
for (unsigned long i = 0; i < dUnfinishedLines.size(); i++)
{
if (dPOSNode->Compare(*dUnfinishedLines[i]->
m_transformLine->GetSequence()[dUnfinishedLines[i]->
m_cummulatedNodes.size()].get()) == 0)
{
shared_auto_ptr<UnfinishedTranformLine>
dPartialLineCopy(new UnfinishedTranformLine());
*dPartialLineCopy.get() = *dUnfinishedLines[i].get();
m_delayedSuccessCondition.push(
DelayedSuccessCondition(dPartialLineCopy, dPOSNode));
}
}
}
void MultiDimEarleyParser::BridgeableNodesProcessing(unsigned int dPosition,
shared_auto_ptr<POSNode> dTestNode,
vector<shared_auto_ptr<POSNode>> *resolvedNodes,
shared_auto_ptr<POSTransformScriptLine> scriptLine)
{
if (m_script->IsDerivedPOS(dTestNode->GetPOSEntry()))
{
vector<shared_auto_ptr<POSNode>> dNodes =
m_derivedNodesProduced.BrigdgeableNodes(dPosition, dTestNode);
for (unsigned int j = 0; j < dNodes.size(); j++)
{
OneNodeCompareInDecisionTree(dNodes[j], scriptLine, resolvedNodes);
}
}
vector<shared_auto_ptr<POSNode>> dNodes =
m_listParsed->BrigdgeableNodes(dPosition, dTestNode);
for (unsigned int j = 0; j < dNodes.size(); j++)
{
OneNodeCompareInDecisionTree(dNodes[j], scriptLine, resolvedNodes);
}
}
void MultiDimEarleyParser::NodeDecisionProcessing(unsigned int dPosition,
IndexStructureNode<StoredScriptLine> *fromNode,
vector<shared_auto_ptr<POSNode>> *resolvedNodes)
{
vector<shared_auto_ptr<POSTransformScriptLine>> *options =
SetUpForNodeProcessing(resolvedNodes->at(0)->GetPOSEntry());
if (options != NULL)
{
for (unsigned int i = 0; i < options->size(); i++)
{
shared_auto_ptr<POSTransformScriptLine> dAssociatedLine = options->at(i);
shared_auto_ptr<POSNode> dTestNode =
dAssociatedLine->GetSequence()[resolvedNodes->size()];
BridgeableNodesProcessing(dPosition, dTestNode,
resolvedNodes, options->at(i));
}
}
}
void MultiDimEarleyParser::OneNodeCompareInDecisionTree(shared_auto_ptr<POSNode> dPOSNode,
shared_auto_ptr<POSTransformScriptLine> scriptLine,
vector<shared_auto_ptr<POSNode>> *resolvedNodes)
{
unsigned int node2Compare = 0;
if (resolvedNodes != NULL)
{
node2Compare = resolvedNodes->size();
}
if (dPOSNode->Compare(*scriptLine->GetSequence()[node2Compare].get()) == 0)
{
shared_auto_ptr<UnfinishedTranformLine>
dPartialLine(new UnfinishedTranformLine(scriptLine));
if (resolvedNodes != NULL)
{
dPartialLine->m_cummulatedNodes = *resolvedNodes;
SuccessNodeCondition(dPartialLine, dPOSNode);
}
else
{
m_delayedSuccessCondition.push(
DelayedSuccessCondition(dPartialLine, dPOSNode));
}
}
}
vector<shared_auto_ptr<POSTransformScriptLine>>
*MultiDimEarleyParser::SetUpForNodeProcessing(POSEntry dPOSEntryTree)
{
if (m_scriptsExtraInfo.find((uintptr_t)m_script.get()) != m_scriptsExtraInfo.end())
{
if (m_scriptsExtraInfo[(uintptr_t)m_script.get()].m_startPOSLines.find(
dPOSEntryTree.GetValue()) !=
m_scriptsExtraInfo[(unsigned long)m_script.get()].m_startPOSLines.end())
{
return &m_scriptsExtraInfo[
(uintptr_t)m_script.get()].m_startPOSLines[dPOSEntryTree.GetValue()];
}
}
return NULL;
}
void MultiDimEarleyParser::NodeDecisionProcessing(
shared_auto_ptr<POSNode> dPOSNode,
IndexStructureNode<StoredScriptLine> *fromNode,
vector<shared_auto_ptr<POSNode>> *resolvedNodes)
{
Trace(FormattedString("NodeDecisionProcessing for node %s",
dPOSNode->GetNodeDesc().c_str()));
vector<shared_auto_ptr<POSTransformScriptLine>> *options =
SetUpForNodeProcessing(dPOSNode->GetPOSEntry());
if (options != NULL)
{
for (unsigned int i = 0; i < options->size(); i++)
{
OneNodeCompareInDecisionTree(dPOSNode,
options->at(i), resolvedNodes);
}
}
}
void MultiDimEarleyParser::BuildDecisionsTree(
shared_auto_ptr<POSTransformScript> dScript)
{
if (m_scriptsExtraInfo.find((uintptr_t)dScript.get()) ==
m_scriptsExtraInfo.end())
{
fstream dOutputStream;
dOutputStream.open("LineNumbers.txt",
ios::out | ios::binary | ios::trunc);
for (unsigned int i = 0; i < dScript->GetLines()->size(); i++)
{
string sequence;
for (unsigned int j = 0; j <
dScript->GetLines()->at(i)->GetSequence().size(); j++)
{
sequence +=
dScript->GetLines()->at(i)->GetSequence().at(j)->GetNodeDesc();
}
dOutputStream << FormattedString("%d. %s: %s -> %s\r\n", i,
dScript->GetLines()->at(i)->GetLineName().c_str(), sequence.c_str(),
dScript->GetLines()->at(i)->GetTransform()->GetNodeDesc().c_str()).c_str();
m_scriptsExtraInfo[(uintptr_t)dScript.get()].m_startPOSLines[
dScript->GetLines()->at(i)->GetSequence().at(0)->
GetPOSEntry().GetValue()].push_back(dScript->GetLines()->at(i));
}
dOutputStream.close();
}
}
void MultiDimEarleyParser::Trace(string dTraceString)
{
if (DigitalConceptBuilder::GetCurCalculationContext()->SyntacticAnalysisTrace())
{
for (unsigned int j = 0; j < m_lastTraceOutput.length(); j++)
{
originalprintf("\b");
originalprintf(" ");
originalprintf("\b");
}
if (dTraceString.length() > 0)
{
originalprintf(dTraceString.c_str());
}
m_lastTraceOutput = dTraceString;
}
}
UnfinishedTranformLine::UnfinishedTranformLine() {}
UnfinishedTranformLine::UnfinishedTranformLine(
shared_auto_ptr<POSTransformScriptLine> dTransformLine):
m_transformLine(dTransformLine) {}
DelayedSuccessCondition::DelayedSuccessCondition(
shared_auto_ptr<UnfinishedTranformLine> dPartialLine,
shared_auto_ptr<POSNode> dPOSNode):
m_partialLine(dPartialLine), m_POSNode(dPOSNode) {}
Syntactic Analysis calculates complex nodes from an input of atomic nodes, yet it provides the algorithm with an ambiguous set of results.
The following content is taken from SimpleTestCases.txt. MAXSYNTAXPERMUTATIONS and MAXCONCEPTUALANALYSIS are two key variables used to determine how many syntactic permutations are calculated in a conceptual representation.
...
# MAXSYNTAXPERMUTATIONS
# _____________________
#
# Possible values: Numeric value
#
# The maximal amount of TARGETPOS that syntactic analysis should
# produce.
MAXSYNTAXPERMUTATIONS = 200
#-------------------------------------------------------------------
# MAXCONCEPTUALANALYSIS
# _____________________
#
# Possible values: Numeric value
#
# The maximal amount of TARGETPOS that conceptual analysis should
# analyze. From the MAXSYNTAXPERMUTATIONS sequences of TARGETPOS that
# are sorted, only the fist MAXCONCEPTUALANALYSIS will be analyzed.
MAXCONCEPTUALANALYSIS = 20
...
Under the default condition of SimpleTestCases.txt left untouched, but with OUTPUTSYNTAXPERMUTATIONS set to TRUE, the following output is generated for the 18th test-case:
Evaluating: "Is a car that is not red a blue car?" (ID:CAR18)
CAR18:1. {SENTENCE: IS[VERB] {NOUN_PHRASE: {NOUN_PHRASE:
A[DEFINITE_ARTICLE] CAR[NOUN] } {REL_CLAUSE: THAT[PRONOUN]
{VERB_PHRASE: IS[VERB] NOT[ADVERB] {NOUN_PHRASE: RED[NOUN] } } } }
{NOUN_PHRASE: A[DEFINITE_ARTICLE] {ADJECTIVE_PHRASE:
BLUE[ADJECTIVE] } CAR[NOUN] } ?[PUNCTUATION] }
CAR18:2. {SENTENCE: IS[VERB] {NOUN_PHRASE: {NOUN_PHRASE:
A[DEFINITE_ARTICLE] CAR[NOUN] } {REL_CLAUSE: THAT[PRONOUN]
{VERB_PHRASE: IS[VERB] NOT[ADVERB] {NOUN_PHRASE: RED[NOUN] } } } }
{NOUN_PHRASE: {NOUN_PHRASE: A[DEFINITE_ARTICLE] BLUE[NOUN] }
{NOUN_PHRASE: CAR[NOUN] } } ?[PUNCTUATION] }
CAR18:3. {SENTENCE: {VERB_PHRASE: IS[VERB] {NOUN_PHRASE:
A[DEFINITE_ARTICLE] CAR[NOUN] } {REL_CLAUSE: THAT[PRONOUN]
{VERB_PHRASE: IS[VERB] NOT[ADVERB] {NOUN_PHRASE:
{NOUN_PHRASE: RED[NOUN] } {NOUN_PHRASE: A[DEFINITE_ARTICLE]
{ADJECTIVE_PHRASE: BLUE[ADJECTIVE] } CAR[NOUN] } } } } } ?[PUNCTUATION] }
CAR18:4. {SENTENCE: IS[VERB] {NOUN_PHRASE: {NOUN_PHRASE:
A[DEFINITE_ARTICLE] CAR[NOUN] } {REL_CLAUSE: THAT[PRONOUN]
{VERB_PHRASE: {VERB_PHRASE: IS[VERB] NOT[ADVERB] {NOUN_PHRASE: RED[NOUN] } }
{NOUN_PHRASE: A[DEFINITE_ARTICLE] BLUE[NOUN] } } } }
{NOUN_PHRASE: CAR[NOUN] } ?[PUNCTUATION] }
CAR18:5. {SENTENCE: IS[AUX] {NOUN_PHRASE: {NOUN_PHRASE:
A[DEFINITE_ARTICLE] CAR[NOUN] } {NOUN_PHRASE: THAT[PRONOUN] } }
{VERB_PHRASE: {VERB_PHRASE: IS[VERB] NOT[ADVERB]
{NOUN_PHRASE: RED[NOUN] } } {NOUN_PHRASE: A[DEFINITE_ARTICLE]
{ADJECTIVE_PHRASE: BLUE[ADJECTIVE] } CAR[NOUN] } } ?[PUNCTUATION] }
CAR18:6. {SENTENCE: {VERB_PHRASE: IS[VERB] {NOUN_PHRASE:
A[DEFINITE_ARTICLE] CAR[NOUN] } {REL_CLAUSE: THAT[PRONOUN]
{VERB_PHRASE: {VERB_PHRASE: IS[VERB] NOT[ADVERB]
{NOUN_PHRASE: RED[NOUN] } } {NOUN_PHRASE: A[DEFINITE_ARTICLE]
{ADJECTIVE_PHRASE: BLUE[ADJECTIVE] } CAR[NOUN] } } } } ?[PUNCTUATION] }
CAR18:7. {SENTENCE: IS[AUX] {NOUN_PHRASE:
A[DEFINITE_ARTICLE] CAR[NOUN] } {VERB_PHRASE: {VERB_PHRASE:
{VERB_PHRASE: {NOUN_PHRASE: THAT[PRONOUN] } IS[VERB] }
{ADJECTIVE_PHRASE: NOT[ADVERB] RED[ADJECTIVE] } }
{NOUN_PHRASE: A[DEFINITE_ARTICLE]
{ADJECTIVE_PHRASE: BLUE[ADJECTIVE] } CAR[NOUN] } } ?[PUNCTUATION] }
CAR18:8. {SENTENCE: IS[AUX] {NOUN_PHRASE: {NOUN_PHRASE:
A[DEFINITE_ARTICLE] CAR[NOUN] } {NOUN_PHRASE: THAT[PRONOUN] } }
{VERB_PHRASE: IS[VERB] NOT[ADVERB] {NOUN_PHRASE: {NOUN_PHRASE: RED[NOUN] }
{NOUN_PHRASE: A[DEFINITE_ARTICLE]
{ADJECTIVE_PHRASE: BLUE[ADJECTIVE] } CAR[NOUN] } } } ?[PUNCTUATION] }
CAR18:9. {SENTENCE: IS[VERB] {NOUN_PHRASE: {NOUN_PHRASE:
{NOUN_PHRASE: A[DEFINITE_ARTICLE] CAR[NOUN] }
{REL_CLAUSE: THAT[PRONOUN] {VERB_PHRASE: IS[VERB] NOT[ADVERB]
{NOUN_PHRASE: RED[NOUN] } } } }
{NOUN_PHRASE: A[DEFINITE_ARTICLE] BLUE[NOUN] } }
{NOUN_PHRASE: CAR[NOUN] } ?[PUNCTUATION] }
CAR18:10. {SENTENCE: {VERB_PHRASE: {VERB_PHRASE: IS[VERB]
{NOUN_PHRASE: A[DEFINITE_ARTICLE] CAR[NOUN] }
{REL_CLAUSE: THAT[PRONOUN] {VERB_PHRASE: IS[VERB] NOT[ADVERB]
{NOUN_PHRASE: RED[NOUN] } } } } {NOUN_PHRASE: A[DEFINITE_ARTICLE]
{ADJECTIVE_PHRASE: BLUE[ADJECTIVE] } CAR[NOUN] } } ?[PUNCTUATION] }
CAR18:11. {SENTENCE: IS[VERB] {NOUN_PHRASE:
{NOUN_PHRASE: A[DEFINITE_ARTICLE] CAR[NOUN] }
{REL_CLAUSE: THAT[PRONOUN] {VERB_PHRASE: IS[VERB]
NOT[ADVERB] {NOUN_PHRASE: {NOUN_PHRASE: RED[NOUN] }
{NOUN_PHRASE: A[DEFINITE_ARTICLE] BLUE[NOUN] } } } } }
{NOUN_PHRASE: CAR[NOUN] } ?[PUNCTUATION] }
CAR18:12. {SENTENCE: {VERB_PHRASE: {VERB_PHRASE: IS[VERB]
{NOUN_PHRASE: A[DEFINITE_ARTICLE] CAR[NOUN] }
{REL_CLAUSE: THAT[PRONOUN] {VERB_PHRASE: IS[VERB]
NOT[ADVERB] {NOUN_PHRASE: {NOUN_PHRASE: RED[NOUN] }
{NOUN_PHRASE: A[DEFINITE_ARTICLE] BLUE[NOUN] } } } } }
{NOUN_PHRASE: CAR[NOUN] } } ?[PUNCTUATION] }
CAR18:13. {SENTENCE: {VERB_PHRASE: IS[VERB]
{NOUN_PHRASE: {NOUN_PHRASE: A[DEFINITE_ARTICLE] CAR[NOUN] }
{REL_CLAUSE: THAT[PRONOUN] {VERB_PHRASE: IS[VERB] NOT[ADVERB]
{NOUN_PHRASE: {NOUN_PHRASE: RED[NOUN] }
{NOUN_PHRASE: A[DEFINITE_ARTICLE]
{ADJECTIVE_PHRASE: BLUE[ADJECTIVE] }
CAR[NOUN] } } } } } } ?[PUNCTUATION] }
CAR18:14. {SENTENCE: {VERB_PHRASE: IS[VERB]
{NOUN_PHRASE: A[DEFINITE_ARTICLE] CAR[NOUN] }
{REL_CLAUSE: THAT[PRONOUN] {VERB_PHRASE: {VERB_PHRASE:
{VERB_PHRASE: IS[VERB] NOT[ADVERB]
{NOUN_PHRASE: RED[NOUN] } }
{NOUN_PHRASE: A[DEFINITE_ARTICLE] BLUE[NOUN] } }
{NOUN_PHRASE: CAR[NOUN] } } } } ?[PUNCTUATION] }
CAR18:15. {SENTENCE: {VERB_PHRASE: IS[VERB]
{NOUN_PHRASE: {NOUN_PHRASE: A[DEFINITE_ARTICLE] CAR[NOUN] }
{REL_CLAUSE: THAT[PRONOUN] {VERB_PHRASE:
{VERB_PHRASE: IS[VERB] NOT[ADVERB] {NOUN_PHRASE: RED[NOUN] } }
{NOUN_PHRASE: A[DEFINITE_ARTICLE]
{ADJECTIVE_PHRASE: BLUE[ADJECTIVE] }
CAR[NOUN] } } } } } ?[PUNCTUATION] }
CAR18:16. {SENTENCE: {VERB_PHRASE: IS[VERB]
{NOUN_PHRASE: A[DEFINITE_ARTICLE] CAR[NOUN] }
{REL_CLAUSE: THAT[PRONOUN] {VERB_PHRASE: IS[VERB] NOT[ADVERB]
{NOUN_PHRASE: {NOUN_PHRASE: {NOUN_PHRASE: RED[NOUN] }
{NOUN_PHRASE: A[DEFINITE_ARTICLE] BLUE[NOUN] } }
{NOUN_PHRASE: CAR[NOUN] } } } } } ?[PUNCTUATION] }
CAR18:17. {SENTENCE: IS[AUX]
{NOUN_PHRASE: A[DEFINITE_ARTICLE] CAR[NOUN] }
{VERB_PHRASE: {VERB_PHRASE: {VERB_PHRASE:
{NOUN_PHRASE: THAT[PRONOUN] } IS[VERB] }
{ADJECTIVE_PHRASE: NOT[ADVERB] RED[ADJECTIVE] } }
{NOUN_PHRASE: {NOUN_PHRASE: A[DEFINITE_ARTICLE] BLUE[NOUN] }
{NOUN_PHRASE: CAR[NOUN] } } } ?[PUNCTUATION] }
CAR18:18. {SENTENCE: {VERB_PHRASE:
{VERB_PHRASE: IS[VERB]
{NOUN_PHRASE: A[DEFINITE_ARTICLE] CAR[NOUN] }
{REL_CLAUSE: THAT[PRONOUN] {VERB_PHRASE:
{VERB_PHRASE: IS[VERB] NOT[ADVERB] {NOUN_PHRASE: RED[NOUN] } }
{NOUN_PHRASE: A[DEFINITE_ARTICLE] BLUE[NOUN] } } } }
{NOUN_PHRASE: CAR[NOUN] } } ?[PUNCTUATION] }
CAR18:19. {SENTENCE: IS[AUX]
{NOUN_PHRASE: A[DEFINITE_ARTICLE] CAR[NOUN] }
{VERB_PHRASE: {VERB_PHRASE: {VERB_PHRASE:
{VERB_PHRASE: {NOUN_PHRASE: THAT[PRONOUN] } IS[VERB] }
{ADJECTIVE_PHRASE: NOT[ADVERB] RED[ADJECTIVE] } }
{NOUN_PHRASE: A[DEFINITE_ARTICLE] BLUE[NOUN] } }
{NOUN_PHRASE: CAR[NOUN] } } ?[PUNCTUATION] }
CAR18:20. {SENTENCE: IS[AUX]
{NOUN_PHRASE: {NOUN_PHRASE: A[DEFINITE_ARTICLE] CAR[NOUN] }
{NOUN_PHRASE: THAT[PRONOUN] } } {VERB_PHRASE:
{VERB_PHRASE: IS[VERB] NOT[ADVERB] {NOUN_PHRASE: RED[NOUN] } }
{NOUN_PHRASE: {NOUN_PHRASE: A[DEFINITE_ARTICLE] BLUE[NOUN] }
{NOUN_PHRASE: CAR[NOUN] } } } ?[PUNCTUATION] }
MAYBE:
DO[ACTION:RECEIVEINPUT
MOOD:INTEROGATIVE
OBJECT:DO[OPERATION:IS
VALUE1:PP[CLASS:CAR
COLOR:!RED
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]
VALUE2:PP[CLASS:CAR
COLOR:BLUE
QUANTITY:1
TYPE:VEHICLE
WHEELCOUNT:4]]]
Total time: 13 sec (13125 ms)
Syntactic: 937 ms
Conceptual: 12 sec (12188 ms).
Lines have been wrapped in the above snippet to avoid scrolling.
See the complete output for all test-cases here.
We can see that a total of 20 syntactic permutations are calculated - the value specified in MAXCONCEPTUALANALYSIS. That limits the amount of syntactically ambiguous input provided to the conceptual analyzer. With an adaptation of the same test-case in order to explore how many syntactic permutations are generated in total, the following change to SimpleTestCases.txt is made:
...
{
ENABLED = TRUE
OUTPUTSYNTAXPERMUTATIONS = TRUE
MAXSYNTAXPERMUTATIONS = 2000000
MAXCONCEPTUALANALYSIS = 2000000
CONTENT = Is a car that is not red a blue car?
ID = CAR18
}
...
See the resulting output here.
The calculations result in the production of 350 syntactic permutations instead of the original 20. The calculations also required four minutes instead of the original 13 seconds since it explored more syntactic permutations; yet, it yields the same response. Consequently, it is important to limit how many syntactic permutations are calculated for a concept. A criterion is needed in order to determine which syntactic permutations are kept and which are excluded if a limit on the amount of syntactic permutations analyzed to MAXCONCEPTUALANALYSIS is desired.
Part of the answer to that key question lies in a human cognitive reflex. That is, for two equivalent possibilities, humans prefer the simplest one. The human brain would rather analyze a simple syntactic structure than a complex one. But, how exactly is the simplicity of a syntactic structure determined? From experience, minimizing how many nodes compose a syntactic permutation does a good job at identifying the simplest syntactic structure.
Let us look closer at the syntactic permutations that are generated, and compare some of them with that knowledge in mind.
CAR18:1. {SENTENCE: IS[VERB] {NOUN_PHRASE:
{NOUN_PHRASE: A[DEFINITE_ARTICLE] CAR[NOUN] }
{REL_CLAUSE: THAT[PRONOUN]
{VERB_PHRASE: IS[VERB] NOT[ADVERB]
{NOUN_PHRASE: RED[NOUN] } } } }
{NOUN_PHRASE: A[DEFINITE_ARTICLE]
{ADJECTIVE_PHRASE: BLUE[ADJECTIVE] } CAR[NOUN] } ?[PUNCTUATION] }
...
CAR18:91. {SENTENCE: {SENTENCE: {VERB_PHRASE:
{VERB_PHRASE: IS[VERB]
{NOUN_PHRASE: A[DEFINITE_ARTICLE] CAR[NOUN] } }
{NOUN_PHRASE: THAT[PRONOUN] } } } {SENTENCE:
{VERB_PHRASE: {VERB_PHRASE:
{VERB_PHRASE: IS[VERB] NOT[ADVERB]
{NOUN_PHRASE: RED[NOUN] } }
{NOUN_PHRASE: A[DEFINITE_ARTICLE] BLUE[NOUN] } }
{NOUN_PHRASE: CAR[NOUN] } } ?[PUNCTUATION] } }
Lines have been wrapped in the above snippet to avoid scrolling.
The first syntactic permutation has 8 complex nodes, while the 91st syntactic permutation has 13 complex nodes. There is one SENTENCE node in the first syntactic permutation, while the 91st has three SENTENCE nodes. It is safe to say that a human brain analyzing a syntactic permutation of the 91st type has a harder time formulating a concept than from the first!
Consequently, as an immutable rule regarding which syntactic permutation is calculated first, it is a postulate in a CLUE that syntactic permutations that are composed of the fewest nodes are preferred. This, in the code, transpires as a sort of POSNode objects into a POSList.
vector<shared_auto_ptr<POSNode>> POSList::AccumulateAll(
shared_auto_ptr<POSNode> dPOSNode,
POSNode::ESortType sort, int fromPos, int toPos)
{
if (fromPos == -1)
{
fromPos = GetLowestStartPosition();
}
if (toPos == -1)
{
toPos = GetHighestEndPosition();
}
vector<shared_auto_ptr<POSNode>> dReturn;
for (int i = fromPos; i <= toPos; i++)
{
vector<shared_auto_ptr<POSNode>> dPOSFound =
BrigdgeableNodes(i, dPOSNode);
for (unsigned int j = 0; j < dPOSFound.size(); j++)
{
dPOSFound[j]->SetSortRequirement(sort);
dReturn.push_back(dPOSFound[j]);
}
}
if (sort != POSNode::eNoSort)
{
std::sort(dReturn.begin( ), dReturn.end( ), POSNode::CompareNodes);
}
return dReturn;
}
Use the eSortLargestToSmallestNode sort criteria for the purpose of identifying the simplest syntactic permutation, yet with the maximal span from the input stream.
bool POSNode::CompareNodes(shared_auto_ptr<POSNode> elem1,
shared_auto_ptr<POSNode> elem2)
{
if ((elem1->GetEndPosition() - elem1->GetStartPosition()) ==
(elem2->GetEndPosition() - elem2->GetStartPosition()))
{
return elem1->ChildNodeCount() < elem2->ChildNodeCount();
}
switch (elem1->m_sortRequirement)
{
case eSortLargestToSmallestNode:
if ((elem1->GetEndPosition() - elem1->GetStartPosition()) ==
(elem2->GetEndPosition() - elem2->GetStartPosition()))
{
elem1->UpdateNodesCount();
elem2->UpdateNodesCount();
return (elem1->m_totalNodesUnder < elem2->m_totalNodesUnder);
}
else
{
return (elem1->GetEndPosition() - elem1->GetStartPosition()) >
(elem2->GetEndPosition() - elem2->GetStartPosition());
}
break;
case eSortSmallestToLargestNode:
if ((elem1->GetEndPosition() - elem1->GetStartPosition()) ==
(elem2->GetEndPosition() - elem2->GetStartPosition()))
{
elem1->UpdateNodesCount();
elem2->UpdateNodesCount();
return (elem1->m_totalNodesUnder < elem2->m_totalNodesUnder);
}
else
{
return (elem1->GetEndPosition() - elem1->GetStartPosition()) <
(elem2->GetEndPosition() - elem2->GetStartPosition());
}
break;
}
return true;
}
The BuildPredicates Method in POSNode
How exactly is a predicate constructed from a syntactic permutation? The beginning of the answer is in the method POSNode::BuildPredicates that holds much of the Conceptual Analysis logic.
Syntactic Analysis results in numerous POSNode objects of the target part-of-speech. Each POSNode object is composed of [0..N] POSNode objects in the m_children vector. For example, the first SENTENCE from Syntactic Analysis calculations is a POSNode object:
CAR18:1. {SENTENCE: IS[VERB] {NOUN_PHRASE: {NOUN_PHRASE: A[DEFINITE_ARTICLE] CAR[NOUN] } {REL_CLAUSE: THAT[PRONOUN] {VERB_PHRASE: IS[VERB] NOT[ADVERB] {NOUN_PHRASE: RED[NOUN] } } } } {NOUN_PHRASE: A[DEFINITE_ARTICLE] {ADJECTIVE_PHRASE: BLUE[ADJECTIVE] } CAR[NOUN] } ?[PUNCTUATION] }
#ifndef __POSNODE_H__
#define __POSNODE_H__
#include "shared_auto_ptr.h"
#include "JSObjectSupport.h"
#include <string>
#include <vector>
#include "POSEntry.h"
#include "Predicate.h"
using std::string;
using std::vector;
class POSNode: public JSObjectSupport<POSNode>
{
public:
enum ESortType
{
eNoSort = 0,
eSortLargestToSmallestNode = 1,
eSortSmallestToLargestNode = 2
};
enum EDirection
{
eSibling = 0,
eSiblingLeft = 1,
eSiblingRight = 2,
eFirstSibling = 3,
eLastSibling = 4,
eNextSibling = 5,
ePreviousSibling = 6,
eAncestre = 7,
eParent = 8,
eTopParent = 9,
eChild = 10,
eFirstChild = 11,
eLastChild = 12,
eDescendant = 13,
ePreviousWord = 14,
eNextWord = 15,
eFirstWord = 16,
eLastWord = 17
};
static shared_auto_ptr<POSNode> Construct(string dNodeDesc,
vector<shared_auto_ptr<POSNode>> *allPOSNodes = NULL,
unsigned int dStartPosition = 0, unsigned int dEndPosition = 0,
unsigned int dBridgePosition = 0, string data = "");
static void ConstructSequence(string dSequence,
vector<shared_auto_ptr<POSNode>> *allPOSNodes);
POSNode();
POSNode(POSEntry dPOS,
string dSpelling = "",
unsigned int dStartPosition = 0,
unsigned int dEndPosition = 0,
unsigned int dBridgePosition = 0,
string data = "");
virtual ~POSNode();
string GetNodeDesc();
void SetParent(shared_auto_ptr<POSNode> dParent);
unsigned int GetStartPosition();
unsigned int GetEndPosition();
unsigned int GetBridgePosition();
virtual void ClearAnalyzed(bool includingSelf);
void SetBridgePosition(unsigned int dPosition);
POSEntry GetPOSEntry() { return m_POS; }
virtual int CompareSpellings(POSNode &dNode);
virtual int Compare(POSNode &dNode);
virtual string GetSpelling(int debugLevel = 0);
virtual string GetID();
virtual string GetData();
virtual void SetData(string data);
virtual shared_auto_ptr<POSNode> Navigate(
EDirection direction, POSNode *constraint = NULL);
virtual void ManageTransientParents(
Persistent<Context> context, bool recursive = false);
virtual void UpdateFromChildValues();
static bool CompareNodes(
shared_auto_ptr<POSNode> elem1,
shared_auto_ptr<POSNode> elem2);
virtual void SetSortRequirement(ESortType dRequirement);
virtual void SetConstructionLine(string dLine);
virtual string GetConstructionLine();
virtual vector<shared_auto_ptr<CPredicate>>
BuildPredicates(string wpstr = "");
virtual void AddInitializer(string dPredicateString) throw();
virtual void SetWordIndex(unsigned int dIndex) throw();
virtual unsigned int GetWordIndex() const throw();
virtual void UpdateNodesCount() throw();
virtual string Inspect(int indentCount) throw();
int ChildNodeCount();
virtual shared_auto_ptr<POSNode> GetChild(int index);
virtual shared_auto_ptr<POSNode> GetParent();
virtual void SetSpelling(string dSpelling);
virtual void SetStartPosition(unsigned int dPosition);
virtual void SetEndPosition(unsigned int dPosition);
virtual void UpdateDebugStrings();
virtual void SetTransientParent(
shared_auto_ptr<POSNode> dTransientParent);
virtual bool HasConceptualDefinition();
virtual void OutputTransformLineInfo();
protected:
virtual bool ValidatePredicates();
virtual void AddPredicate(
shared_auto_ptr<CPredicate> dPredicate,
bool bringUp);
virtual bool IsLeaf();
virtual void FlagPacketAnalyzed();
virtual bool Analyzed();
static int m_maxSpellingLength;
Persistent<Context> m_context;
POSEntry m_POS;
string m_spelling;
string m_constructionLine;
string m_data;
POSNode* m_transientParent;
vector<shared_auto_ptr<POSNode>> m_children;
unsigned int m_startPosition;
unsigned int m_endPosition;
unsigned int m_bridgePosition;
unsigned int m_wordIndex;
unsigned int m_totalNodesUnder;
ESortType m_sortRequirement;
vector<shared_auto_ptr<CPredicate>> m_initializers;
vector<shared_auto_ptr<CPredicate>> m_predicates;
int m_inCurInitializer;
bool m_analyzed;
bool m_hasConceptualDefinition;
EPredicateCalculusCycle m_curCycle;
string m_debugString;
};
#endif
Consequently, every word is a POSNode object; however, some sequences of words are composed of other POSNode objects. The POSNode::BuildPredicates method calculates all valid CPredicate objects for a given POSNode object. It is worth looking more closely at this method.
As highlighted in the yellow steps from the flowchart, POSNode::BuildPredicates has three different phases:
m_curCycle is eCalculatingPOSScript: if there is a JavaScript file of the part-of-speech name in the POS scripts directory, it executes, and the result is returned.
eNotCalculating is the default value for m_curCycle in a POSNode object that was never visited through POSNode::BuildPredicates, and it is set to eCalculatingPOSScript while entering. - During this phase of calculation, it is possible to re-instantiate
POSNode::BuildPredicates from JavaScript by referring to the property desc of curPredicate. This results in re-instantiating POSNode::BuildPredicates, with m_curCycle set to eCalculatingConstructionLineScript. - If there is no JavaScript file of the part-of-speech name in the POS scripts directory,
m_curCycle is set to eCalculatingConstructionLineScript and the algorithm continues.
m_curCycle is eCalculatingConstructionLineScript: if there is a JavaScript file of the construction line name in the Permutation scripts directory, it executes, and the result is returned.
- The construction line used is the name of the Syntax Transform line that created the
POSNode. - During this phase of calculation, it is possible to re-instantiate
POSNode::BuildPredicates from JavaScript by referring to the property desc of curPredicate. This results in re-instantiating POSNode::BuildPredicates, with m_curCycle set to eCalculatingWordScript. - If there is no JavaScript file of the construction line name in the Permutation scripts directory,
m_curCycle is set to eCalculatingWordScript, and the algorithm continues.
m_curCycle is eCalculatingWordScript: the JavaScript file corresponding to the POSNode spelling in the Conceptual Analysis directory executes in two phases:
- During the first phase,
curPredicate.initialized() is false, and the algorithm accumulates initializers through calls to curNode.addInitializer. That corresponds to a scanning for an Object of Knowledge. What is it about? At this point in time, it is not the action that is of interest, but the determination of which conceptual entity the action is about. Although the identification of the Object of Knowledge can appear to be easy in a sentence such as "The car is red", it becomes obvious that it is not such an easy task when thinking of a sentence like "The fact that I am happy is not a surprise to anyone". In this second sentence, it is an entire sentence; from a conceptual perspective, this is the Object of Knowledge: "The fact that I am happy". The Object of Knowledge is the skeleton of the predicate. It is first identified, then conceptualized. Only then are the action primitives and other role-filler pairs aggregated to that skeleton. - During the second phase, each predicate added through a call to
curNode.addInitializer in the first phase is set to the curPredicate, and each POSNode is re-invoked. At this point in time, the Object of Knowledge is identified and placed in curPredicate; it is the responsibility of each Predicate Builder Script to work together in order to build a valid predicate.
It is not allowed to re-invoke POSNode::BuildPredicates from JavaScript by referring to the property desc of curPredicate.
vector<shared_auto_ptr<CPredicate>> POSNode::BuildPredicates(string wpstr)
{
if (m_inCurInitializer != -1)
{
vector<shared_auto_ptr<CPredicate>> dReturn;
dReturn.push_back(m_initializers[m_inCurInitializer]);
return dReturn;
}
if (wpstr != "")
{
m_predicates.clear();
}
if ((m_predicates.size() > 0) && (m_curCycle == eNotCalculating))
{
return m_predicates;
}
EPredicateCalculusCycle keepCycle = m_curCycle;
if (m_curCycle == eCalculatingWordScript)
{
throw new exception("Infinite loop detected!");
}
else
{
m_curCycle = EPredicateCalculusCycle((int)m_curCycle + 1);
}
g_nodeContext.push(this);
try
{
bool executed = false;
if (m_curCycle == eCalculatingPOSScript)
{
shared_auto_ptr<CPredicate> wp1(new CPredicate());
wp1->Abort();
wp1 = CPredicate::ExecutePredicateBuilderScript(
m_context, m_POS.GetDescriptor(),
wp1, this, executed, m_curCycle);
if ((wp1.get() != NULL) && (!wp1->HasAbort()))
{
AddPredicate(wp1, (m_curCycle == eNotCalculating));
}
if (executed)
{
m_curCycle = eNotCalculating;
}
else
{
m_curCycle = eCalculatingConstructionLineScript;
}
}
executed = false;
if (m_curCycle == eCalculatingConstructionLineScript)
{
if (m_constructionLine != "")
{
shared_auto_ptr<CPredicate> wp1(new CPredicate());
wp1->Abort();
wp1 = CPredicate::ExecutePredicateBuilderScript(m_context,
m_constructionLine, wp1, this, executed, m_curCycle);
if ((wp1.get() != NULL) && (!wp1->HasAbort()))
{
AddPredicate(wp1, (m_curCycle == eNotCalculating));
}
if (executed)
{
m_curCycle = eNotCalculating;
}
else
{
m_curCycle = eCalculatingWordScript;
}
}
else
{
m_curCycle = eCalculatingWordScript;
}
}
if (m_curCycle == eCalculatingWordScript)
{
if (m_children.size() > 0)
{
int initializersCount = 0;
for (unsigned int pass = 1; pass <= 2; pass++)
{
if (wpstr != "")
{
pass = 2;
initializersCount = 1;
}
for (unsigned int i = 0; i < m_children.size(); i++)
{
if ((pass == 2) && (initializersCount == 0))
{
if ((DigitalConceptBuilder::
GetCurCalculationContext()->FailureReason()) ||
(DigitalConceptBuilder::
GetCurCalculationContext()->GetJavascriptTrace()))
{
printf("FAILURE REASON (potential): No initializer was " +
"found while calculating the node %s.\n",
m_spelling.c_str());
}
}
switch (pass)
{
case 1:
{
shared_auto_ptr<CPredicate>
dNewPredicate(new CPredicate());
bool executed = false;
CPredicate::ExecutePredicateBuilderScript(
m_context, m_children[i]->GetSpelling(),
dNewPredicate, m_children[i],
executed, m_curCycle);
if (!m_children[i]->IsLeaf())
{
vector<shared_auto_ptr<CPredicate>>
newInitializers =
m_children[i]->BuildPredicates();
for (unsigned int j = 0; j <
newInitializers.size(); j++)
{
if (newInitializers[j]->GetPrimitive() !=
CPredicate::UNSET)
{
m_children[i]->
m_initializers.push_back(
newInitializers[j]);
}
}
}
if ((m_children.size() == 1) &&
(m_children[0]->m_initializers.size() > 0))
{
for (unsigned int j = 0; j <
m_children[0]->m_initializers.size(); j++)
{
AddPredicate(m_children[0]->m_initializers[j],
(m_curCycle == eNotCalculating));
}
}
initializersCount +=
m_children[i]->m_initializers.size();
}
break;
case 2:
{
vector<shared_auto_ptr<CPredicate>>
initializers = m_children[i]->m_initializers;
if (wpstr != "")
{
if (i > 0)
{
break;
}
initializers.clear();
shared_auto_ptr<CPredicate> wp(new CPredicate());
wp->SetPredicateString(wpstr);
initializers.push_back(wp);
}
shared_auto_ptr<CPredicate> wp(new CPredicate());
wp->ClearAbort();
for (unsigned int k = 0; ((k < initializers.size()) &&
(wp.get() != NULL) && (!wp->HasAbort())); k++)
{
string wpOnEntrance;
if (wp->GetPrimitive() != CPredicate::UNSET)
{
wpOnEntrance = wp->ToString(false);
}
wp->SetPredicateString(
m_children[i]->m_initializers[k]->ToString(false));
if (wpstr != "")
{
m_children[i]->m_inCurInitializer = -1;
}
else
{
m_children[i]->m_inCurInitializer = k;
}
wp->ClearAbort();
for (unsigned int j = 0; ((j < m_children.size()) &&
(wp.get() != NULL) && (!wp->HasAbort())); j++)
{
if ((i != j) || (wpstr != ""))
{
if ((!m_children[j]->Analyzed()) ||
(wpstr != ""))
{
string keepDesc = wp->ToString(false);
wp->Abort();
bool executed = false;
shared_auto_ptr<CPredicate> res =
CPredicate::ExecutePredicateBuilderScript(
m_context, m_children[j]->GetSpelling(),
wp, m_children[j], executed, m_curCycle);
if ((res.get() == NULL) || (res->HasAbort()))
{
if ((DigitalConceptBuilder::
GetCurCalculationContext()->
FailureReason())
|| (DigitalConceptBuilder::
GetCurCalculationContext()->
GetJavascriptTrace()))
{
printf("FAILURE REASON (potential): " +
"The node '%s' aborted (or did not " +
"populate curPredicate) when called " +
"with predicate %s.\n",
m_children[j]->GetSpelling().c_str(),
keepDesc.c_str());
}
break;
}
wp = res;
}
}
}
m_children[i]->m_inCurInitializer = -1;
if ((wp.get() != NULL) &&
(!wp->HasAbort()) && (wpOnEntrance != ""))
{
try
{
string dSource =
CPredicate::LoadFunctions("Hooks");
if (dSource != "")
{
dSource += "\r\n\r\n";
dSource += "entityJunction(\"" +
wp->ToString(false) + "\",\"" +
wpOnEntrance + "\")";
HandleScope handle_scope;
StackBasedContext localcontext;
Context::Scope context_scope(
*localcontext.getV8Object());
Handle<Value> dReturnVal =
ExecuteJavascriptString(
*localcontext.getV8Object(),
dSource, "POSNode::Hooks");
String::AsciiValue
dReturnStr(dReturnVal);
wp->SetPredicateString(*dReturnStr);
}
else
{
throw(exception("No hooks found"));
}
}
catch (exception e)
{
wp->SetPredicateString("AND[VALUE1:" +
wp->ToString(false) + "/VALUE2:" +
wpOnEntrance + "]");
}
}
}
if ((wp.get() != NULL) && (!wp->HasAbort()) &&
(wp->GetPrimitive() != CPredicate::UNSET))
{
AddPredicate(wp, (m_curCycle == eNotCalculating));
}
}
break;
}
}
}
}
else
{
shared_auto_ptr<CPredicate> dNewPredicate(new CPredicate());
bool executed = false;
shared_auto_ptr<CPredicate> res =
CPredicate::ExecutePredicateBuilderScript(m_context,
GetSpelling(), dNewPredicate, this, executed, m_curCycle);
if (!((res.get() == NULL) || (res->HasAbort())))
{
AddPredicate(res, (m_curCycle == eNotCalculating));
}
}
m_curCycle = eNotCalculating;
}
}
catch (exception e)
{
m_predicates.clear();
if ((DigitalConceptBuilder::GetCurCalculationContext()->FailureReason()) ||
(DigitalConceptBuilder::GetCurCalculationContext()->GetJavascriptTrace()))
{
printf("FAILURE REASON: Exception: %s.\n", e.what());
}
}
g_nodeContext.pop();
m_curCycle = keepCycle;
if ((m_predicates.size() > 0) && (m_curCycle == eNotCalculating))
{
m_analyzed = true;
}
if ((m_predicates.size() > 0) && (m_curCycle != eNotCalculating))
{
vector<shared_auto_ptr<CPredicate>> dReturn = m_predicates;
m_predicates.clear();
return dReturn;
}
return m_predicates;
}
Between C++ and JavaScript
Although the purpose of this article is not to elaborate on Google V8, and other sources of documentation are available on the subject, here is a brief overview of the JavaScript integration for this project.
The steps from the previous flowchart shown in green are the ones that can bridge to JavaScript. In order to keep the algorithm as scalable as possible in regard to the construction of predicates, and to avoid requiring C++ knowledge to populate a Conceptual Dictionary, JavaScript is the selected language. Google V8 is the JavaScript engine used to expose two classes: POSNode and CPredicate.
Each class that needs to bridge to JavaScript inherits from the JSObjectSupport template. Such an approach implements generic JavaScript services in a way that is independent of the class itself.
template <class T> class JSObjectSupport
{
public:
JSObjectSupport();
Handle<Object> CreateJavascriptInstance();
void SetToJavascriptVariable(Handle<Context> context,
string variableName);
static T* GetJavascriptVariable(
Persistent<Context> context,
string variableName);
static void JavascriptSetup();
protected:
static bool m_setUpDone;
static Handle<FunctionTemplate> m_node_templ;
static Handle<ObjectTemplate> m_node_proto;
static Handle<ObjectTemplate> m_node_inst;
};
A template specialization for JavascriptSetup() is used to set-up the JavaScript services needed. Here are their implementations for POSNode, then CPredicate:
template <> void JSObjectSupport<POSNode>::JavascriptSetup()
{
m_setUpDone = true;
m_node_templ = FunctionTemplate::New();
m_node_templ->SetClassName(String::New("POSNode"));
m_node_proto = m_node_templ->PrototypeTemplate();
m_node_proto->Set("navigate", FunctionTemplate::New(JSNavigate));
m_node_proto->Set("debug", FunctionTemplate::New(JSBreak));
m_node_proto->Set("addInitializer",
FunctionTemplate::New(JSAddInitializer));
m_node_proto->Set("toPredicate",
FunctionTemplate::New(JSToPredicate));
m_node_proto->Set("trace", FunctionTemplate::New(JSNodeTracing));
m_node_inst = m_node_templ->InstanceTemplate();
m_node_inst->SetInternalFieldCount(1);
m_node_inst->SetAccessor(String::New("constructionLine"),
JSGetConstructionLine, NULL);
m_node_inst->SetAccessor(String::New("spelling"), JSGetSpelling, NULL);
m_node_inst->SetAccessor(String::New("data"), JSGetData, NULL);
m_node_inst->SetAccessor(String::New("posType"), JSGetPOSType, NULL);
m_node_inst->SetAccessor(String::New("wordIndex"), JSGetWordIndex, NULL);
m_node_inst->SetAccessor(String::New("parent"), JSGetParent, NULL);
m_node_inst->SetAccessor(String::New("eSibling"),
JSPOSNodeEnum_eSibling, NULL);
m_node_inst->SetAccessor(String::New("eSiblingLeft"),
JSPOSNodeEnum_eSiblingLeft, NULL);
m_node_inst->SetAccessor(String::New("eSiblingRight"),
JSPOSNodeEnum_eSiblingRight, NULL);
m_node_inst->SetAccessor(String::New("eFirstSibling"),
JSPOSNodeEnum_eFirstSibling, NULL);
m_node_inst->SetAccessor(String::New("eLastSibling"),
JSPOSNodeEnum_eLastSibling, NULL);
m_node_inst->SetAccessor(String::New("eNextSibling"),
JSPOSNodeEnum_eNextSibling, NULL);
m_node_inst->SetAccessor(String::New("ePreviousSibling"),
JSPOSNodeEnum_ePreviousSibling, NULL);
m_node_inst->SetAccessor(String::New("eAncestre"),
JSPOSNodeEnum_eAncestre, NULL);
m_node_inst->SetAccessor(String::New("eParent"),
JSPOSNodeEnum_eParent, NULL);
m_node_inst->SetAccessor(String::New("eTopParent"),
JSPOSNodeEnum_eTopParent, NULL);
m_node_inst->SetAccessor(String::New("eChild"),
JSPOSNodeEnum_eChild, NULL);
m_node_inst->SetAccessor(String::New("eFirstChild"),
JSPOSNodeEnum_eFirstChild, NULL);
m_node_inst->SetAccessor(String::New("eLastChild"),
JSPOSNodeEnum_eLastChild, NULL);
m_node_inst->SetAccessor(String::New("eDescendant"),
JSPOSNodeEnum_eDescendant, NULL);
m_node_inst->SetAccessor(String::New("ePreviousWord"),
JSPOSNodeEnum_ePreviousWord, NULL);
m_node_inst->SetAccessor(String::New("eNextWord"),
JSPOSNodeEnum_eNextWord, NULL);
m_node_inst->SetAccessor(String::New("eFirstWord"),
JSPOSNodeEnum_eFirstWord, NULL);
m_node_inst->SetAccessor(String::New("eLastWord"),
JSPOSNodeEnum_eLastWord, NULL);
}
template <> void JSObjectSupport<CPredicate>::JavascriptSetup()
{
m_setUpDone = true;
m_node_templ = FunctionTemplate::New();
m_node_templ->SetClassName(String::New("Predicate"));
m_node_proto = m_node_templ->PrototypeTemplate();
m_node_proto->Set("setRoleFillerPair",
FunctionTemplate::New(JSSetRoleFillerPair));
m_node_proto->Set("replaceAll", FunctionTemplate::New(JSReplaceAll));
m_node_proto->Set("initialized", FunctionTemplate::New(JSIsInitialized));
m_node_proto->Set("setPredicate", FunctionTemplate::New(JSSetPredicate));
m_node_proto->Set("is", FunctionTemplate::New(JSIsA));
m_node_proto->Set("has", FunctionTemplate::New(JSHas));
m_node_proto->Set("search", FunctionTemplate::New(JSSearch));
m_node_proto->Set("abort", FunctionTemplate::New(JSAbort));
m_node_proto->Set("trace", FunctionTemplate::New(JSPredicateTracing));
m_node_proto->Set("getRole", FunctionTemplate::New(JSGetRole));
m_node_proto->Set("getFiller", FunctionTemplate::New(JSGetFiller));
m_node_proto->Set("getVariable", FunctionTemplate::New(JSGetVariable));
m_node_proto->Set("setVariable", FunctionTemplate::New(JSSetVariable));
m_node_proto->Set("setRoleOperation",
FunctionTemplate::New(JSSetRoleOperation));
m_node_inst = m_node_templ->InstanceTemplate();
m_node_inst->SetInternalFieldCount(1);
m_node_inst->SetAccessor(String::New("desc"), JSGetDesc, NULL);
m_node_inst->SetAccessor(String::New("primitive"),
JSGetPrimitive, JSSetPrimitive);
m_node_inst->SetAccessor(String::New("output"), JSGetOutput, NULL);
}
Some generic entry-points to C++ that are not associated with any object are also implemented in JSObjectSupport::InitJavascriptGlobal.
void InitJavascriptGlobal()
{
if (global.IsEmpty())
{
global = v8::ObjectTemplate::New();
global->Set(String::New("alert"), FunctionTemplate::New(JSAlert));
global->Set(String::New("print"), FunctionTemplate::New(JSPrint));
global->Set(String::New("new_predicate"),
FunctionTemplate::New(JSNewPredicate));
global->Set(String::New("setResultPredicate"),
FunctionTemplate::New(JSSetResultPredicate));
global->Set(String::New("getResultPredicate"),
FunctionTemplate::New(JSGetResultPredicate));
}
}
The Conceptual Dictionary
How is the passage from syntax to concept done? This is the responsibility of the Conceptual Dictionary holding all three levels of scripts that can be invoked and that all work together in order to build valid predicates. Let us look at some examples of Predicate Builder Scripts first.
Conceptual Definition of "is":
switch (curNode.posType)
{
case "VERB":
case "AUX":
{
if (curPredicate.initialized())
{
dNextNode = curNode.navigate(curNode.eNextSibling);
if (dNextNode != 0)
{
dOtherNode = dNextNode.navigate(curNode.eNextSibling);
if (dOtherNode != 0)
{
if ((dNextNode.toPredicate() != 0) &&
(dOtherNode.toPredicate() != 0))
{
curPredicate.setPredicate("DO[OPERATION:IS/VALUE1:" +
dNextNode.toPredicate().desc + "/VALUE2:" +
dOtherNode.toPredicate().desc+"]");
break;
}
}
}
if (curNode.posType == "VERB")
{
curPredicate.setPredicate(
"DO[OPERATION:UNION/VALUE:" + curPredicate.desc+"]");
}
}
}
break;
}
For the Conceptual Definition of the word "is", we observe that nothing is done unless curPredicate.initialized() returns true. This means that "is" cannot result in an Object of Knowledge. For the purpose of calculating the test-cases provided with this article, there are two syntactic variations that are defined: "X is Y" and "Is Y X". Obviously, the English language has more diversity for the word "is" than what resides in that script, and the current Conceptual Definition is limited in what it can achieve, but it is possible to observe the available scalability throughout this medium.
Conceptual Definition of "car":
switch (curNode.posType)
{
case "NOUN":
if (!curPredicate.initialized())
{
curNode.addInitializer(
"PP[TYPE:VEHICLE/CLASS:CAR/WHEELCOUNT:4/QUANTITY:1]");
}
else if (curPredicate.primitive == "PP")
{
curPredicate.setPredicate("DO[OPERATION:UNION/OBJECT:" +
curPredicate.desc +
"/VALUE:PP[TYPE:VEHICLE/CLASS:CAR/WHEELCOUNT:4/QUANTITY:1]]");
}
else
{
curPredicate.abort();
}
break;
}
In the Conceptual Definition of "car", we can see that "car" can result as an Object of Knowledge. But the word "car" can also complete an already existent Object of Knowledge if it has the same primitive (PP), in which case, it unifies both predicates under the same one (for example, "a red car" - a PP that is red and a car).
Through these simple Conceptual Definitions, it is possible to transform simple syntactic structures into concepts. The navigate method, residing in the Predicate Builder Script of the word "is", for example, is critical to a successful implementation. It allows the navigation between POSNodes in all directions (siblings, children, parents). To conceptually define a word has a lot to do with navigating between nodes and capturing part of the representation from different sources. This is compatible with the cognitive process used to rebuild a concept from syntax. That is, words are not concepts themselves, but they are key elements needed to build a concept that comes to be only when put in a relationship with other words.
As shown in CPredicate::PerformConceptualAnalysis, the same process is repeated for all syntactic permutations of the targeted part-of-speech that are generated from Syntactic Analysis, or until a predicate calculated is no longer ambiguous. More on that in the next section...
shared_auto_ptr<CPredicate> CPredicate::PerformConceptualAnalysis(
Persistent<Context> context, shared_auto_ptr<POSList> dList)
{
bool continueProcessing = true;
shared_auto_ptr<CPredicate> dEmpty;
DigitalConceptBuilder::
GetCurCalculationContext()->SetResultPredicate(dEmpty);
shared_auto_ptr<CPredicate> dReturn;
vector<shared_auto_ptr<POSNode>> dSentences =
dList->AccumulateAll(POSNode::Construct(FormattedString("[%s]",
DigitalConceptBuilder::
GetCurCalculationContext()->GetTargetPOS().GetDescriptor().c_str())),
POSNode::eSortLargestToSmallestNode);
for (unsigned int i = 0; ((i < dSentences.size()) &&
((int)i < DigitalConceptBuilder::
GetCurCalculationContext()->GetMaxConceptualAnalysis())); i++)
{
CPredicate::m_permutationCount = (i + 1);
ExecuteJavascriptString(context,
FormattedString("curSequence = '%s:%d';",
DigitalConceptBuilder::
GetCurCalculationContext()->GetId().c_str(), (i+1)),
"DigitalConceptBuilder::PerformConceptualAnalysis");
JSTrace::globTrace.SetSyntacticContext(
dSentences[i]->GetSpelling(2));
if ((DigitalConceptBuilder::
GetCurCalculationContext()->OutputSyntaxPermutations()) ||
(DigitalConceptBuilder::
GetCurCalculationContext()->GetTransformLine()))
{
if (i == 0)
{
printf("\n");
}
printf("%s:%d. %s\n",
DigitalConceptBuilder::
GetCurCalculationContext()->GetId().c_str(),
i+1, dSentences[i]->GetSpelling(2).c_str());
if (DigitalConceptBuilder::
GetCurCalculationContext()->GetTransformLine())
{
printf("\n");
dSentences[i]->OutputTransformLineInfo();
printf("\n");
}
}
string dId = FormattedString("%s:%d",
DigitalConceptBuilder::
GetCurCalculationContext()->GetId().c_str(), i+1);
dSentences[i]->UpdateNodesCount();
dSentences[i]->ManageTransientParents(context);
vector<shared_auto_ptr<CPredicate>> result =
dSentences[i]->BuildPredicates();
bool hadPredicates = (result.size() > 0);
if (DigitalConceptBuilder::
GetCurCalculationContext()->OutputPredicates())
{
for (unsigned int j = 0; j < result.size(); j++)
{
printf("\n");
printf(result[j]->ToString(true).c_str());
printf("\n");
if (j == (result.size() - 1))
{
printf("\n");
}
}
}
for (unsigned int k = 0;
k < DigitalConceptBuilder::
GetCurCalculationContext()->GetPostProcessing().size(); k++)
{
vector<shared_auto_ptr<CPredicate>> postResult;
for (unsigned int j = 0; j < result.size(); j++)
{
bool executed = false;
result[j]->ClearAbort();
shared_auto_ptr<CPredicate> dNewPredicate =
result[j]->ExecutePredicateBuilderScript(context,
DigitalConceptBuilder::
GetCurCalculationContext()->GetPostProcessing()[k],
result[j],
dSentences[i],
executed,
eCalculatingPostProcessing);
if ((executed) && (dNewPredicate.get() != NULL) &&
(!dNewPredicate->HasAbort()))
{
result[j] = dNewPredicate;
postResult.push_back(dNewPredicate);
}
}
result = postResult;
}
if (DigitalConceptBuilder::
GetCurCalculationContext()->OutputPredicates())
{
if (result.size() > 0)
{
printf("%d valid predicate%s following post-processing:\n",
result.size(), (result.size() > 1)?"s":"");
for (unsigned int j = 0; j < result.size(); j++)
{
printf("\n");
printf(result[j]->ToString(true).c_str());
printf("\n");
if (j == (result.size() - 1))
{
printf("\n");
}
}
}
else if (hadPredicates)
{
printf("Post-processing rejected all predicates.\n\n");
}
}
for (unsigned int j = 0; ((j < result.size()) &&
(continueProcessing)); j++)
{
CPredicate::Disambiguate(context, dReturn,
result[j], continueProcessing);
}
if ((!continueProcessing) ||
((DigitalConceptBuilder::
GetCurCalculationContext()->GetMaxSyntaxPermutations() != -1) &&
(CPredicate::m_permutationCount >=
DigitalConceptBuilder::
GetCurCalculationContext()->GetMaxSyntaxPermutations())))
{
break;
}
}
if (DigitalConceptBuilder::GetCurCalculationContext()->GetFeedback() != "")
{
shared_auto_ptr<CPredicate> workingPredicate;
shared_auto_ptr<POSNode> curNode;
bool executed = false;
CPredicate::ExecutePredicateBuilderScript(context,
DigitalConceptBuilder::GetCurCalculationContext()->GetFeedback(),
workingPredicate, curNode, executed, eFeedback);
}
m_fileCache.Clear();
return dReturn;
}
Disambiguation
The main reason why a CLUE is iterative is because of the inherent ambiguity in languages. Conceptually, a sequence of words can represent different concepts. Most of the language processing relates to disambiguation; which part of the processing performs disambiguation determines the accuracy of the said processing. In a CLUE, the postulate is that such disambiguation must ultimately be performed at the conceptual level on concepts that have been determined to be valid and which are competing with each other.
Take the simple test-cases we have as an example. Most of them are questions. When asking a question that can result in an answer of 'yes', 'no', or 'maybe', a human typically responds with the highest possible value (yes > maybe > no). This is why there is a natural tendency to answer interrogations with "yes, but only if that condition is met". The answer is the highest possible outcome, and then the conditions to meet that outcome follow. The disambiguation process evaluates the responses, and as soon as it meets the highest possible response - a 'yes' - it stops evaluating and produces the feedback. If the disambiguation process is unable to produce a 'yes' concept, it chooses the highest one it encountered during its processing.
That logic is performed in JavaScript in the Conceptual Analysis/Disambiguation/Interrogation.js file. Nothing prevents the process from having a diversified disambiguation that is not limited to interrogations. For example, the purity of concepts is also a major factor. That is, how much adaptation of the other acquired concepts is needed in order to accept the new concept? If someone states something like, "I am really an alien coming from under water", the first reflex might be that such a person is crazy to be thinking about the little green men and an underwater Atlantis. That requires too many adaptations of the already existing conceptual web in order just to assimilate this new concept, so the assimilation of the concept "this person is crazy" ends-up being a good compromise as a result of the interaction. But then, if the same person continues stating "What I mean is that I am really an illegal alien that has crossed the border under water", all is good. The acceptance of this new concept does not require further adaptation of existing concepts. The second concept is more pure than the first one. The same can be said about a question to an airline response system like: "what is the status of flight six hundred and thirty four?" If there is no flight 634 but there are flights 600 and 34, the question is most probably about these two flights. The receiver of an inquiry, automated or not, assumes an inquiry is about something that makes sense, and this is part of the disambiguation process.
if (curPredicate.is("DO[ACTION:RECEIVEINPUT/MOOD:INTEROGATIVE/" +
"OBJECT:DO[OPERATION:IS/VALUE1:{VALUE1}/VALUE2:{VALUE2}]]") == "YES")
{
var dNewPredicate = new_predicate();
dNewPredicate.setPredicate(curPredicate.getVariable("VALUE1"));
if (dNewPredicate.initialized())
{
var thisResult = dNewPredicate.is(curPredicate.getVariable("VALUE2"));
curPredicate.setVariable("ISTESTRESULT", thisResult);
if (thisResult == "YES")
{
curPredicate.abort();
setResultPredicate(curPredicate);
}
else if (getResultPredicate() != 0)
{
if ((getResultPredicate().getVariable("ISTESTRESULT") == "NO")
&& (thisResult == "MAYBE"))
{
setResultPredicate(curPredicate);
}
}
else
{
setResultPredicate(curPredicate);
}
}
else
{
curPredicate.abort();
}
}
else if (getResultPredicate() == 0)
{
setResultPredicate(curPredicate);
}
Feedback
At last, the fact that an inquiry was recognized does not imply that it is possible to formulate a response for that inquiry. For example, the inquiry: "what is the meaning of life", can easily be recognized, but that does not mean we can formulate an acceptable response. It is the responsibility of the feedback JavaScript to transform the unambiguous recognized concept into a response. The response does not necessarily have to be a DOS output as we have right now, but it can also be a database insert, a text-to-speech sound being reproduced, or something else. Or, it can even be a combination of all of the above. Because we are dealing with concepts, we do not have to limit ourselves to only one type of response. A statement such as: "call me at 555-1212, 30 minutes before flight 634 arrives", can result in a database insert representing the call to make at the given relative time.
var reproduced = false;
var dPredicate = getResultPredicate();
if (dPredicate != 0)
{
if (dPredicate.getVariable("ISTESTRESULT") != 0)
{
print("\n" + dPredicate.getVariable("ISTESTRESULT") + ":\n\n");
print(dPredicate.output);
print("\n");
reproduced = true;
}
}
if (!reproduced)
{
print("\nNo inquiry to analyze here:\n\n");
print(dPredicate.output);
print("\n");
}
Points of Interest
This approach brings natural language understanding to a new level. It allows for natural language understanding to happen in a way in which concepts are reconstructed with respect to the original input. Furthermore, it allows for conceptual manipulations to happen as a result of a flexible natural language input.
Should our generation have enough vision to push the technological revolution up another notch, we could build a computer system that truly emulates our thinking. It is my strong belief that we need to send our computers to grammar and philosophy classes before we are to be rewarded with the second phase of the technological revolution.
Currently, the main difficulty which limits this approach is the need for the production of a sufficiently complete Conceptual Dictionary. This is to be expected, when considering the person-years that went into the making of a conventional dictionary. However, even a limited domain-specific dictionary (e.g., a flight response system) that is as little as 1000 words would require little effort to produce.
But then, let us imagine the following for a moment. A reasonable subset of the English language needed in order to become relatively fluent is at about 50,000 words. Should a group of 10 linguists produce a total of 10 words per day for 200 days per year, that would require them two years and a half to have 50,000 words conceptually defined.
In my next article, I intend to build a limited-domain vocabulary in order to show real-world implementations of a CLUE. Such vocabulary should conceptually define up to 1000 words and offer interaction examples for the purpose of extracting meeting related information from e-mails. The following article after that one, to complete the sequence, will present similar content, but this time using speech (audio) as input. For that to happen, I intend to use SPHINX or ISIP as a speech engine and then hook the resulting lattice from an N-Best HMM algorithm into a Conceptual Speech Recognition processor to produce the type of results that we have seen in this article. This has already been done before, but for the purpose of delivering a self-contained article comparable to this one, some rework is required. To that effect, the article that uses speech as input will require significant energy to produce since it involves hooking into a speech recognition engine. Accordingly, if someone from the community who has experience with Sphinx or ISIP's speech engine wants to co-author the article with me, send a message for consideration.
Additional Licensing Notes
Feel free to use this technique and code in your work; however, be aware that a limited license is in use; such license excludes commercial and commercial not-for-profit deployments without prior authorization by the author. See license.txt or license.pdf in the included attachment for the entire license agreement.
History
- January 7th, 2010: First draft of this article written.

