The Constant Velocity IDE
Introduction<o:p>
What exactly are we trying to do here? <o:p>
We're
trying to project forward to the Stradivarius of coding. Such an instrument
would elevate the game of excellent developers to the highest levels ever.
That's what a Strad would do.<o:p>
Necessarily
such a device makes various assumptions about its players. The assumptions here
are that object-oriented software construction is important. That exercising
new types with tests is the preference if the burden of doing so is not too
great. That systems grow in complexity. That developers want to see the frail aspects
of a solution in order to remodel them. And finally that the execution states
of an application, if stored as a persistent, searchable structure, give rich
opportunity for new ways of debugging, optimizing and enhancing the overall
quality of an implementation.<o:p>
Here's an overview shot.
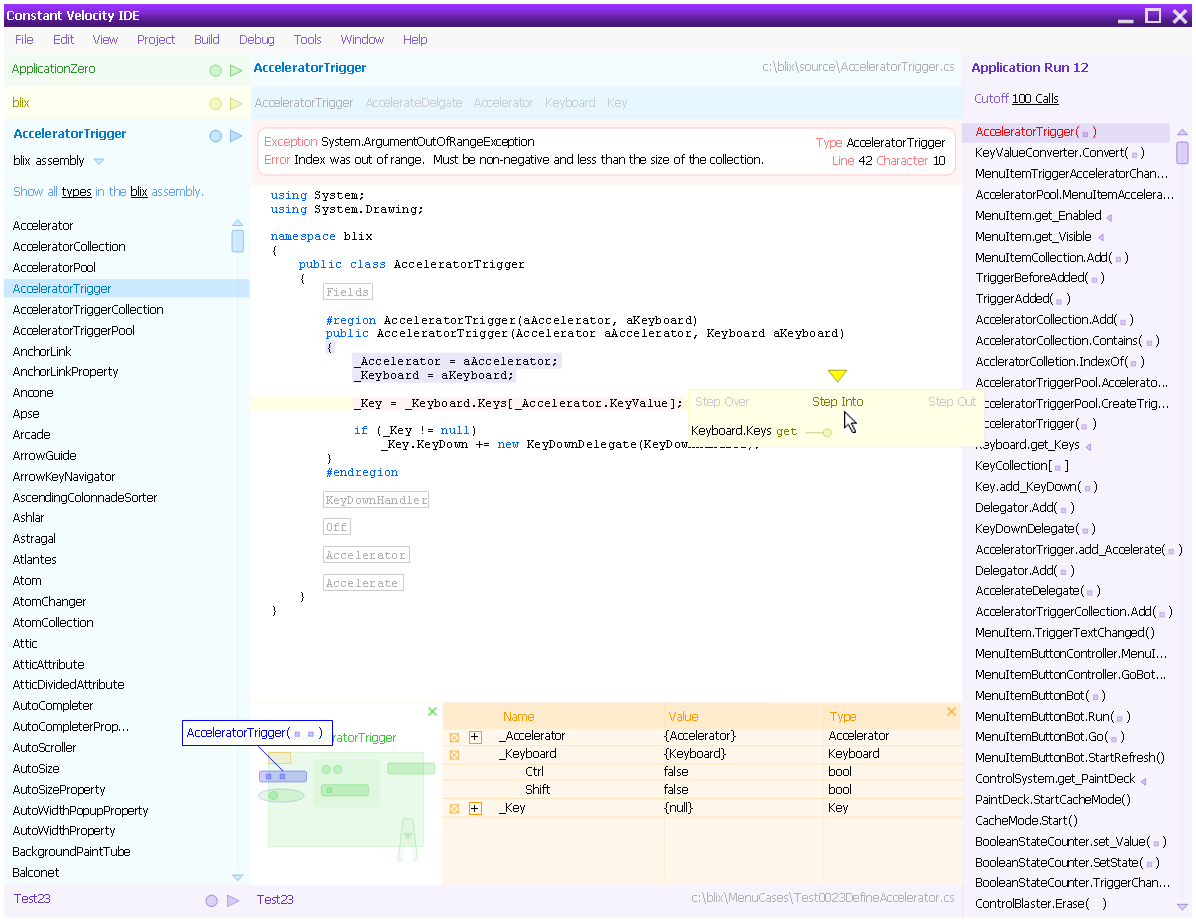
Inspect a cumulative stack based on a given application or test run in order to fix, optimize or refine the implementation.

Cumulative Stack
Imagine every method call made during the run of an application or test; place these calls in sequential order and you have the cumulative stack. We can explore this structure by selecting an individual method call, selecting a line in the method and then proceeding as usual, stepping through each line of source.
The difference is that we can find out how any object reached its state, or why a particular line executed by traversing the history of the run.
Cutoff
If an exception has occurred, we may need to see only the last few calls. Cutoff limits the number of calls available for searching. Essentially it’s an optimization.
Parameter Kibbles
Within the parentheses of method calls, a small icon (called a kibble) represents the value of all parameters. You can hover over this icon to get a mini-watch window with the parameters listed (which you can then check to add it to the main watch window).
Return Value Kibbles
These work the same as Parameter Kibbles, but for return values.
Jumpers
A cumulative stack may have millions of calls in it. Tracing the cause of an exception back from the line where the exception occurred might be quite simple in some cases. Running wire can certainly help isolate the exact point when some value changed which eventually led to an error condition.
The stack has a tendency to “drill-down” into composites or related objects, then snap-back to more basic application loops. This action is far more apparent in the cumulative stack, because it contains every drill-down and snap-back, every transient stack that existed during the run.
Jumpers allow us to better see what the transient stack looked like at a given moment in time, establishing a root and leaf for a single method call. This makes it easier to see the iterations of a loop (for example), so that we could inspect the second iteration without having to wade through all the noise generated by the first iteration.
Move efficiently through the cumulative stack avoiding unnecessary step intos.
Get Steps
A “step into” for a property getter.
The biggest problem here is deep dot notation:
Form.Controls[0].Control.TextModel.Reset();
When debugging, this line creates a “step-into” nightmare. By breaking out all of those getters and listing them as options, we provide a direct shot into “Reset()”, likely the desired target anyway, without cutting off the getter targets.
Mini Diagram-style shapes appear next to each Get Step, showing whether the property is an object or primitive type. If the getter contains code beyond a simple field value return, a line is drawn on the left side of the shape.
Speed resolution by putting compilation and exception messages in context.
Compilation Errors
The Constant Velocity (CV) engine compiles the solution whenever sufficient idle time exists to merit an attempt, and IntelliSense has indicated that the source should compile successfully. If this is not the case, or if the developer has forced a compile, the Error Trap will display all of the compilation errors. Each error can be clicked and the line of source is displayed (just like the current Output pane.)
Exceptions
When an application or test is run, any exception thrown is displayed, with the errant line highlighted. The cumulative stack is still available in this instance, and can be used to track down the cause of the exception.
This is a big productivity breakthrough—the transient stack is often thrown away during the first occurance of an unexpected exception (so that a proper breakpoint can be set) and sometimes that stack still doesn’t show the problem which may have occurred even earlier than the breakpoint.
Visually depict the implementation of a type.
Minis are used in the Visual Stack and in Visual Refactoring.
A rectangle represents the object or type. Other shapes are then added:
Properties
Properties are built to express read/write capability and to indicate the presence of code beyond a simple setter or getter line.
Read shapes are placed on the left, write shapes on the right. If additional code is present, a line is drawn from the edge of the value shape to the edge of the oval.
Scope
The scope of a member is shown by its position in the rectangle. Public members hang over the outside edge. Internal members appear in the private or protected region inside the rectangle.
Usage
Hovering over a shape causes the shape to “go hot” and a label naming the member and listing any parameters is shown.
Members are usually checked via a hover, dragged to a watch window or selected (if refactoring.)
In the Visual Stack, a blue highlight effect arcs through the Minis, indicating the method call order.
Technical Note
Minis were designed to be generated by software, and as such, adhere to standards (for example the use of ellipsis beyond a certain count of parameters or members) to assist in that application.
Represent the stack as a series of connected Mini Diagrams to show object complexity and to give instant access to object state.
Click the orange square to see the solid-state watch window for the object type. Define new watches by dragging shapes from the Mini Diagram to the Watch window.
Create new types with a single click, choose from the most recently selected types, search for types based on name, referenced types, interfaces implemented, ancestor type and other metadata.
Search Sentences
Search sentences make it possible to filter all of the types into a reasonable subset.
Key here is to provide a full set of good default sentences so that the developer can use the drop-down. Where the defaults do not suffice, advanced sentences can be built and saved.
Search Sentence Spec
Show
everything/classes/delegates/structs/interfaces/enums
in the solution/project/namespace/folder
that start with/contain/end with
that descend from the type
that implement the interface
that contain the attribute/method/property/event
Building sentences from this spec we have:
AutoSearch
Of course typing in the list jumps the selection to the first type that matches. For small projects then, search sentences will probably be left on “Show all types in the project.”
New Type Icon
The same as “Add New Item | Class” without the dialog. The “New Type” template should be editable by the developer.
MRU Icon
Displays a popup of the most recently selected types for this solution.
Make it easy to see and navigate to types referenced directly by the current type.
When a type is selected, this header area above the code editor displays a list of types. Click one of these to see the source for the type. Double-click one of these to update the type selected in the Finder and force the repopulation of the strip.
The intent here is to speed the navigation to related types, without requiring the developer to find a reference in the source. The strip also provides a reality check on referenced types, higher counts being less desirable.
Create new tests with a single click, choose from the most recently selected tests, find existing tests based on name, footprint, types referenced and other metadata.
Test Reffer
Automatically list the tests associated with a given line or lines of source - on demand or as those lines are edited.
The Test Reffer is implemented inside the Test Bench, such that the list simply updates when source is edited. As more and more source is changed, one would normally expect the list to grow. The tests, which usually have a green status, go yellow when any underlying source is changed. When the changes can be compiled, the CV engine then compiles the test, runs the test, and sets the status.
New Test Icon
Click this icon to create a new test. A solution always has a default test project defined. The code file for the test is added to this project automatically. The test is also given a sequential number. A description of the test can be entered in the list or in the description area at the top of the Test Bench.
MRU Icon
Click this icon to display a list of the most recently selected tests.
Search Sentence Filtering
Search sentences are English-like phrases with replaceable words. These can be concatenated together to form an entire search paragraph. Once a search is built, it is saved and can be named. Search sentences are saved per project, and can be selected via a drop-down.
The intent here is to allow quick and easy searching via predefined and even custom metadata (such as attributes.)
Test Status
Statuses are:
Unit Testing
The first type of test supported would be unit tests. Of course the underlying framework should be easily integrated into by the currently popular testing frameworks such as NUnit.
Application Tests
Simple unit tests are not sufficient for full-fledged QA—Application (Functional) Tests should be accommodated. Extensible architecture is important here as well, as the various extant testing applications would want to integrate.
Most importantly, full support for an Application Recorder/Playback style implementation should be provided.
Two-Way Recordings
In the highest quality implementation of this feature, recordings would be represented as the source of a managed type, making the recording directly editable.
Footprints
This is special kind of metadata associated with a test. A footprint is a list of every line of source that executed during the test run. The Search Sentence control in the TestBench provides an option to find all tests with identical footprints. Redundant tests can then be easily removed.
Graphically summarize code metrics directly in the source itself.
Grooves are accessible via a popup menu in the code editor. Select Grooves | Show All to display all of them, or pick an individual groove.
When the mouse hovers over a groove, it expands, making it easier to move over the graph for a specific line of source.
Right-clicking over the graph causes the value of the underlying statistic to be displayed, or in some cases, a full-blown listview is displayed.
Predefined grooves include:
Tests - Number of tests associated with this line of source. This list can then be transferred to the Test Bench.
Run - Number of times the line has been run (from within the current solution.)
Blown - Number of times an exception has been thrown directly from this line (not lower level source.)
Age - How long the source has been around. Should be maintained even through clipboard actions.
Edits - Number of times this line has been changed.
Calls (methods only) - Number of places in the current solution where this method is called. List of callers provided.
Creates (types only) - Number of places in the current solution where this type is instantiated. List provided.
The Graph
Groove statistics are summarized based on a set of predefined rules. These rules can be modified by the developer. The intent is to show the desirability of the statistic at a glance.
Architecture
Of course grooves should be implemented in a way that allows them to be extended and new grooves defined based on existing metadata or new combinations of metadata.
The groove painting architecture should also be pluggable, so that these graphs can be easily superseded.
Determine the exact points in the source where one type references another.
References are summarized in two different ways, either through a highlighted Mini Diagram (where the parts containing a reference are highlighted) or through a list of the line numbers. You can click either of these to jump to a reference.
Dependency Nest
Where a reference flows through to additional types, the list of those types is provided. Thus you can see the depth of the dependency.
Source Bullet
The source itself is bulleted at each reference.
Wires help us track down changes to the individual field, property, or event of a single object, answering the question: When did this value change?
Running Wire
You can run wire by right-clicking a line of source which references the field, property or event in question. All changes up to this line of code will be gathered into a list. You can then select from this list to display the method where the change occurred. The line or lines of source where values changed are highlighted.
Stack Colorization
Methods involved in an active wire are colorized in the Cumulative Stack.
Note
Remember that wire is instance-based. Only the field or object you have located in the stack is traced for changes, as opposed to all instances for that field or type.
List lines of source based on the amount of CPU time each required.
Trax highlights each line of source that executed during the last run, making it easy to differentiate which lines executed from those which did not. This is different from Stack Trax, which highlight just those lines executed for the selected call. Trax are cumulative, highlighting every line that fired at any point during the run.
Trax Summary
Locate the most time intensive or noisy methods using the summary. Select a method and the SubTracker will show all time-intensive calls in that method. Then select a method in the SubTracker or click the “bullet” in the Code Editor to continue drilling down.
Cumulative Stack Trax Mode
When Trax are visible, the Cumulative Stack is divided into sections, each containing all of the calls leading up to a call to the selected method. This helps isolate the “reason” for each call.
Use the Trax Mode arrows to navigate between call instances.
List the objects which exist as of a given line of source.
This rather straight-forward listview would not be a big deal, except for one thing—it updates as you click in the Cumulative Stack. That means you can assess total object footprint as of any call—and that should lead to some pretty incredible optimization opportunities.
Searching LiveObjects Metadata
Notice the total memory usage at the bottom of the list. This statistic is actually searchable in the Search Sentence control at the top of the Cumulative Stack. You can then filter the stack to show only those calls which were in play when when memory usage was say greater than 1MB. The possibilities for LiveObjects based metadata searching from the stack are both enticing and limitless.
Origins
Find the line of source where an object was instantiated.
Often when you see a high object count, the first question is: “Who” is creating all these objects. This little listview breaks out the exact line of source responsible for the instantiation of a given object type. Just click the object type in LiveObjects, then click a line in Origins: the source is then displayed in the code editor.
Note: Parentheses are shown only for constructors.
List the objects which have been garbage collected (or were eligible for collection) as of a given line of source.
As you move through the stack, a certain amount of collection eligibility should occur, based of course on the implementation. The biggest benefit here—instantly spot bloat.
Bloat will also appear in the LiveObjects window, though slightly masked as good objects mix with objects intended for collection.
One thing is for sure, if you select the last line of the stack and the Barge is empty, your application never allowed a single object to be garbage collected!
Origins
Find the line of source where an object was instantiated, even after it has been garbage collected!
Of course, if you go back to that line, then you can step through and watch it get created again.
Note: Parens are shown only on constructors.
Manage main, source and test projects.
In order to support the effortless creation of tests, a default test project can be set. Any tests created in the Test Bench are then automatically added to this project.
It is common for TDD to require multiple test projects. The Projector makes it easy to create new test projects and to set them as the default.
Build Strip
When multiple projects are in play, build order is the best indicator of correct dependencies. The strip also supports single-shot build-on-click so you can check the compilation of a project without including it in dependencies or checking build in the Solution Configuration. (Projects not set to build are not compiled by the CV engine.)
Project Editor
New Project Icon
MRU Icon
Type Count Graph
Reflects the number of types in a project.
These count ranges can be edited by the developer. Custom range tables can also be created per project type.
Quickly select old solutions or create new ones.
New Solution Icon
Create a new solution.
MRU Icon
Displays a popup of the most recently selected solutions.
Solution Editor
Configure the solution in the workspace
Set Source Folder for solution.
Select which projects will build.
Set Output Type per project.
Set Output Path per project.
Change Output filename for each project.
These capabilites overlap with the Projector. Here the main purpose is to get an overview of the settings for all of the projects.
Here we step thru a simple development cycle, showing how the CV engine supports test-driven development.

