Introduction
'Mixed content' files, as I name them, have become popular in development. Examples of them include HTML, XML, ASPX … What they all have in common is that their content is made of different kinds of content: text, tags, scripts, etc. You could even consider comma-separated files as mixed content made of values, column delimiters and row delimiters.
With the growing popularity of those kind of files comes the need to parse them. Be it to create an editor with syntax highlighting, or an engine to execute them.
Recently, I wanted to try creating a code generation engine that would operate on ASPX-like template files. A classical state machine approach seemed not that hard, but had one important backdraw: it's difficult to maintain when new features have to be added to the template language.
I attempted to write a component that would be able to parse mixed content files without the need to write a state machine specific to that kind of file or content. As a result, most parts of the parsing algorithm will be reusable.
State Machine Approach
Let's first take a look at the classical state machine approach.
Suppose I want to parse an ASP(X)-like file, for instance:
<html>
<head><title><%= document.Title %></title></head>
<body>
<h1>Welcome <%= person.Name %>.</h1>
<body>
</html>
If I want to parse this file so that I can generate write statements to write such a file, I could write a state machine that looks like the following:
StringBuilder buffer = new StringBuilder();
string bufferString = String.Empty;
bool inSource = true;
bool inExpression = false;
foreach (char c in source)
{
buffer.Append(c);
bufferString = buffer.ToString();
if (inSource)
{
if (bufferString.EndsWith("<%="))
{
bufferString = bufferString.Replace("\r\n", "\\r\\n");
bufferString = bufferString.Replace("\"", "<a>\\\</a>"");
WriteLiteral(bufferString.Substring(0,
bufferString.Length - 3));
buffer = new StringBuilder();
inSource = false;
inExpression = true;
}
}
else if (inExpression)
{
if (bufferString.EndsWith("%>"))
{
bufferString = bufferString.Replace("\"", "<a>\\\</a>"");
WriteExpression(bufferString.Substring(0,
bufferString.Length - 2));
buffer = new StringBuilder();
inSource = true;
inExpression = false;
}
}
}
// Buffer might not be empty:
if (inSource)
{
bufferString = buffer.ToString();
bufferString = bufferString.Replace("\r\n", "\\r\\n");
bufferString = bufferString.Replace("\"", "<a>\\\</a>"");
WriteLiteral(bufferString.Substring(0,
bufferString.Length - 3));
}
else if (inExpression)
{
bufferString = bufferString.Replace("\"", "<a>\\\</a>"");
WriteExpression(bufferString.Substring(0,
bufferString.Length - 2));
}
With the right implementation of the WriteLiteral and WriteExpression methods, the output could be:
writer.Write("<html>\r\n<head><title>");
writer.Write(document.Title);
writer.Write("</title></head>\r\n<body>\r\n<h1>Welcome ");
writer.Write(person.Name);
writer.Write(".</h1>\r\n<body>\r\n</html>\");
It is quite some amount of code that will increase steadily with each new supported feature (scripts, directive (think of the '<%@Page...%>' directive in ASP.NET), #include element, support for comments,...).
In addition, the code is hard to maintain. It contains lots of references to the delimiter strings, their length, and contains quite some duplicate code.
Admitted, some issues in the above code could be enhanced. For instance, the duplicate code could be eliminated easily. But let's take a look at a whole different approach.
Matching with Regular Expressions
Regular expressions are an extremely powerful technique to search for patterns in strings.
With regular expressions, you can for instance match directive tags as: "<%@" eventually followed by white spaces, followed by a word, followed by 0 or more attributes with a value, and ended with "%>", and that's exactly the kind of matches we need.
If you are not acquainted with regular expressions, consider learning them if you are interested in parsing algorithms. I like the e-book "Regular Expressions with .NET" from Dan Appleman (available at Amazon) of which I only had to read 10 pages and look at the appendix to have all information I need.
With regular expressions, we can match directives, scripts, expressions, etc. So we have our solution: we just write some regular expressions and that's it !
Unfortunately no. The regular expression matching for scripts, will match all "<%" and "%>" pairs. It will do so, whether or not those pairs appear inside comments for instance. Therefore, even if we use regular expressions, we need some kind of state machine to detect whether or not the matches are to be considered.
Combining regular expressions with state machine-like code is the way Microsoft wrote the ASPX parser. Microsoft's parser is implemented by the System.Web.UI.TemplateParser class in System.Web.dll.
Based on the idea that a mixed content file contains blocks of different kinds of content that could eventually be nested, I implemented an algorithm that will iteratively match only selected content types to discover new content types using regular expressions.
Iterative Matching Algorithm
Consider the earlier ASP(X) example file. Suppose I also started the file with a @Page directive followed by a comment block, and included a script in the file. I could then represent the file symbolically as:
dcccbbbxxbbbxxbbbsssbb
Meaning: a directive(d), some characters forming the comment (c), some characters forming the literal body text (b), some characters forming an expression (x), again some body characters, an expression, body, then some characters making a script (s), and finally again some body.
As for now, we know we have mixed content in this file, but for the computer, it is only one large string of characters. We will now identify the file content in a few iterations:
First Iteration
In the first iteration, we look for comments. As we will see, the order in which matches are performed is important. We first look for comments, so we can later ignore any scripts, expressions, etc. appearing in comments.
To search for comments, we could use the following regular expression (remember, comments are whatever is written started by "<%--" and ended by "--%>"):
<%----%>(\w*\r?\n)?
(Remember to use double backslashes when copying this in C#.)
The ".*?" means anything (the dot), zero or more times (the *), but as few times as possible (the question mark), which will match the first occurrence of the end tag (--%>). For the dot to really mean anything, including line breaks, you need to provide the option SingleLine with the regular expression.
I also included "(\w*\r?\n)?" which will match all whitespaces (spaces or tabs) including the next newline, 0 or 1 time. That way I also match the newline if the comment is the last thing on the line.
When applying this regular expression, it will allow us to identify those parts that are comments. And I will mark them as comments:
dcccbbbxxbbbxxbbbsssbb
(I've bolded and striked through the parts identified.)
Second Iteration
In the second iteration, we will look for directives (those special tags starting with "<%@" and ending with "%>" such as the Page directive). We will however, and that is important, only search for scripts within the unidentified parts (so in the parts "d" and "bbbxxbbbxxbbbsssbb").
(<%@\s*(?<elementName>\w+)
(\s+(?<name>\w+)=(?<quote>["']?)(?<value>[^"']*)\k<quote>)
*\s*%>(\w*\r?\n)?)+
(I wrote the regular expression on 3 lines to ease printing, but you should write it as one single line.)
This regular expression is somehow more complicated, but thanks to the named groups "elementName", "name" and "value", it will be a piece of cake to identify the name of the directive, its attributes and their values.
After applying this regular expression, the result will be that the first part will be identified as a directive:
dcccbbbxxbbbxxbbbsssbb
Third Iteration
In the third iteration, we will look for scripts. Again, we will only look in the still unidentified parts, in this case only the part "bbbxxbbbxxbbbsssbb".
We can use the following regular expression:
<%(?![@=])(?<body>.*?)%>(\w*\r?\n)?
This will match "<%", not followed by any of the characters @ or =, followed by the script body (".*?": anything 0 or more times but as few times as possible), followed by "%>" and eventually spaces and a newline.
Again, for the dot to match also newlines, you need to provide the SingleLine option to the regular expression.
The result of matching this regular expression to the unidentified parts of the document is:
dcccbbbxxbbbxxbbbsssbb
Fourth and Last Iteration
In this last iteration, we will look for expressions (between "<%=" and "%>").
The regular expression to use is:
<%=(?<body>.*?)%>
And the result:
dcccbbbxxbbbxxbbbsssbb
Mixed Content Parser Classes
To support this algorithm, I have made a few classes. The MixedContentFile class represents the entire file. The ContentPart class represents one part of the file.
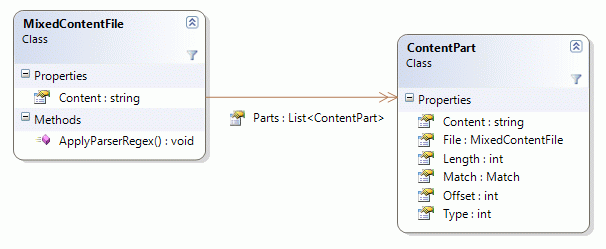
When I create an instance of the MixedContentFile class, I provide it with the whole content of the file. The MixedContentFile constructor will then create one initial ContentPart instance representing the whole content of the file. If I would ask the file for its content Parts, I would obtain one instance matching the whole content.
I could represent this as:
ContentPart("dcccbbbxxbbbxxbbbsssbb", 0)
This initial content part is of type 0.
Using the ApplyParserRegex method of MixedContentFile, telling it to search all parts of type 0, to make the matching types type 1, and passing it the regular expression to match comments, we would see the file is now made of three parts:
ContentPart("d", 0)
ContentPart("ccc", 1)
ContentPart("bbbxxbbbxxbbbsssbb", 0)
In addition, to each content part we can ask the text in the original file content that corresponds to this part, and I can access the Match object that resulted from applying the regular expression, and in which I could search for named group matches (think of identifying the name, attributes and their values of a directive).
The ApplyParserRegex method is the core of the algorithm. Each time the method is called, the passed regular expression is used to find matches in those parts that have a given typeToSearch, and creates new ContentParts for the matches found. The implementation is:
public void ApplyParserRegex(int typeToSearch, int typeToSearchFor,
Regex expressionToSearchFor)
{
List<ContentPart> result = new List<ContentPart>();
foreach (ContentPart section in this.parts)
{
if (section.Type == typeToSearch)
{
int pos = 0;
foreach (Match match in
expressionToSearchFor.Matches(section.Content))
{
if (pos < match.Index)
{
result.Add(new ContentPart(
section.File,
section.Type,
section.Offset + pos,
match.Index - pos,
section.Match));
}
result.Add(new ContentPart(
section.File,
typeToSearchFor,
section.Offset + match.Index,
match.Length,
match));
pos = match.Index + match.Length;
}
if (pos < section.Length)
{
result.Add(new ContentPart(
section.File,
section.Type,
section.Offset + pos,
section.Length - pos,
section.Match));
}
}
else
{
result.Add(section);
}
}
this.parts = result;
}
Thanks to this method and the classes MixedContentFile and ContentPart, parsing ASP-like files has become a piece of cake. Given the regular expressions described earlier in this article, the whole parsing method looks like this:
static MixedContentFile Parse(string content)
{
MixedContentFile file = new MixedContentFile(content, (int)CT.Body);
file.ApplyParserRegex((int)CT.Body, (int)CT.Comment, RxComment);
file.ApplyParserRegex((int)CT.Body, (int)CT.Directive, RxDir);
file.ApplyParserRegex((int)CT.Body, (int)CR.Script, RxScript);
file.ApplyParserRegex((int)CT.Body, (int)CT.Expr, RxExpr);
return file;
}
The returned file object can now be interpreted easily with code as the following:
foreach (ContentPart part in file.Parts)
{
if (part.Type == (int)ContentTypes.Body)
{
}
else if (part.Type == (int)ContentTypes.Comment)
{
}
else if (part.Type == (int)ContentTypes.Directive)
{
}
else if (part.Type == (int)ContentTypes.Expression)
{
}
else if (part.Type == (int)ContentTypes.Script)
{
}
}
A sample application can be downloaded. There are a few demo ASP(X) files included which you can use to test the demo application (by passing the file as commandline parameter to the demo application).
History
- 21st October, 2007: Initial post

