Figure 9
Introduction
XML document performs well if it is relatively small (less than 10-20 MB). DOM loads content into memory and does validation and so on… but what to do with large documents?
Bigger documents use more memory and will consume more resources and performance will suffer significantly. Tool like XML Spy will try to load it into memory and try to validate the document and after all will … hang and run out of memory. (Files tested were over 250 MB). Other XML parsers will just crash silently.
Background
You are probably having a similar issue, otherwise you would not read this.
Here is a simple solution to get the nodes of interest or all nodes from a large-huge XML document without any performance hit (well - small one) and almost no memory or CPU hits.
This is what we do, we index our nodes of interest in memory or in this example into another indexing document (*.xml.idx) and write output nodes into another document (*.xml.sorted). We can now use indexes for fast access to any node of interest. It is up to you to generate conditions and selection methods.
This is a very general example of processing Invoices for customers. The test file was over 420MB and it took on an average 40-50 seconds to process it while writing another document with all nodes of interest. The processing time will be based on your processor and amount of memory on your box.
Key elements: FileStream, XMLReader.ReadSubtree and Regex.
Using the Code
How to:
Get source code and compile project. It was build with Visual Studio 2005 but will work in Visual Studio 2003 and Visual Studio 2008.
Create an XML document with <INVOICE ID=”123”…..> elements in it. See Fig. 6 for an example. a. If you have your own large XML document you want to play with, then type node of interest into “Node to Index on” box and specify value you want to get. In my case, I am interested in INVOICE ID so my condition will be evaluated to "//./@ID" – Current Element ID attribute. Pick your own for this test with your document.

Figure 1
Click on Index XML File to get a copy of your large XML document (Fig 2). It will be copied into directory where your Debug folder is or into the application folder depending on how you run this. Well you know it….
Figure 2
private void MakeCopy() {
string curDir = Application.StartupPath + "/";
FileInfo fi = new FileInfo(filePath);
wokingCopy = curDir + (Guid.NewGuid()) + "_" + fi.Name;
this.Text = "File size is:" + fi.Length/1000000 + " - MB";
File.Copy(filePath, wokingCopy, true);
xmlIndexFile = wokingCopy + ".idx";
this.Text += " Copied to:" + curDir;
using (StreamWriter f = File.CreateText(xmlIndexFile)) {
f.Close();
}
sw = new StreamWriter(xmlIndexFile, true, Encoding.UTF8);
}
After copying file to the new directory, the file size will be shown in Form Text field (Figure 3).
Figure 3
Start parsing process and write to *.idx and *.sorted files.
Use Regex to find if there is a match in line.
using (FileStream fs = new FileStream(wokingCopy, FileMode.Open, FileAccess.Read))
using (StreamReader sr = new StreamReader(wokingCopy, Encoding.UTF8)) {
string parseText = txtNode.Text.Trim();
Regex rx = new Regex(@"<" + parseText, RegexOptions.Compiled | RegexOptions.IgnoreCase);
int pos = 0;
int startIndex = 0;
int lastPositio = 0;
do {
string line = sr.ReadLine();
pos += Encoding.UTF8.GetByteCount(line) + 2;
MatchCollection m = rx.Matches(line);
foreach (Match mt in m) {
startIndex = lastPositio + mt.Index;
ValidateXPathCondition(fs, startIndex);
}
lastPositio = pos;
} while (!sr.EndOfStream);
sr.Close();
sw.Close();
fs.Close();
}
WriteSortedDocument();
At the end, your processing time in seconds will be displayed in Form Text (Figure 4):
Figure 4
This is how you read the stream and store information:
private void WriteSortedDocument() {
using(FileStream fs = new FileStream(wokingCopy, FileMode.Open, FileAccess.Read))
using (StreamWriter wr = new StreamWriter(wokingCopy + ".sorted", false)) {
wr.WriteLine("<?xml version=\"1.0\" encoding=\"UTF-8\"?>");
wr.WriteLine("<" + txtNode.Text.Trim().ToUpper() + "S>");
foreach (int key in indexList.Keys) {
fs.Seek(indexList[key], SeekOrigin.Begin);
using (XmlReader reader = XmlReader.Create(fs)) {
reader.MoveToContent();
XmlDocument d = new XmlDocument();
d.Load(reader.ReadSubtree());
wr.WriteLine(d.InnerXml);
wr.Flush();
reader.Close();
}
}
fs.Close();
wr.WriteLine("</" + txtNode.Text.Trim().ToUpper() + "S>");
wr.Flush();
wr.Close();
}
}
private void SaveMatchedIndex(string value, int startIndex) {
sw.WriteLine(value + "\t" + startIndex);
sw.Flush();
indexList.Add(Int32.Parse(value), startIndex);
}
New files generated:
Figure 5
Original XML File snippet:
Figure 6
Part of index file *.xml.idx:
Figure 7
Part of sorted *.sorted XML file: File was sorted by Invoice ID.
Figure 8
Test your indexes.
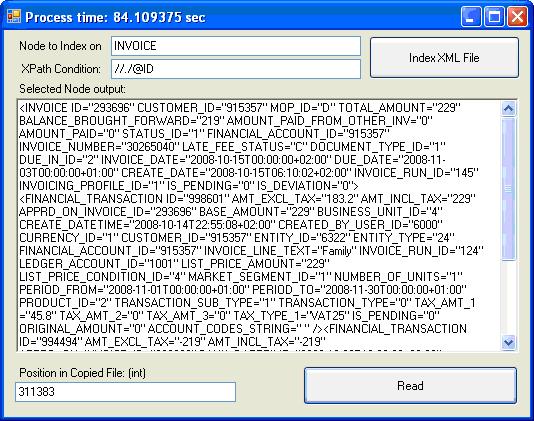
Go to *.xml.idx file and pick any index (this is the second tab) and type this value into position in copied file. The node of interest will be displayed immediately.
Click on Read button to Test Index Position 311383: It will return the selected node. See Figure 9 at the top of this article.
Points of Interest
If you have any comments or questions, please email me.
There is another great project http://vtd-xml.sourceforge.net/ to index large XML documents, but it has its own cons and pros.
History
- Created on 14th November, 2008

